4548
T2w-FLAIR generation through deep-learning using distortion-free PSF-EPI DWI1Center for Biomedical Imaging Research, Department of Biomedical Engineering, School of Medicine, Tsinghua University, Beijing, China, 2China National Research Center for Neurological Diseases, Beijing Tiantan Hospital, Capital Medical University, Beijing, China, 3Philips Healthcare, Beijing, China, 4MR Clinical Science, Philips Healthcare (Suzhou), Suzhou, China
Synopsis
MRI examinations usually contain multi-contrast images, which may share redundant information. For example, T2w-FLAIR contrast relies on the property of T2 relaxation and water component of the tissue, which also present in T2- and diffusion-weighted images. T2w-FLAIR acquisition is usually lengthy due to the long inversion time. In this study, point-spread-function (PSF) encoded EPI (PSF-EPI) DWI and T2-weighted images were used to generate T2w-FLAIR images by taking the advantages of high-resolution and distortion-free of PSF-EPI. This method has the potential to improve the acquisition efficiency of MRI.
Introduction
MRI is capable of acquiring various contrast images based on the physical properties of the tissue. Therefore, MRI examinations usually contain multi-contrast images, which however can bring the problem of prolonged acquisition time. As such, much work has been done to improve the acquisition efficiency of MRI. Multi-contrast images may share redundant information. For example, T2w-FLAIR contrast 1 relies on property of the T2 relaxation and water component of the tissue, which also present in T2- and diffusion-weighted images. Recently, deep-learning using a neural network has been applied in contrast synthesis. For instance, Nencka et al. 2 proposed to use multiple contrast images, such as T1w, T2w, and diffusion-weighted images, to generate T2w-FLAIR images. However, the DWI images used were acquired using the single-shot EPI technique which suffers from low-resolution and