0441
MR image super-resolution using attention mechanism: transfer textures from external database1College of Health Science and Environmental Engineering, Shenzhen Technology University, Shenzhen, China, 2Laboratory of Biomedical Imaging and Signal Processing, The University of Hong Kong, Hong Kong, China, 3Department of Electrical and Electronic Engineering, The University of Hong Kong, Hong Kong, China
Synopsis
Super-resolution (SR) is useful to reduce scan time and/or enhance MR images for better visual perception. High-resolution reference images may improve super-resolution quality, but most previous studies focused on using references from the same subject. Here, we use an image search module to find similar images from other subjects and use transformer based neural networks to learn and transfer the relevant textures to the output. We demonstrate that this approach can outperform single-image super-resolution, and is feasible to achieve high-quality super-resolution at large factors. As the reference images are not limited within a subject, it potentially has wide applications.
Introduction
Many studies have investigated accelerating MRI by sampling a fraction of k-space and reconstructing intact images through mathematical models, including partial Fourier, parallel imaging, and compressed sensing1. Similarly, super-resolution (SR)2–4 methods can reduce scan time by recovering high-resolution images from low-resolution ones, yet with little or no high-frequency raw data. Moreover, it can be used to enhance existing datasets for better visual perception and spatial analysis2,5. Super-resolution is known to be ill-posed and very challenging at large upscaling factors. A common solution is to constrain the problem by using reference images from the same subject3,4. However, such subject-specific references may not always be available, limiting the extent of its potential applications. In this study, we utilize transformer based neural networks6–8 to enable using reference images from other subjects. Such neural networks can effectively capture the underlying correlations between the input images and the references with attention mechanism, and transfer the relevant textures to the target output.Methods
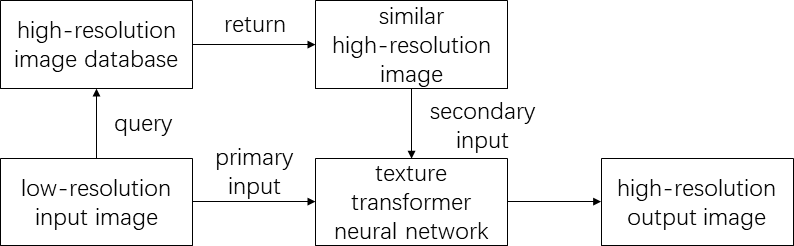
The developed method is based on Texture Transformer Network for Image Super-Resolution (TTSR) 7 . Three major contributions are made to adapt it to MRI and improve the performance: (1) bicubic interpolation is replaced by k-space cropping and zero-padding, (2) instead of random selection, a similar image search module is developed to find better reference images, (3) before cross-scale feature integration, the feature maps are interpolated accordingly to support multiple upscaling factors from 2x2 to 4x4. As illustrated in Figure 1, the input low-resolution image is first sent to the image search module to find high-resolution reference images from a large database. The low-resolution image and the fetched high-resolution reference image are then together fed into the transformer based neural network, where their texture features are extracted and fused with attention to generate high-resolution output images.Model training
TTSR models were first pre-trained on camera photo dataset CUFED5 9, and then on fastMRI10 brain T2-weighted DICOM images. The DICOM folders were split into three subsets for reference image database, model training and testing, respectively. In total, 10700 images were used for training, and 1070 for testing. Images were preprocessed to 160x160 matrix size with 8-bit unsigned integer precision as ground truth. Models were trained for 2x2 and 4x4 upscaling factors at 2x10-6 learning rate for 80 epochs. For comparison, a representative single-image super-resolution method EDSR 11 was trained similarly. Since EDSR did not utilize adversarial loss, we also trained a TTSR model without adversarial loss for fair comparison.
Image search module
Reference database contained 10700 images that were not ever used as training targets. These reference images were vectorized by GIST12 feature extractor at 40x40 matrix size, and the GIST vectors were clustered, and indexed using FAISS13. At search time, the input low-resolution images were also feature extracted to GIST vectors, which were used to query the most similar images in sense of L2 distance.
Evaluation
In addition to the test using 1070 images from fastMRI, real T2-w data were acquired from a healthy volunteer (3T Philips, TR/TE=3000/110ms, FOV=230x230, matrix size=360x360) to examine the generalization ability of the trained TTSR models. PSNR and SSIM were calculated for quantitative measurements.
