0447
Improving deep unrolled neural networks for radial cine cardiac image reconstruction using memory-efficient training, Conv-LSTM based network1Stanford University, Stanford, CA, United States, 2GE Healthcare, Menlo Park, CA, United States, 3GE Healthcare, Montreal, QC, Canada, 4GE Healthcare, Munich, Germany
Synopsis
Recently, unrolled neural networks (UNNs) have been shown to improve reconstruction over conventional Parallel Imaging Compressed Sensing (PI-CS) methods for dynamic MR image reconstruction. In this work we propose two methods to improve UNN for Non-Cartesian cardiac cine image reconstruction, namely memory efficient training and Convolutional LSTM based network architecture.The proposed method can significantly improve conventional UNN with higher image quality.
Introduction
Recently, unrolled neural networks (UNNs) have been shown to improve reconstruction over conventional Parallel Imaging Compressed Sensing (PI-CS) methods for Cartesian-based images 1–5. However, there are two limitations of the method for Non-Cartesian dynamic image reconstruction. First, Non-Cartesian reconstruction typically requires complex operations in a single iteration and often takes many iterations to converge, which may be problematic due to limited GPU memory 6. Second, commonly used simple networks based on CNN 1,7 or RNN 2 are insufficient to learn the detailed underlying dynamics of the moving images.In this work, we propose two methods to overcome these limitations. First, we use a memory efficient method for training, also known as gradient checkpointing 8. This can greatly alleviate GPU memory constraints