0438
An open dataset for speech production real-time MRI: raw data, synchronized audio, and images1University of Southern California, Los Angeles, CA, United States
Synopsis
We introduce the first-ever public domain real-time MRI raw dataset for the study of human speech production. The dataset consists of raw, multi-receiver-coil MRI data with non-Cartesian, spiral sampling trajectory and reconstructed images derived using a reference reconstruction method along with synchronized audio for 72 subjects performing 32 linguistically motivated speech tasks. This dataset can be used to develop traditional and machine learning / artificial intelligence approaches for dynamic image reconstruction in the context of fast aperiodic motion, which is currently an unsolved problem, as well as for artifact correction, feature extraction, and direct extraction of linguistically relevant biomarkers.
INTRODUCTION
Several examples of recently published MRI data repositories1–5 have demonstrated the value of publicly available, curated datasets to address a multitude of open challenges in research and translation of MRI into clinical and scientific applications: Open raw datasets have been used to validate and refine compressed sensing methods, to train, validate, and benchmark promising recent applications of ideas inspired by artificial intelligence/machine learning, and are valued by commercial vendors to showcase performance and generalizability of reconstruction methods. Despite its recognized impact, on musculoskeletal and brain MRI for instance, there are currently no raw datasets involving the vocal tract.Dynamic imaging of the vocal tract is especially challenging because the fast, aperiodic, and often subtle motion of delicate articulators require methods with high spatiotemporal resolution6. While under-sampling on non-Cartesian trajectories enables the desired resolution, such measurements are hampered by prolonged computation time, low signal-to-noise-ratio, and artifacts due to off-resonance-induced blurring at the air-tissue boundaries of speech articulators.
To fulfill the unmet need and facilitate future research, here we present the first-ever public domain real-time MRI (RT-MRI) raw dataset for the study of human speech production. The present dataset complies with a recommended yet currently nonroutine protocol for speech RT-MRI (see Protocol 2 in Lingala et al.6). In contrast to other open datasets for dynamic, RT-MRI7–11, this dataset consists of raw, multi-receiver-coil MRI data with non-Cartesian, spiral sampling trajectory. The 72 exams in the dataset capture controlled stimuli whose audio is co-recorded and aligned. The dataset allows for retrospective adjustment of temporal resolution12,13 and can be used to devise algorithms that monitor fast aperiodic dynamics of speech articulators at high spatiotemporal resolution while offering simultaneous suppression of noise or artifacts due to sub-Nyquist sampling or susceptibility14.
