0532
Evaluation of Data Augmentation Methods for Autonomous Segmentation of Placental Volume for Detecting Viral Complications1Medical Physics, University of Wisconsin at Madison, Madison, WI, United States, 2Biomedical Engineering, University of Wisconsin at Madison, Madison, WI, United States, 3Radiology, University of Wisconsin at Madison, Madison, WI, United States
Synopsis
Quantitative investigation of placental volumes can be used for characterization of Zika virus (ZIKV) infection, which causes several complications for developing fetuses. To provide more rapidly available image segmentation for analysis, efforts are being made to produce Convolutional Neural Networks (CNN) for autonomous segmentation of placental volume images. We investigated a number of data augmentation techniques for training machine learning models to determine which methods may be most suited for further development of ZIKV-quantifying placental segmentation models. We found rotational and reflective data augmentation to produce the greatest improvement in machine-segmentated Dice Coefficient comparisons.
Introduction
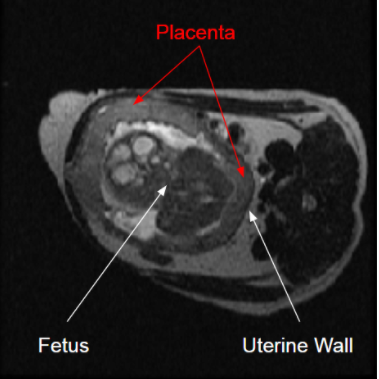
Fetal MRI provides crucial insight into the development of a fetus due to MR’s superior soft tissue contrast without use of ionizing energy. Of particular interest is the placenta, which can serve as a transmission port of, and via DCE, a biomarker for, Zika virus (ZIKV) infection1. Quantifying longitudinal development of placenta with non-invasive imaging has proven difficult2 due to time requirements, as well as the placenta having variable attachment points, variable shape, and low image contrast features (Fig. 1).To measure accurate, repeatable placental volumes, we developed machine learning approaches using data augmentation techniques to generate autonomous segmentations. Given the low data availability of fetal imaging studies, we propose augmenting datasets with geometrically-transformed copies to simulate additional data. We demonstrate improved segmentation model accuracy using these augmentation methods in non-human primates (NHP) models. This can be used to accelerate decision-making processes in further investigations.Methods
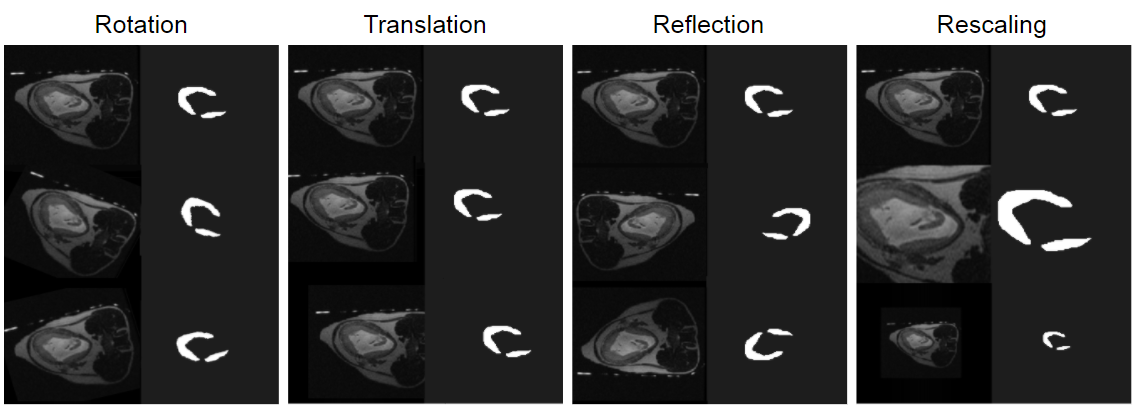
Data Processing:T2- weighted SSFSE (SSTSE, SSH-TSE) MR scans of six pregnant Rhesus Macaques (3 healthy, 3 ZIKV-infected) were acquired at multiple gestational ages on a 3.0T scanner (Discovery MR750 GE Healthcare). As later work is intended for use in quantifying ZIKV biomarkers, the model needs to be trained to recognize both healthy placenta and ZIKV-infected placenta. Three-dimensional placental volumes of each case were manually segmented3 yielding 450 image slices across 13 different scans. Augmented datasets were constructed utilizing various methods of data augmentation: rotation, translation, reflection, and rescaling (Fig. 2). Five datasets were constructed: one of the original scans, one augmented via rotation, one via translation, and so forth for each method. All four augmented datasets were three times larger than the initial dataset, containing all the original scans plus two different variants of transformation each.