without modifying the network architecture. Second, we propose a novel network architecture based on Convolutional LSTM, which has been demonstrated to be effective for training spatiotemporal data 9. We tested our method for reconstruction of radial cardiac cine imaging on synthetized dataset.
Methods
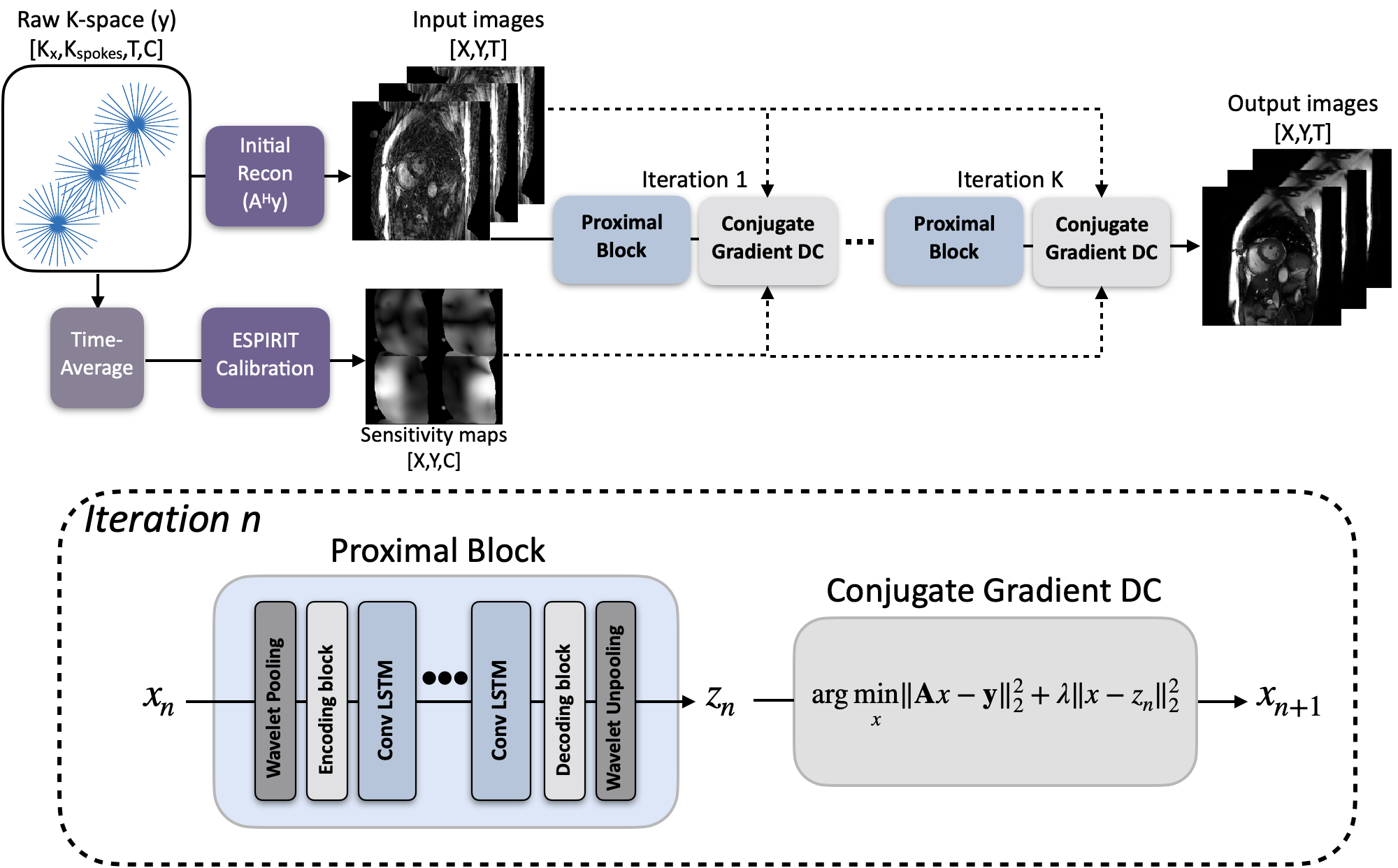
1. UNN architecture for Non-Cartesian dynamic image reconstructionThe UNN (Fig. 1) is designed to solve the following inverse problem
$$b=A(x) +n \ \ \ \ \ [Eq.1] $$
$$arg\min_{x} \parallel{Ax-b}\parallel_2^2+\lambda R(x) \ \ \ \ \ [Eq.2] $$
where A is the non-Cartesian sampling operator involving composition of a non-uniform Fourier transform (NUFFT), undersampling trajectory, sensitivity maps. The problem can be formulated as a non-convex optimization problem (Eq.2) involving a regularizer whose proximal operators can be parameterized by a neural network. We used the MoDL framework 4, which iterates between proximal steps and data-consistency steps with conjugate-gradient descent. For the NUFFT, we use the GPU-based implementation from the SigPy library 10, which is compatible with PyTorch 11. The network is implemented in PyTorch, and training is performed on an NVIDIA 1080 Ti 11GB graphics card.
2. Memory Efficient Training
Recently, a memory-efficient training scheme was introduced for training the UNN 8, In this study, we used the gradient checkpointing scheme 12, mentioned in the literature. This method saves only the intermediate inputs and outputs of every unrolled blocks rather than the whole computational graph during the forward step to save substantial memory. With this, much flexible number of unrolls (up to 50) can be used to train the network, while conventional training method only allow few numbers (up to 5) of unrolls.