DESCRIPTION OF THE DATASET
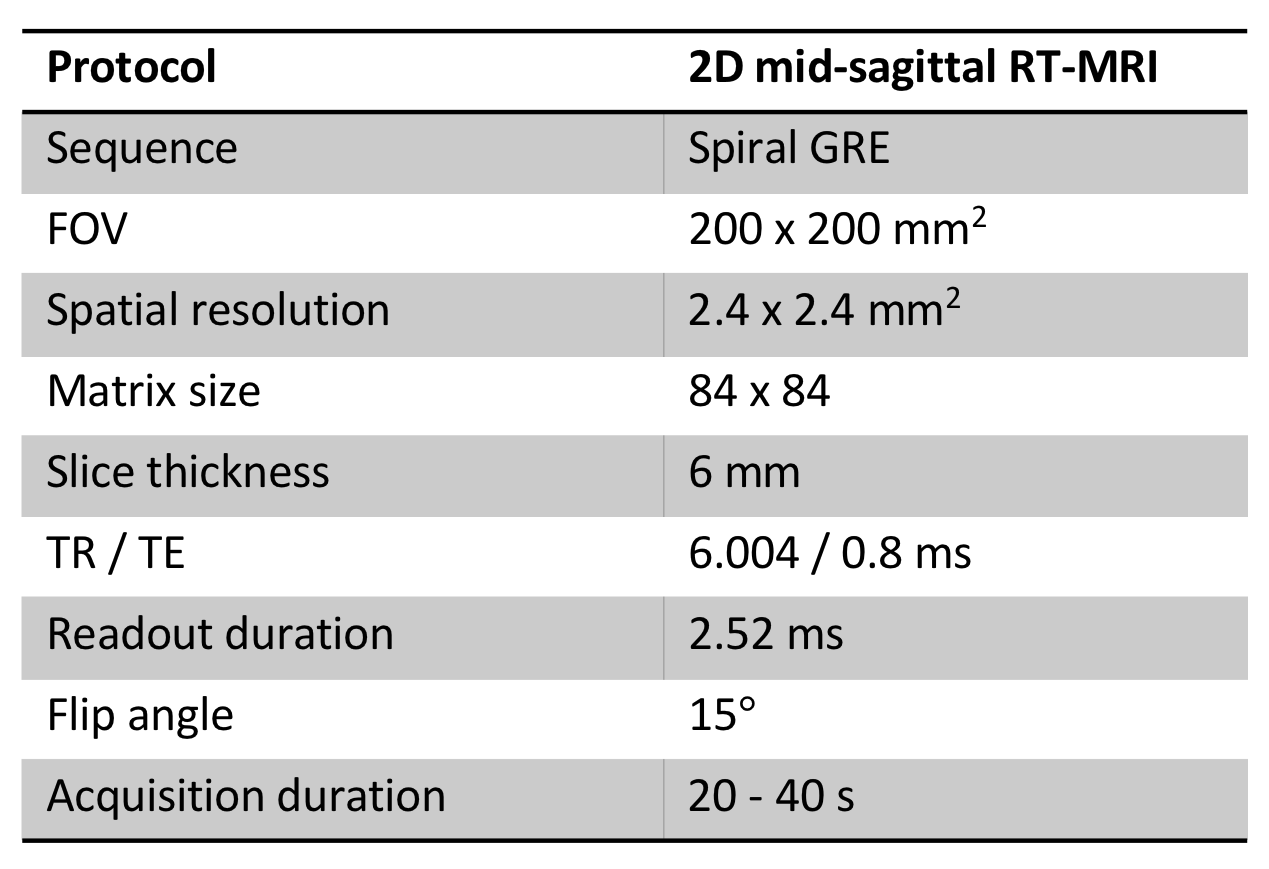
Acquisition DetailsSpeech RT-MRI raw k-space data were collected at the LAC+USC Medical Center between March 1, 2016 and September 30, 2019 from more than 72 healthy subjects. All participants understood the nature of the study, provided written informed consent, and were scanned under a protocol approved by our institutional review board. All data were collected using a commercial 1.5T MRI scanner (Signa Excite, GE Healthcare, Waukesha, WI) with a custom 8‐channel upper airway receiver coil array15. We performed RT-MRI acquisition using a 13-interleaf spiral-out spoiled gradient-echo pulse sequence16 with the bit-reversed interleaved order17. The data acquisition parameters are presented in Table 1. Imaging was performed in the mid-sagittal plane, which was prescribed using a real‐time interactive imaging platform18 (RTHawk, Heart Vista, Los Altos, CA). Within a 45-minute scan, each subject followed experimental stimuli designed by linguists at our institution to efficiently capture dynamic and articulatory aspects of speech production of American English. The stimuli set is comprised of scripted speech, including consonant or vowel production and several reading passages commonly used in speech evaluation, and spontaneous speech such as describing the content and context of photographs presented via a projector-mirror setup16. Consequently, each subject's data contains 32 speech tasks (32 individual scans), each within 20-40 second intervals, depending on the individual’s speaking rate.
Data Records
RT-MRI raw data is provided in the vendor-agnostic MRD format (previously known as ISMRMRD)19,20, which stores k-space MRI measurements, k-space location tables, sampling density compensation weights, and acquisition parameter header. In addition, this dataset includes reconstructed image data for each subject and task, derived from the raw data using a reference reconstruction algorithm15 in HDF5 format as well as synchronized audio files in WAV format, videos in MPEG-4 format, and a metafile in JSON format containing demographic information, speech task information, and overall data quality rankings for each subject. The total duration of the provided videos is approximately 19.2 hours, which is, with a time resolution of 83.3 frames / s, equivalent to more than 5.7 million frames. The size of the entire dataset will be approximately 860 Gb.