Augmentation Methods:
Rotational augmentation was meant to simulate different orientations of relevant pixels in the scan. Rotational augmentation was accomplished by rotating each scan by a randomly-chosen angle about the z-axis. The angle was selected from a Gaussian distribution with mean of 0° and standard deviation of 30°. We kept the range of rotation narrow to avoid overlap with the reflection set.
Similarly, reflective augmentation intended to simulate more drastically different orientations by mirroring each case over the physical x- or y-axes of the magnet.
Augmentation via translation intended to simulate differently-placed areas of interest, not centered in the field of view (FOV). Translational augmentation was done by shifting each case between -1/8 and 1/8 of the FOV along the x- and y-axes, again via a random number generator. Limits on translation range of motion prevented the placental volume from moving ‘out of frame’ relative to the original images.
Augmentation via rescaling intended to simulate a greater range of sizes in targeted areas. Rescaling was executed by scaling each case up to 500x500 pixels and down to 150x150, then cropping or padding back to the original 256x256 dimensions.
Network Architecture:
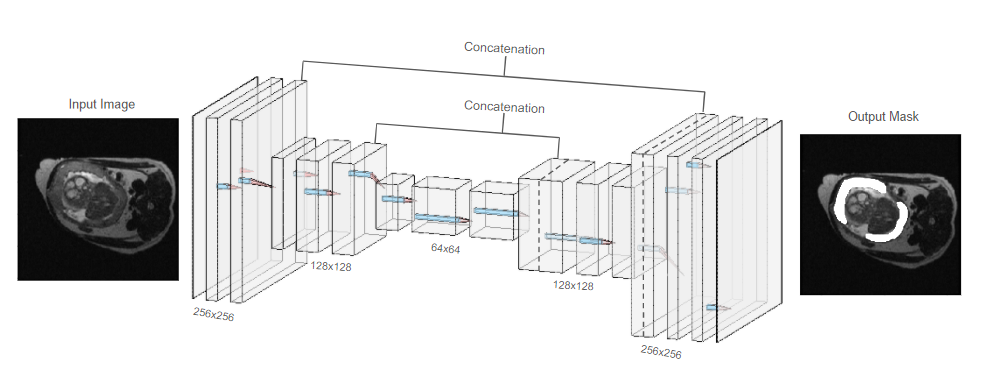
With a UNet-styled4 Convolutional Neural Network (CNN), we used repeated convolution-deconvolution layer pairs to produce binary masks of placental scans (Fig. 3). As its loss function, the model attempted to maximize Dice Coefficients (DC) between given manual segmentations and machine-derived segmentations. The model was constructed using the Keras toolbox for Python5.
Training and Evaluation:
Data was asymmetrically split on a per case basis, grouping 380 images into a training set, and the remaining 70 images into a validation set. Augmentation was applied after this split. For each augmentation method, a separate CNN was trained over 100 epochs to produce segmentations of placenta from the initial images. For comparison, one CNN was trained without augmentation.