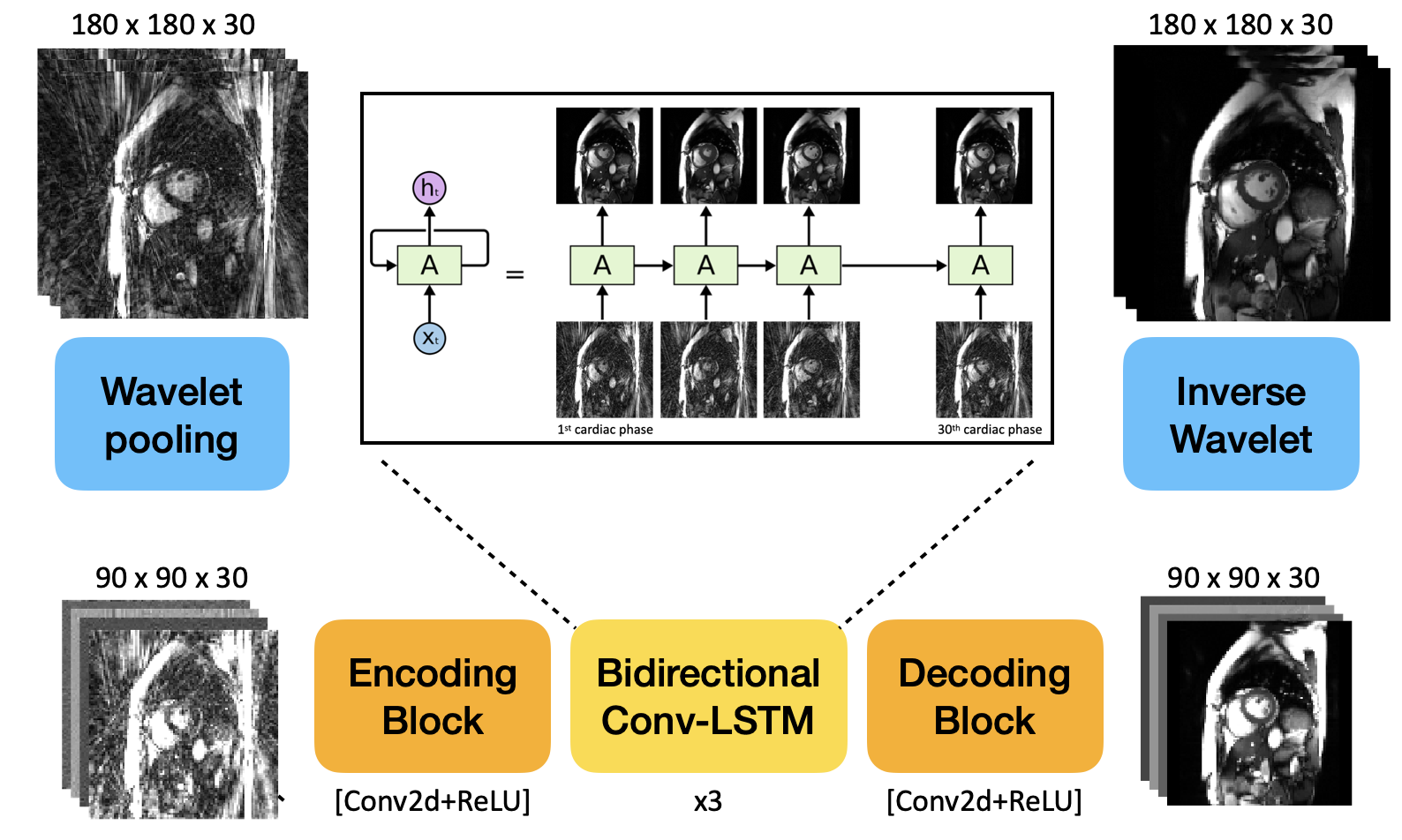
3. Conv-LSTM based Network
For sequence modeling, LSTM is a special RNN structure that has proven stable and powerful for modeling long-range dependencies 13. Conv-LSTM exchanges internal matrix multiplication in LSTM with convolution operations and enables effective modeling of spatiotemporal features 9.
In order to increase the receptive field, we first pool the image by a factor of 2 using first order wavelet decomposition, also known as wavelet pooling 14. Then the resulting image is further encoded by a sequence of Conv2D + ReLU to produce high dimensional features for Conv-LSTM module. Then the feature images are symmetrically decoded and recovered to the original matrix size.
4. Dataset
Fully sampled bSSFP 2D cardiac Cartesian CINE data used in 1 is used to generate synthetic radial cine data. In the dataset, 190 slices were acquired from 15 volunteers at different cardiac views and slice locations on 1.5T and 3.0T GE (Waukesha, WI) scanners.The multi-coil radial k-space measurement was synthetized by multiplying the sensitivity maps and sampling with the tiny-golden angle trajectory 15. The resulting size of the k-space data is 180 × 282 × 30 × 8 (Nreadout × Nspoke × Nphase × Ncoil). Input data is further under-sampled by approximately 18-fold acceleration, resulting in 180 × 15 × 30 × 8. Training was performed on synthetic dataset from 12 subjects and testing was performed on remaining subjects.