distortion problem. Thus the spatial mismatch among different contrasts introduces errors inevitably. Recently, a fast distortion-free multi-contrast method using point-spread-function (PSF) encoded EPI (PSF-EPI) 3, including T1w, T2w-FLAIR, T2w and diffusion-weighted imaging, was proposed. To further improve the time efficiency, in this study, DWI acquired with PSF-EPI 4,5 were combined with T2W images to generate T2w-FLAIR by taking the advantages of high-resolution and distortion-free of PSF-EPI.Methods
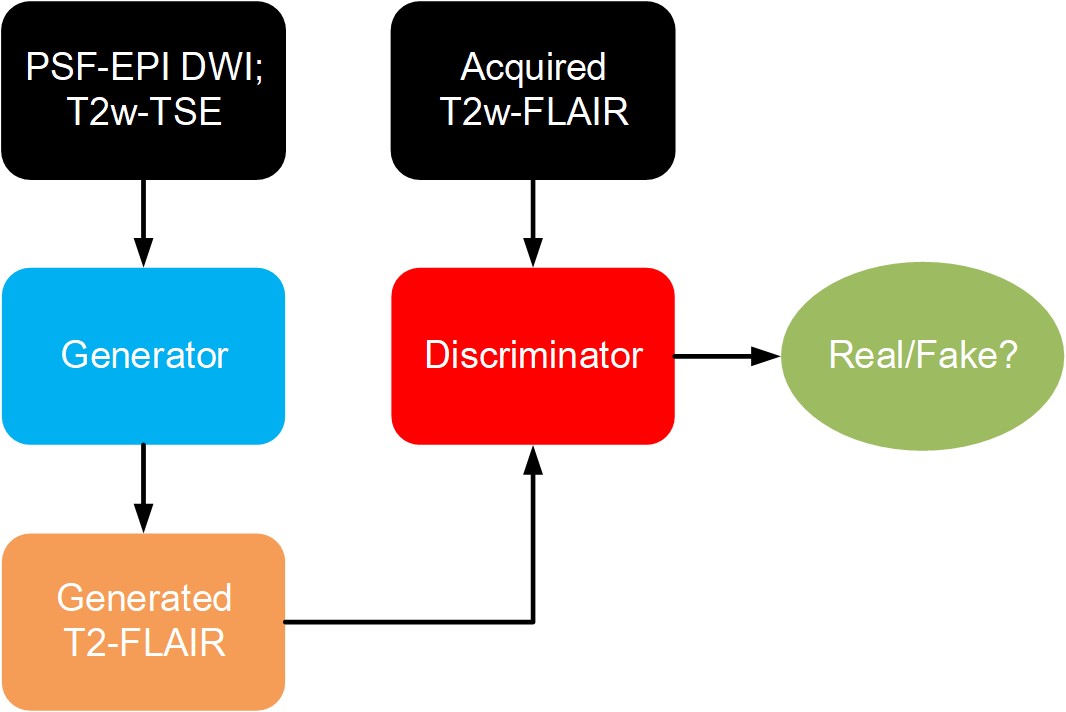
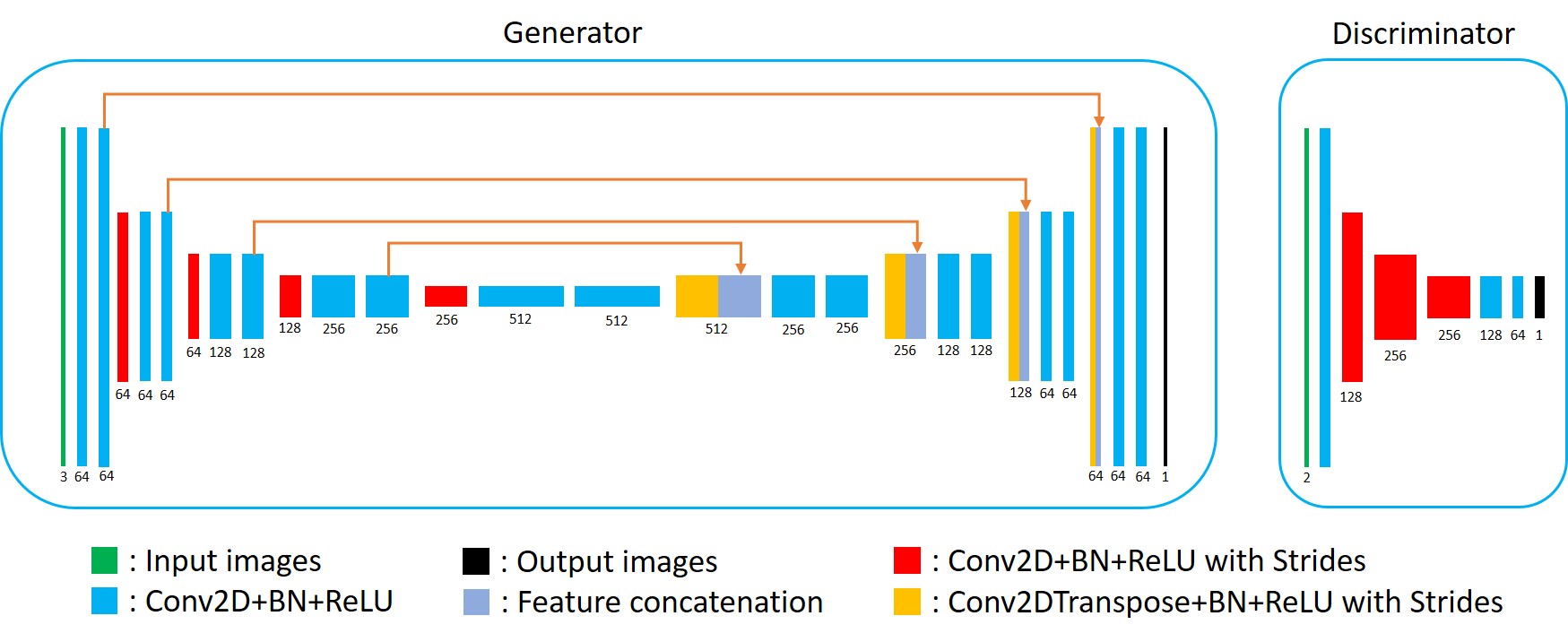
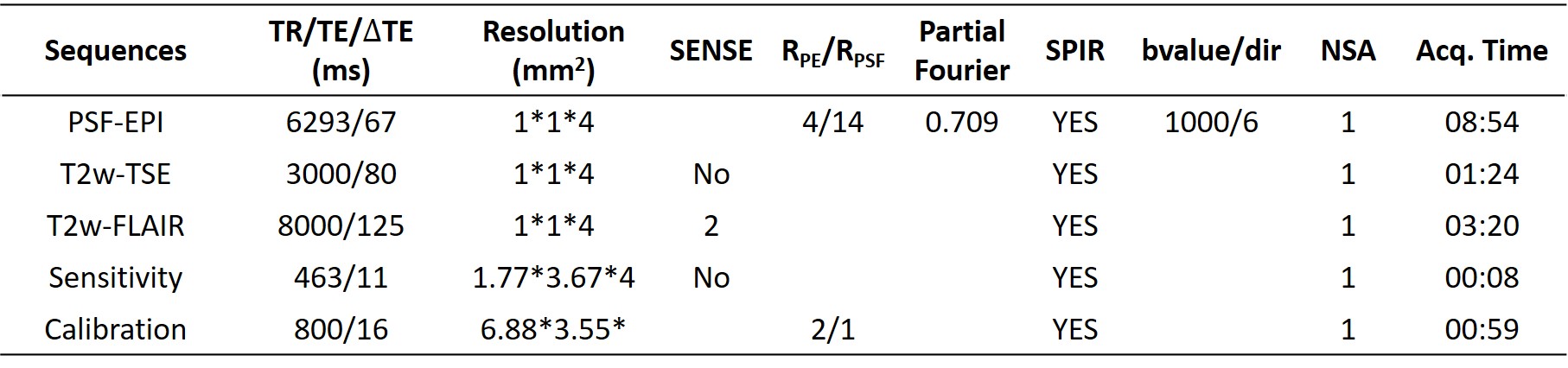
(1) Data acquisition: Detailed data acquisition protocols can be found in Table. 1, in which images of different contrasts were acquired for the brain, including PSF-EPI DWI, T2w-TSE and T2w-FLAIR. PSF-EPI DWI was acquired with 4-fold acceleration along the PE direction and 14-fold acceleration along the PSF encoding direction. Additional sensitivity and calibration data were acquired for the reconstruction of PSF-EPI 5. All images were acquired using FOV = 220×220×100 mm3 with 25 axial slices covering the whole brain. The acquisition matrix size of PSF-EPI is 221×220. The images of T2w-TSE and T2w-FLAIR were interpolated to the same matrix size. Ten healthy volunteers provided with written informed consent were scanned on a Philips 3T scanner (Philips Healthcare, Best, The Netherlands). The mean DWIs (calculated across 6 diffusion directions) along with the b=0 s/mm2 images and T2w-TSE images were used as the input and the T2w-FLAIR images were used as the labels to train the neural network, thus to achieve T2w-FLAIR generation.(2) Network architecture: The overall flowchart of the proposed method is based on conditional generative adversarial network (CGAN) 6, as illustrated in Fig. 1. The mean DWI along with the b=0 s/mm2 and T2w-TSE images were fed into the generator to generate the T2w-FLAIR images, which were paired with