Results
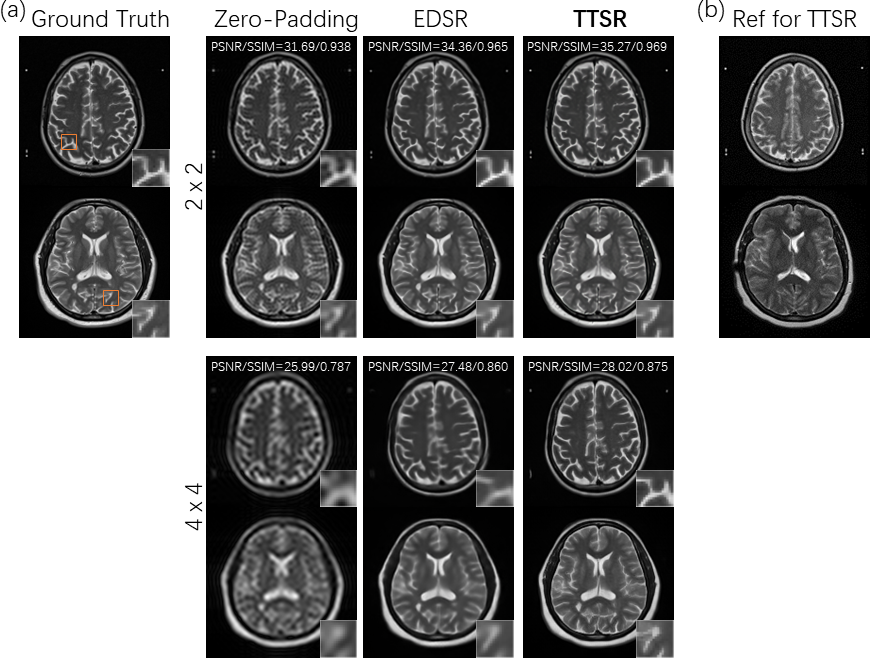
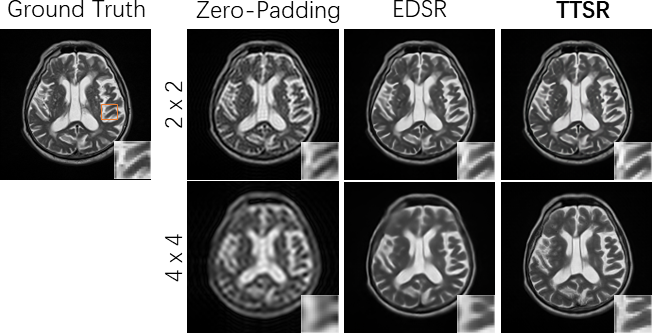
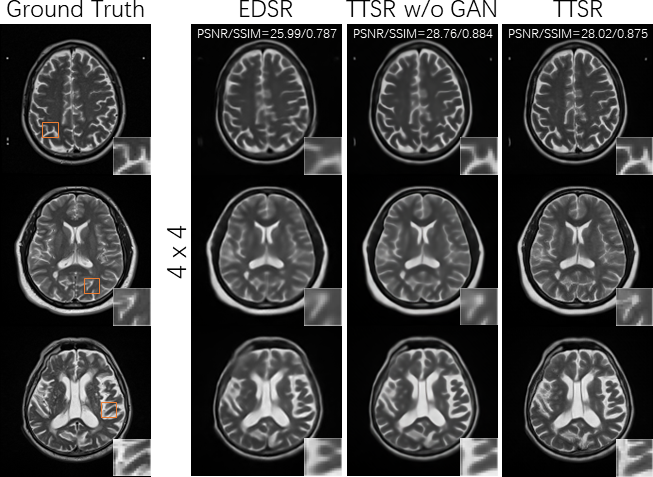
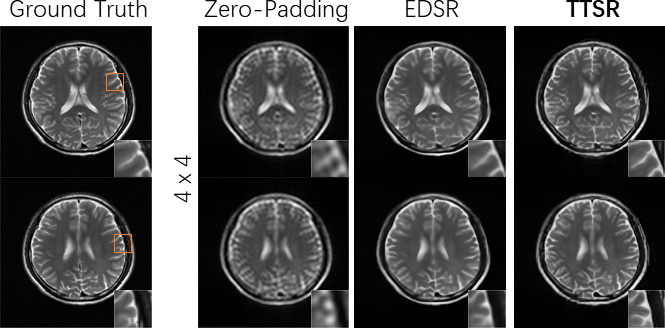
As shown in Figure 2a, the developed TTSR method outperformed the single-image EDSR method visually and quantitatively at both upscaling factors. In Figure 2b, the reference images fetched from the image search module are shown, which visually resembled the input images in Figure 2a. Figure 3 demonstrates the performance of TTSR method on a possibly pathological case from FastMRI. Figure 4 shows that TTSR trained without adversarial loss could lead to even higher PSNR and SSIM. It was visually more blurred than standard TTSR trained with adversarial loss, but still sharper than EDSR, indicating that the overall better performance of TTSR was not due to the difference in loss functions. In Figure 5, results from our acquired data are shown. The findings were largely consistent with previous tests, and no apparent overfitting problems were observed.Discussion and Conclusion
We have demonstrated that it is feasible to achieve high-quality MR image super-resolution at large factors using attention mechanism. With transformer architecture and image search module, the developed method recovers fine details of MR images and outperforms single-image super-resolution without major artifacts. Although the training was done on DICOM images from a single source10, it shows good generalization on our independently acquired k-space data. Because the reference images are not limited to a specific subject, the developed method potentially has a wide range of applications. For simplicity, we used a single image as the reference, yet using multiple references is possible and may further improve the results. Future studies may also explore transferring textures across contrasts.Acknowledgements
No acknowledgement found.References
1. Hamilton J, Franson D, Seiberlich N. Recent advances in parallel imaging for MRI. Prog Nucl Magn Reson Spectrosc. 2017;101:71-95. doi:10.1016/j.pnmrs.2017.04.002