5. Evaluation
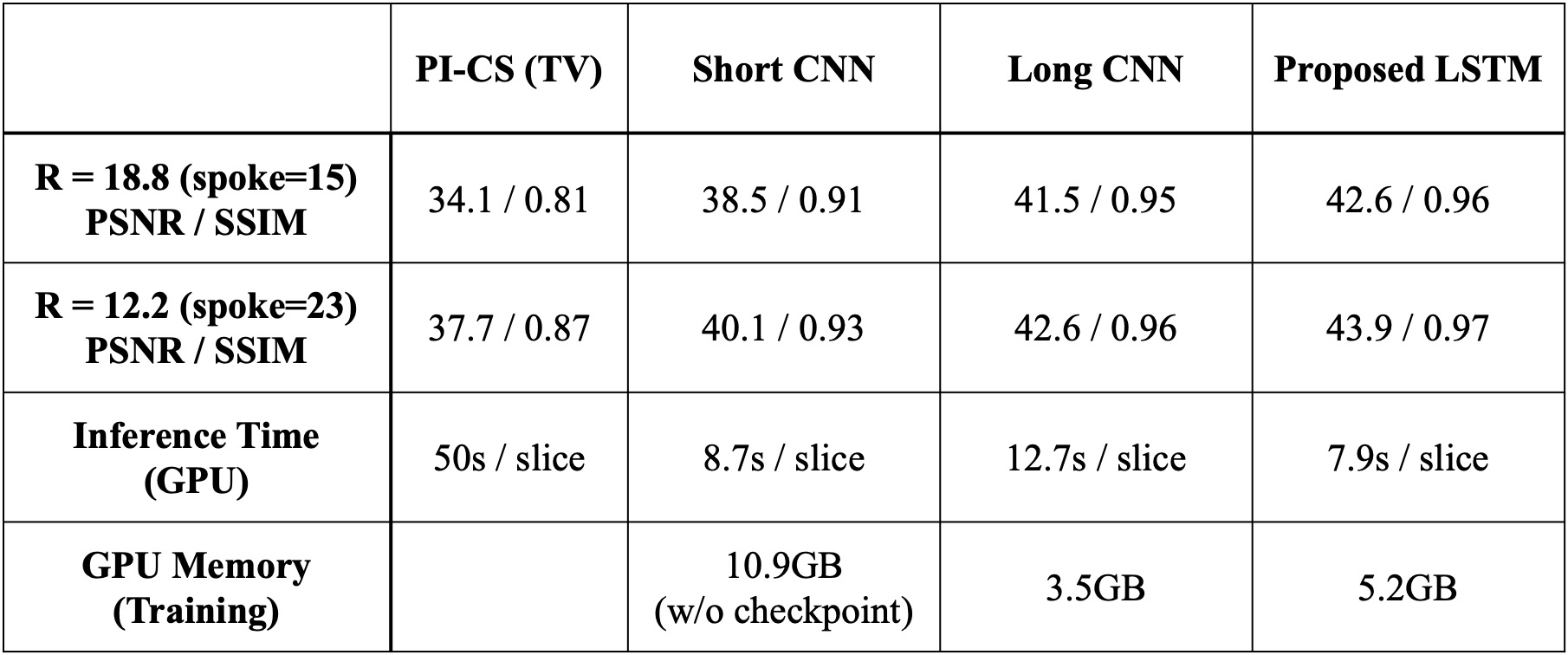
We compare four different methods with respect to standard image quality metrics (PSNR, SSIM). Moreover, the consumption of GPU memory and inference time were compared.
1) PI-CS 15,16: PI-CS method using temporal total-variation regularization.
2) Short CNN: UNN with five iterations containing 2D spatial and 1D temporal residual networks with parameters shown in 1.
3) Long CNN: UNN with ten iterations containing 2D spatial and 1D temporal residual networks.
4) Proposed: UNN with ten iterations containing Conv-LSTM based network.