the corresponding acquired T2w-FLAIR images and fed into the discriminator. The network architectures of the generator and discriminator are shown in Fig. 2. A 2D U-net 7 was used as the base structure of the generator. The network consisted of 19 convolutional layers, 4 convolutional layers with strides for downsampling, 4 deconvolutional layers with strides for upsampling, and 4 feature contracting paths. The discriminator network consisted of 4 convolutional layers and 4 convolutional layers with strides for downsampling. Batch-normalization (BN) and ReLU were used for each layer. The input layer of the generator consisted of 3 channels (including 1 b = 0 s/mm2 image and 1 mean DWI and 1 T2w-TSE image) and the input of the discriminator consisted of 2 channels (the generated and the acquired T2w-FLAIR images).
(3) Training and evaluation: Images from 7 volunteers were used for training, images from 2 volunteers were used as a validation set, and images from 1 volunteer were used as a test set. Data were augmented through patching with the patch size of 64. Thus the input dimension of the generator network was 64×64×3, and the output dimension was 64×64×1. The input dimension of the discriminator was 64×64×2, and the output dimension was 8×8×1. To verify the importance of DWI, T2w-FLAIR generation without PSF-DWI was also implemented (i.e. only using T2w-TSE, thus the input dimension of the generator consisted of 1 channel). SSIM (Structural Similarity Index) 8 was used to evaluate the accuracy. The network was trained and evaluated using Keras 9 and RMSprop was used as the optimizer.
Results and Discussion
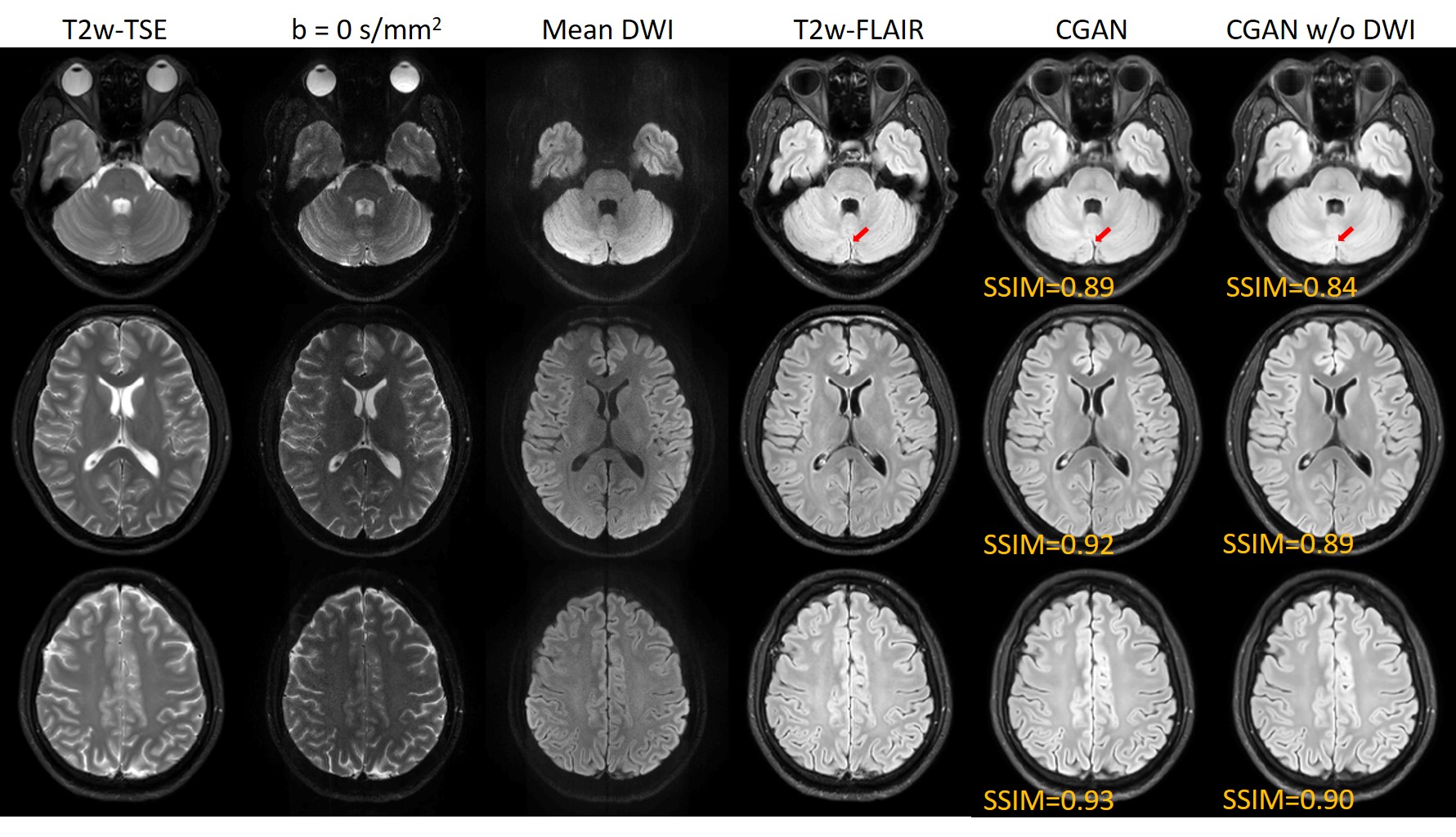
Fig. 3 shows the generated T2w-FLAIR images using the proposed method with or without PSF-DWI (denoted by CGAN and CGAN w/o DWI, respectively). Compared with the acquired T2w-FLAIR, both results show good consistencies in structures and contrasts. However, the T2w-FLAIR generated with PSF-DWI shows