2. Chaudhari AS, Fang Z, Kogan F, et al. Super-resolution musculoskeletal MRI using deep learning. Magn Reson Med. 2018;80(5):2139-2154. doi:https://doi.org/10.1002/mrm.27178
3. Zeng K, Zheng H, Cai C, Yang Y, Zhang K, Chen Z. Simultaneous single- and multi-contrast super-resolution for brain MRI images based on a convolutional neural network. Comput Biol Med. 2018;99:133-141. doi:10.1016/j.compbiomed.2018.06.010
4. Lyu Q, Shan H, Steber C, et al. Multi-Contrast Super-Resolution MRI Through a Progressive Network. IEEE Trans Med Imaging. 2020;39(9):2738-2749. doi:10.1109/TMI.2020.2974858
5. Utility of deep learning super‐resolution in the context of osteoarthritis MRI biomarkers - Chaudhari - 2020 - Journal of Magnetic Resonance Imaging - Wiley Online Library. Accessed December 17, 2020. https://onlinelibrary.wiley.com/doi/abs/10.1002/jmri.26872
6. Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Adv Neural Inf Process Syst. 2017;30:5998–6008.
7. Yang F, Yang H, Fu J, Lu H, Guo B. Learning Texture Transformer Network for Image Super-Resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. ; 2020:5791–5800.
8. Devlin J, Chang M-W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv Prepr ArXiv181004805. Published online 2018.
9. Zhang Z, Wang Z, Lin Z, Qi H. Image Super-Resolution by Neural Texture Transfer. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE; 2019:7974-7983. doi:10.1109/CVPR.2019.00817
10. Zbontar J, Knoll F, Sriram A, et al. fastMRI: An Open Dataset and Benchmarks for Accelerated MRI. ArXiv181108839 Phys Stat. Published online December 11, 2019. Accessed September 27, 2020. http://arxiv.org/abs/1811.08839
11. Lim B, Son S, Kim H, Nah S, Lee KM. Enhanced Deep Residual Networks for Single Image Super-Resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE; 2017:1132-1140. doi:10.1109/CVPRW.2017.151
12. Torralba, Murphy, Freeman, Rubin. Context-based vision system for place and object recognition. In: Proceedings Ninth IEEE International Conference on Computer Vision. ; 2003:273-280 vol.1. doi:10.1109/ICCV.2003.1238354
13. Johnson J, Douze M, Jégou H. Billion-scale similarity search with GPUs. IEEE Trans Big Data. Published online 2019:1-1. doi:10.1109/TBDATA.2019.2921572
Figures