Results
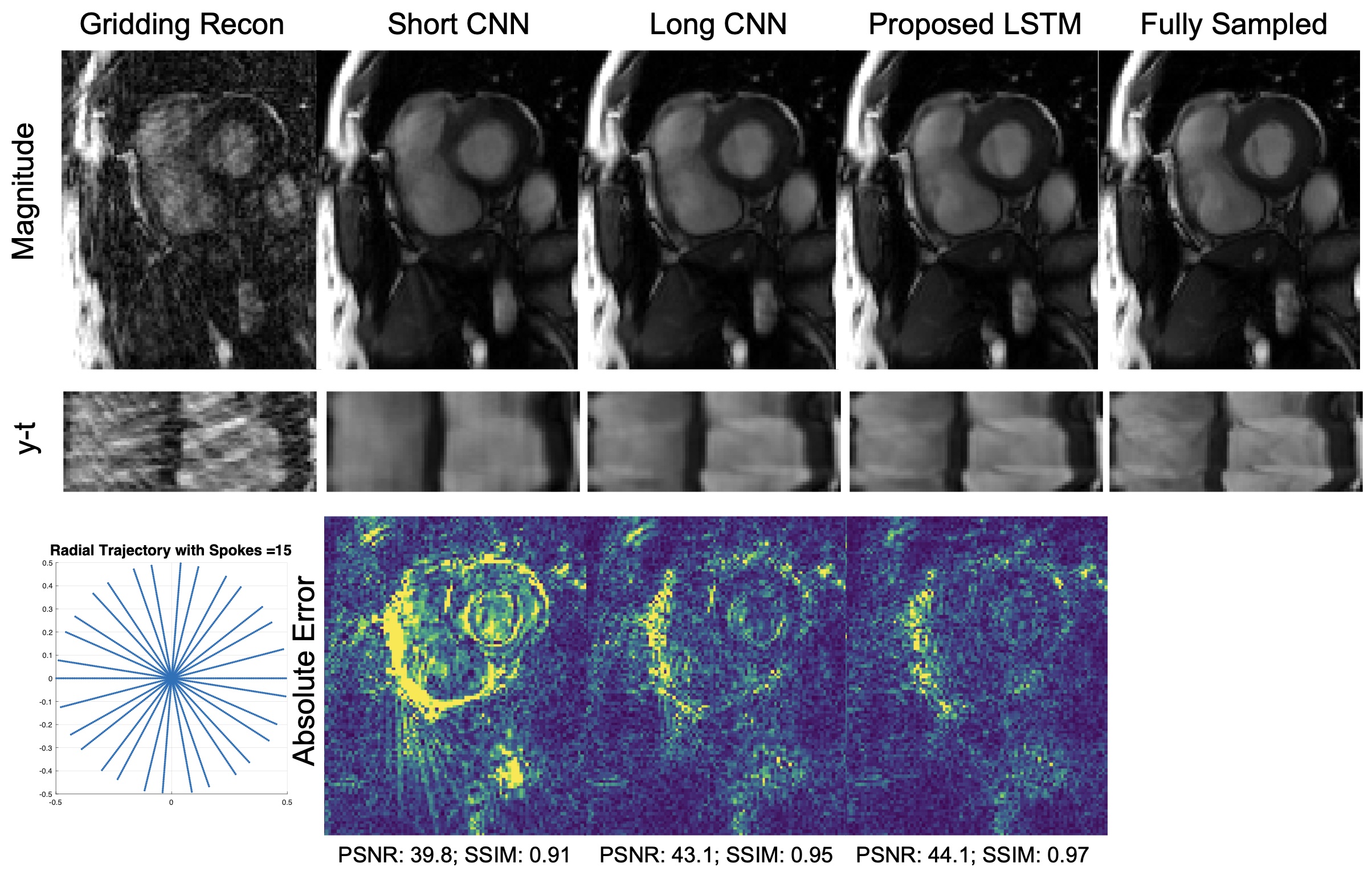
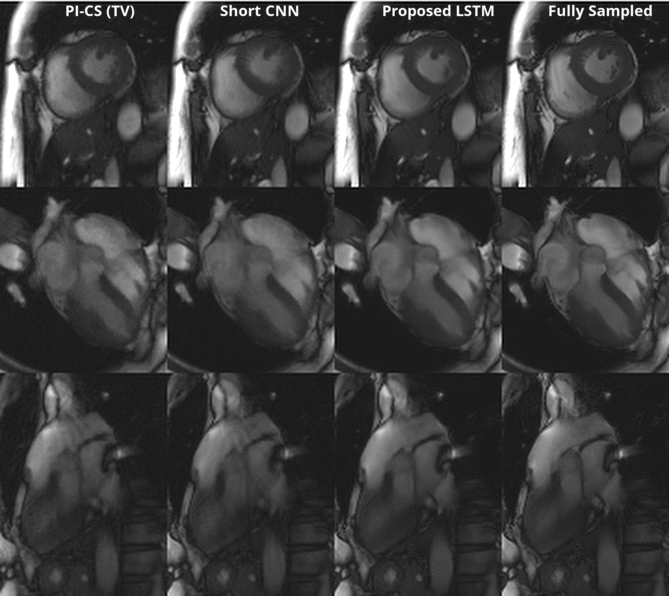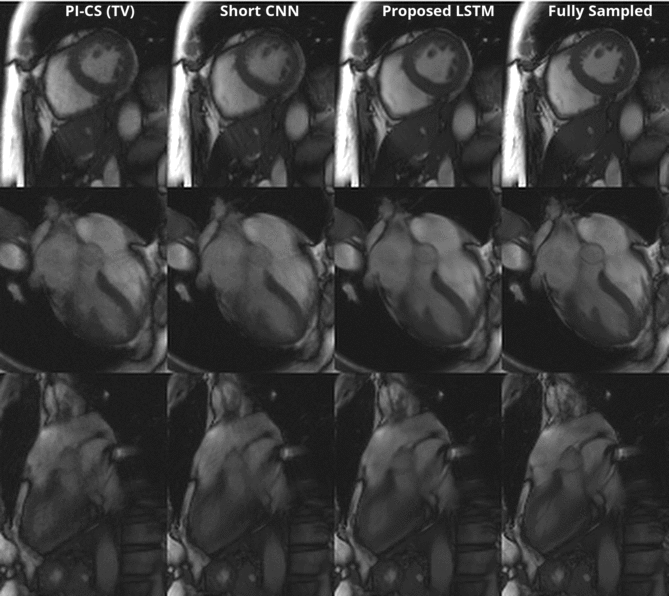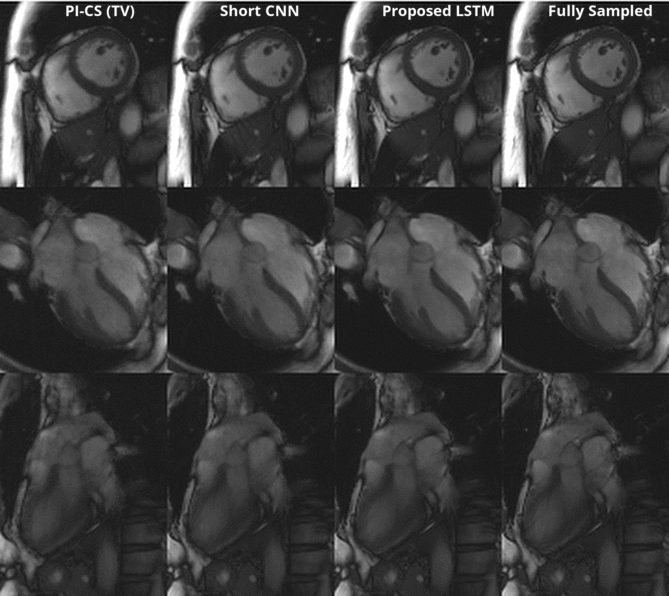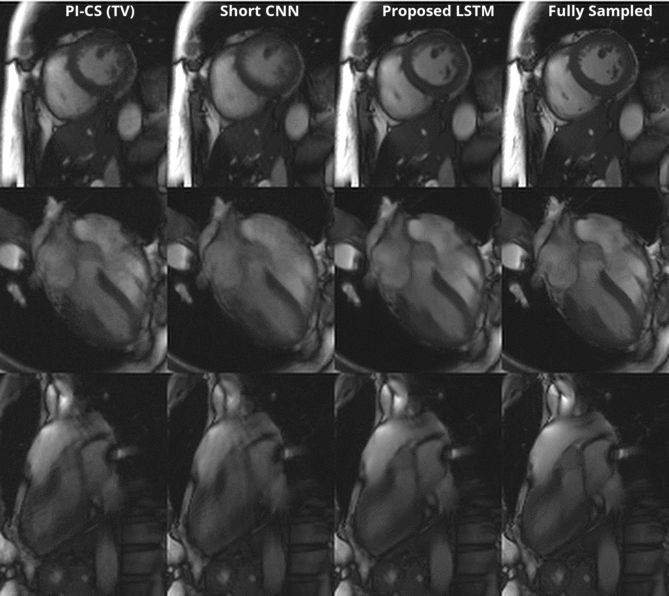
Figure 3 shows a representative comparison of Gridding, Short CNN, Long CNN, and Proposed LSTM. Resulting images from the "proposed LSTM" outperforms with sharper details, higher PSNR, higher SSIM compared to other methods with the same training epochs.Figure 4 shows animation result from PI-CS, Short CNN, and Proposed LSTM for three different cardiac views. Sharper edges and less streaking artifact can be seen on the reconstructed result using the proposed method.