Examples
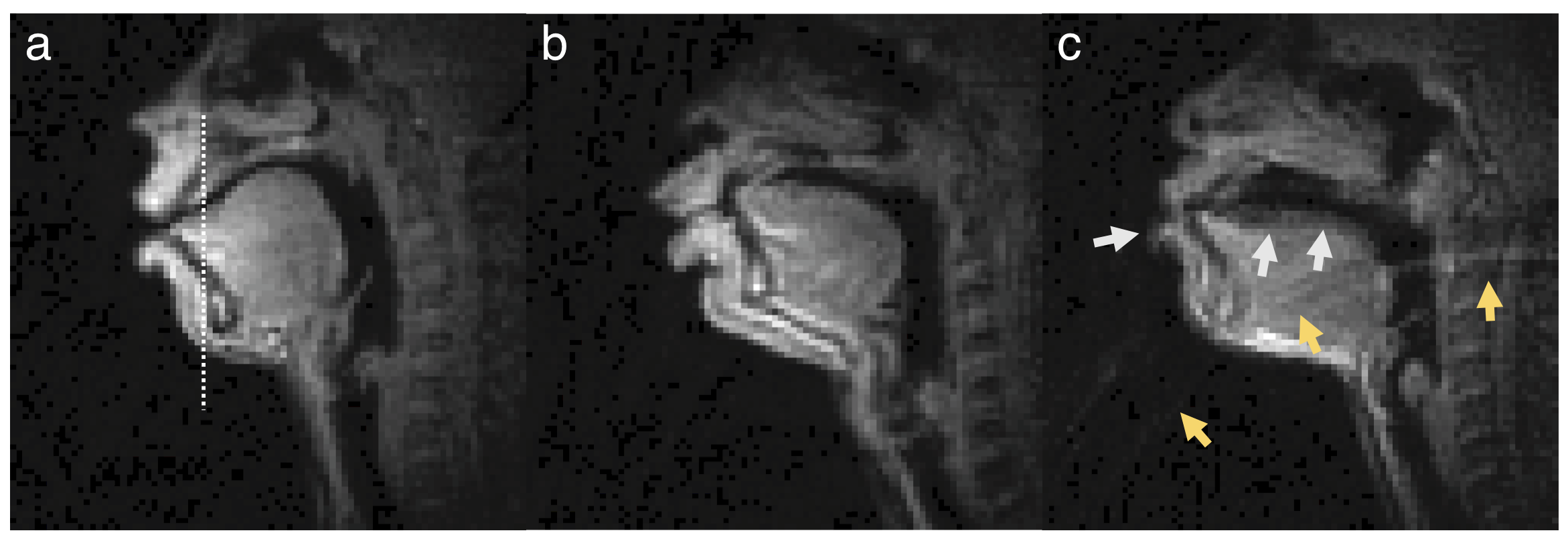
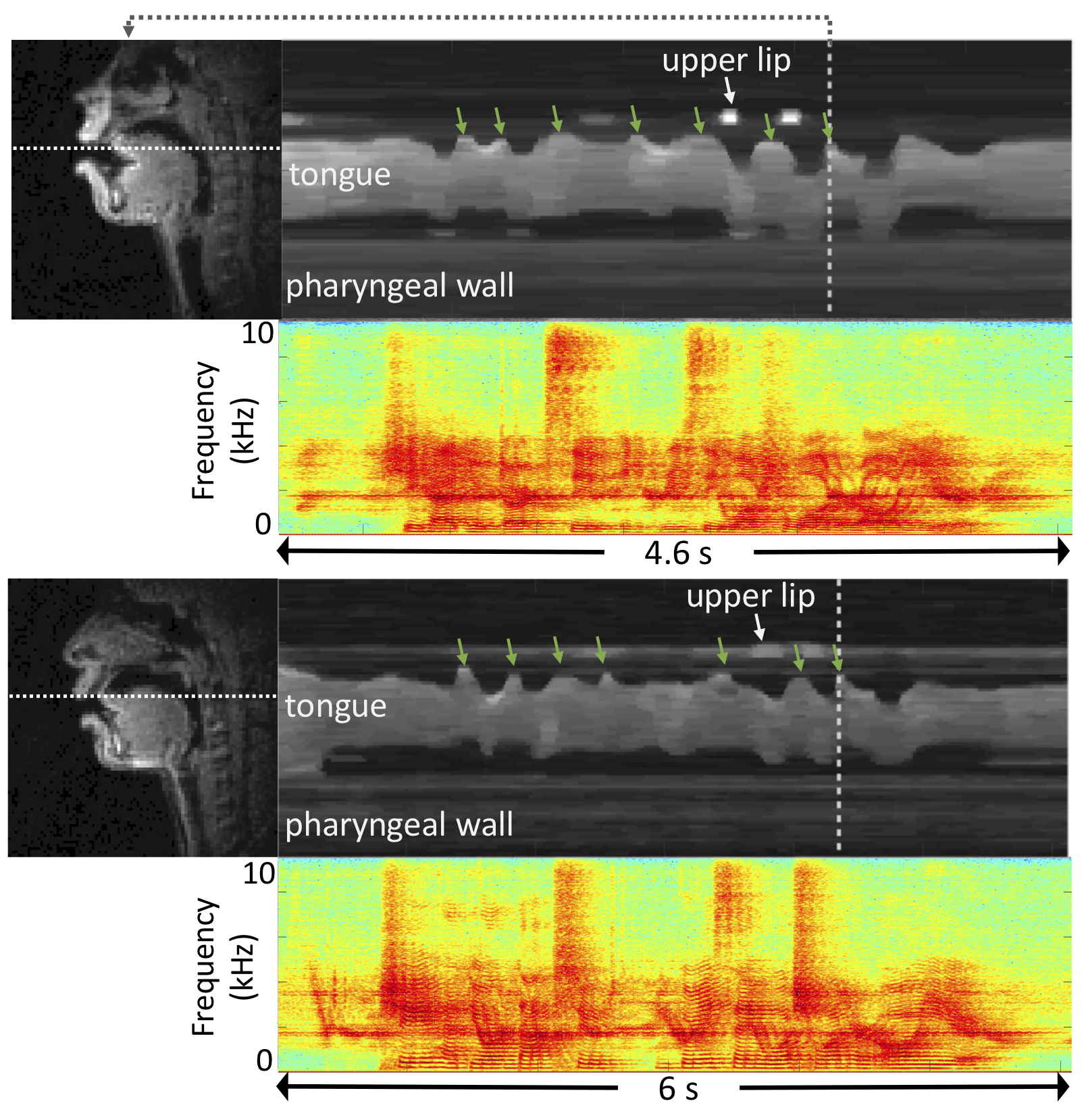
Figure 1 shows representative examples of the data quality from three subjects that are included in this dataset. Figure 2 shows representative examples of the diverse speech stimuli that are included in this dataset. Figure 3 illustrates variability within the same speech stimuli across different speakers.
The dataset is being curated and we seek invaluable feedback from the ISMRM community in curating the dataset. We intend to release the dataset to a public data sharing website (with no access restrictions) along with an associated full paper prior to the 2021 annual meeting.
DISCUSSION
To our best knowledge, the presented dataset is the first-ever public domain RT-MRI raw dataset for speech production study. Speech RT-MRI imaging methods themselves are extremely complex because of several key requirements; very high spatio-temporal resolution and sub-Nyquist sampling due to rapidly moving articulators; artifact correction for time-varying off-resonance created by the dynamic air-space; custom vocal tract MRI receiver coils with high signal-to-noise-ratio efficiency; audio recording and denoising. While reconstructed images have been shared publicly, to-date, there is no publicly available dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. We hope that the availability of this dataset could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically relevant biomarkers.Acknowledgements
This work was supported by NSF Grant 1514544 and NIH Grant R01-DC007124. We acknowledge the Speech Production and Articulation kNowledge (SPAN) group at the University of Southern California for helpful discussions and collaboration. We gratefully acknowledge the contributions of Sajan Goud Lingala, Johannes Töger, Colin Vaz, Tanner Sorensen, Weiyi Chen, Yoonjeong Lee, Miran Oh, Sarah Harper, Louis Goldstein, and Dani Byrd for their contributions to study design, methods development, and data collection.References
1. Marcus DS., Wang TH., Parker J, Csernansky JG. Open access series of imaging studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J Cogn Neurosci. 2007;19:1498–507.