higher SSIM values than the results without PSF-DWI. Meanwhile, the former can also keep the detailed structures better than the latter, as in the areas pointed by the red arrowheads. The high-resolution and distortion-free images from PSF-EPI can ensure that the images across different contrasts would not be affected by the spatial mismatch due to the geometry distortion and low-resolution of conventional SS-EPI. Thus these high quality images can help to improve the performances of the proposed method.Conclusion
The proposed deep-learning based method can generate high-quality T2w-FLAIR images with the aids of distortion-free PSF-EPI DWI, thus to improve the time efficiency of MRI. Further systematic clinical studies are warranted to clarify its generalization ability.Acknowledgements
No acknowledgement found.References
1. Hajnal JV, Bryant DJ, Kasuboski L, et al. Use of fluid attenuated inversion recovery (FLAIR) pulse sequences in MRI of the brain. Journal of computer assisted tomography 1992;16:841-841.
2. Nencka AS, Klein A, Koch KM, et al. Build-A-FLAIR: Synthetic T2-FLAIR Contrast Generation through Physics Informed Deep Learning. arXiv preprint arXiv:190104871 2019.
3. Wang Y, Dong Z, Hu Z, et al. Multicontrast Distortion-free MRI Using PSF-EPI. 2019; Montreal.
4. In MH, Posnansky O, Speck O. High-resolution distortion-free diffusion imaging using hybrid spin-warp and echo-planar PSF-encoding approach. NeuroImage 2017;148:20-30.
5. Dong Z, Wang F, Reese TG, et al. Tilted-CAIPI for highly accelerated distortion-free EPI with point spread function (PSF) encoding. Magnetic resonance in medicine 2018.
6. Gauthier J. Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester 2014;2014(5):2.
7. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. 2015. Springer. p 234-241.
8. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 2004;13(4):600-612.
9. Chollet, François. Keras (https://github.com/fchollet/keras). GitHub repository 2015.
Figures