Figure 5 shows the quantitative values for each methods. This shows that our method provides the best reconstruction without elongating inference time or burdening GPU memory.
Conclusions & Discussion
In this work, we presented two methods to improve conventional UNN for Non-Cartesian CINE images. With the addition of these, we were able to reconstruct images with higher image quality. The method will be further evaluated for prospectively sampled cardiac cine images as well.Acknowledgements
NIH R01 EB009690, NIH R01 EB026136, and GE HealthcareReferences
1. Sandino CM, Lai P, Vasanawala SS, Cheng JY. Accelerating cardiac cine MRI using a deep learning‐based ESPIRiT reconstruction. Magn Reson Med. 2020.
2. Qin C, Schlemper J, Caballero J, Price AN, Hajnal J V, Rueckert D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imaging. 2019;38(1):280-290. doi:10.1109/tmi.2018.2863670
3. Qin C, Schlemper J, Duan J, et al. k-t NEXT: Dynamic MR Image Reconstruction Exploiting Spatio-temporal Correlations. arXiv. 2019.
4. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging. 2019;38(2):394-405. doi:10.1109/TMI.2018.2865356
5. Hammernik K, Klatzer T, Kobler E, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018;79(6):3055-3071. doi:10.1002/mrm.26977
6. Ong F, Uecker M, Lustig M. Accelerating Non-Cartesian MRI Reconstruction Convergence Using k-Space Preconditioning. IEEE Trans Med Imaging. 2020;39(5):1646-1654. doi:10.1109/tmi.2019.2954121
7. Hammernik K, Gastao C, Thomas K, Prieto C, Rueckert D. On the Influence of Prior Knowledge in Learning Non-Cartesian 2D CINE Image Reconstruction. In: Proceedings of the ISMRM 28th Annual Meetings. ; 2020:0602.
8. Kellman M, Zhang K, Markley E, et al. Memory-Efficient Learning for Large-Scale Computational Imaging. IEEE Trans Comput Imaging. 2020;6:1403-1414. doi:10.1109/tci.2020.3025735
9. Shi X, Chen Z, Wang H, Yeung D-Y, Wong W-K, Woo W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv Neural Inf Process Syst. 2015;28:802-810.
10. Ong F, Lustig M. SigPy: a python package for high performance iterative reconstruction. In: Proceedings of the ISMRM 27th Annual Meeting, Montreal, Quebec, Canada. Vol 4819. ; 2019.
11. Paszke A, Gross S, Massa F, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv. 2019.
12. Chen T, Xu B, Zhang C, Guestrin C. Training Deep Nets with Sublinear Memory Cost. arXiv. 2016.
13. Sundermeyer M, Schlüter R, Ney H. LSTM neural networks for language modeling. In: Thirteenth Annual Conference of the International Speech Communication Association. ; 2012.
14. Williams T, Li R. Wavelet pooling for convolutional neural networks. In: International Conference on Learning Representations. ; 2018.
15. Wundrak S, Paul J, Ulrici J, et al. Golden ratio sparse MRI using tiny golden angles. Magn Reson Med. 2016;75(6):2372-2378.
16. Feng L, Grimm R, Block KT, et al. Golden‐angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden‐angle radial sampling for fast and flexible dynamic volumetric MRI. Magn Reson Med. 2014;72(3):707-717.
Figures