Results
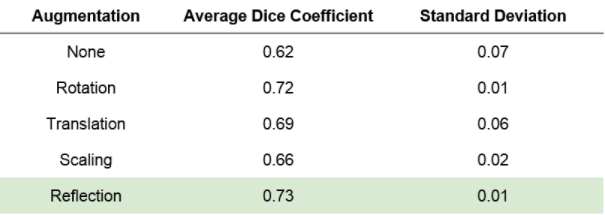
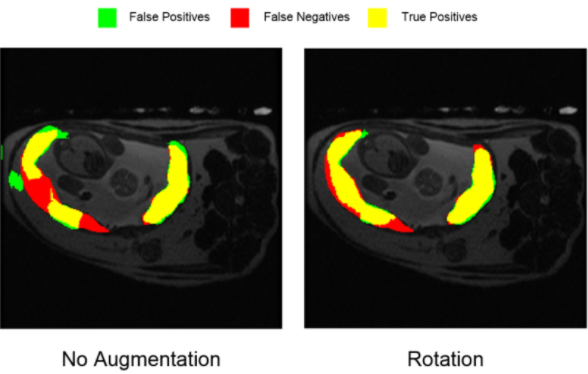
The model trained without augmentation produced segmentations with a mean DC of 0.62±0.07 relative to manual segmentations. Augmented sets with rotation, translation, reflection, and rescaling showed validation DC’s of 0.72±0.01, 0.69±0.06, 0.73±0.01, and 0.66±0.02, respectively (Fig. 4). These augmentation techniques all showed improvement over the unaugmented dataset, with rotation and reflection techniques showing the most improvement. Analysis of positively- and negatively-segmented pixels attributes this increase in DC to an increase in true positives and decrease in false negatives, rather than gross over- or under- segmentation (Fig. 5).Discussion
All forms of data augmentation improved the segmentation model in terms of comparative DC. Rotation and reflection showed the greatest increase, indicating that similar augmentation methodologies may prove most successful in implementing a full-scale autonomous placenta segmentation model. One challenge in machine learning is insufficient data volume, which was both a drawback of, and the inspiration for this work. Overall DC’s were low, but in this data-limited comparative study, we concern ourselves more with relative improvements than overall accuracy. Investigating the use of multiple augmentation techniques at once, or implementing multiple tissue contrasts, presents a promising avenue for further work.Conclusion
Rotated, translated, reflected, and rescaled augmentation all improved the Dice Coefficients of placental automatic segmentation, with rotation and reflection showing the greatest improvement. In future work, these analyses, as well as transfer learning of the models developed here, may be used to guide and accelerate the decision-making process for more sophisticated autonomous segmentation.Acknowledgements
We acknowledge GE Healthcare and the University of Wisconsin - Madison ML4MI Program for research support, with further support and data provided by NIH grant U01-HD087216.References
[1] Hirsch, A.J., Roberts, V.H.J., Grigsby, P.L. et al. Zika virus infection in pregnant rhesus macaques causes placental dysfunction and immunopathology. Nat Commun 9, 263 (2018). https://doi.org/10.1038/s41467-017-02499-9
[2] Wang G, Zuluaga MA, Pratt R, Aertsen M, Doel T, Klusmann M, David AL, Deprest J, Vercauteren T, Ourselin S. Slic-Seg: A minimally interactive segmentation of the placenta from sparse and motion-corrupted fetal MRI in multiple views. Med Image Anal. 2016 Dec;34:137-147. doi: 10.1016/j.media.2016.04.009. Epub 2016 May 3. PMID: 27179367; PMCID: PMC5052128.
[3] Paul A. Yushkevich, Joseph Piven, Heather Cody Hazlett, Rachel Gimpel Smith, Sean Ho, James C. Gee, and Guido Gerig. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. Neuroimage. 2006 Jul 1; 31(3):1116-28. doi:10.1016/j.neuroimage.2006.01.015
[4] Ronneberger O, Fischer P, and Brox T, “U-net: Convolutional networks for biomedical image segmentation.” International Conference on Medical image computing and computer-assisted intervention, 234–241 (2015).
[5] Chollet, F., & others. (2015). Keras. GitHub. Retrieved from https://github.com/fchollet/keras
[6] MATLAB. (2019). version 9.6.0 (R2019a). Natick, Massachusetts: The MathWorks Inc.
[7] LeNail (2019) NN-SVG Publication-Ready Neural Network Architecture Schematics. Journal of Open Source Software, 4(33), 747, https://doi.org/10.21105/joss.00747
Figures