2. Souza R, Lucena O, Garrafa J, Gobbi D, Saluzzi M, Appenzeller S, et al. An open, multi-vendor, multi-field-strength brain MR dataset and analysis of publicly available skull stripping methods agreement. Neuroimage. 2018;170:482–94.
3. Knoll F, Zbontar J, Sriram A, Muckley MJ, Bruno M, Defazio A, et al. fastMRI: A Publicly Available Raw k-Space and DICOM Dataset of Knee Images for Accelerated MR Image Reconstruction Using Machine Learning. Radiol Artif Intell. 2020;2:e190007.
4. Chen C, Liu Y, Schniter P, Tong M, Zareba K, Simonetti O, et al. OCMR (v1.0)--Open-access multi-coil k-space dataset for cardiovascular magnetic resonance imaging. arXiv:200803410. 2020;
5. http://mridata.org/.
6. Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real-time speech MRI. J Magn Reson Imaging. 2016;43:28–44.
7. Töger J, Sorensen T, Somandepalli K, Toutios A, Lingala SG, Narayanan S, et al. Test–retest repeatability of human speech biomarkers from static and real-time dynamic magnetic resonance imaging. J Acoust Soc Am. 2017;141:3323–36.
8. Narayanan S, Toutios A, Ramanarayanan V, Lammert A, Kim J, Lee S, et al. Real-time magnetic resonance imaging and electromagnetic articulography database for speech production research (TC). J Acoust Soc Am. 2014;136:1307–1311.
9. Kim J, Toutios A, Kim Y, Zhu Y, Lee S, Narayanan S, et al. USC-EMO-MRI corpus : An emotional speech production database recorded by real-time magnetic resonance imaging. 10-th Int Semin Speech Prod. 2014;5–8.
10. Sorensen T, Skordilis Z, Toutios A, Kim YC, Zhu Y, Kim J, et al. Database of volumetric and real-time vocal tract MRI for speech science. In: Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH. 2017.
11. Toutios A, Narayanan SS. Advances in real-time magnetic resonance imaging of the vocal tract for speech science and technology research. APSIPA Trans Signal Inf Process. 2016;5:e6.
12. Parikh N, Ream JM, Zhang HC, Block KT, Chandarana H, Rosenkrantz AB. Performance of simultaneous high temporal resolution quantitative perfusion imaging of bladder tumors and conventional multi-phase urography using a novel free-breathing continuously acquired radial compressed-sensing MRI sequence. Magn Reson Imaging. 2016;34:694–8.
13. Cha E, Kim EY, Ye JC. Improved time-resolved MRA using k-space deep learning. In: Machine Learning for Medical Image Reconstruction. 2018. p.47–54.
14. Lim Y, Bliesener Y, Narayanan SS, Nayak KS. Deblurring for spiral real-time MRI using convolutional neural network. Magn Reson Med. 2020;84:3438–3452.
15. Lingala SG, Zhu Y, Kim Y-C, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn Reson Med. 2017;77:112–25.
16. Lingala SG, Toutios A, Toger J, Lim Y, Zhu Y, Kim YC, et al. State-of-the-art MRI protocol for comprehensive assessment of vocal tract structure and function. In: Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH. 2016. p. 475–9.
17. Kerr AB, Pauly JM, Hu BS, Li KC, Hardy CJ, Meyer CH, et al. Real-time interactive MRI on a conventional scanner. Magn Reson Med. 1997;38:355–67.
18. Santos JM, Wright GA, Pauly JM. Flexible real-time magnetic resonance imaging framework. Annu Int Conf IEEE Eng Med Biol - Proc. 2004;26 II:1048–51.
19. Inati SJ, Naegele JD, Zwart NR, Roopchansingh V, Lizak MJ, Hansen DC, et al. ISMRM Raw data format: A proposed standard for MRI raw datasets. Magn Reson Med. 2017;77:411–421.
20. https://ismrmrd.github.io/.
Figures