3638
A deep-learning based synthesized T2 weighted imaging with multi-modality information and k-space correction1School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, China, 2High Field Magnetic Resonance Brain Imaging Laboratory of Sichuan, Chengdu, China, 3Key Laboratory for Neuro Information, Ministry of Education, Chengdu, China
Synopsis
T2 weighted image (T2WI) usually takes more time and thus is more vulnerable to motion artifacts. With the recent development of applying deep learning to MR imaging, many neural networks are proposed to synthesize high-quality T2 images from under-sampled T2 or other modalities (such as T1). Here we develop a Simple-ResNet network to synthesize high-quality T2 images based on multi-modality information and followed by a k-space correction module. Results show that our model is very easy to train and the synthesized T2 images can achieve comparable image quality as the fully-sampled T2 images.
Introduction
In clinical routines, T1-weighted image (T1WI) and T2-weighted image (T2WI) are two basic MR sequences for assessing anatomical structures and pathologies, respectively. However, the relatively long acquisition time of T2WI makes the acquired image vulnerable to motion artifacts [1]. To solve the problem, various algorithms have been proposed to reconstruct high-quality image from under-sampled k-space data. Recently deep convolutional neural networks (CNNs) have shown promising capability for reconstruction from under-sampled k-space data [2], [3], [4], [5]. Among them deep-learning based MR synthetic imaging is attracting more attentions, which can “learn” one certain type of image (such as T2WI) from a different modality (such as T1WI or FLAIR). Inspired by Xiang et al. [6], we develop a Simple-ResNet to reconstruct the high-quality T2 images by combining multi-modality images. Simple-ResNet, which is based on ResNet [7], has a lot of pre-connects to learn the initial features learned by the previous convolution layer. In order to reduce the blurring of the image, k-space correction [8] was used to improve the quality of the synthesized T2 image.Methods
To prepare the data of under-sampled T2WI, Fourier transform of the fully sampled T2 image $$$y_{T2}$$$ was applied to obtain the corresponding fully-sampled k-space data $$$f_{T2}$$$. Then a 1/4 center mask (Fig.1) was adopted to get the 1/4 under-sampled k-space data $$$f_{1/4T2}$$$. With the under-sampled k-space data $$$f_{1/4T2}$$$, we can apply zero-filling to the k-space and get the final 1/4 under-sampled T2 image by IFFT. As shown in Fig.2, Simple-ResNet was used to reconstruct the synthesized T2-weighted image. The network takes 2D slices extracted from the 3D volumes of T1WI and 1/4 under-sampled T2WI as input, while the corresponding slices from the fully-sampled T2WI were used as ground truth. Data augmentation of random rotation was also applied. $$$L_{1}$$$ loss function was used.To improve the quality of the synthesized fully-sampled T2 images, k-space correction [8] was added to the model, which use the k-space data of the reconstructed preliminary T2 image to replace the zero-filled part of the original 1/4 under-sample k-space data to obtain the corrected k-space data. Fig.3 shows the block diagram of our proposed method.
Image data from IXI database (see http://brain-development.org/ixi-dataset/ for details) were used for the training. The data of 25 subjects scanned by a Philips 1.5T system in Guy’s Hospital were chosen for experiment. All subjects have paired T1WI and T2WI. We randomly chose 20 subjects for training, and the rest 5 subjects for testing of course. The details of scanner parameters are as follows: T1WI(TE = 9.813ms, Echo time =4.603, Phase Encoding Steps = 192, Echo Train Length = 0, Reconstruction Diameter =240,Flip Angle= 8。); T2WI (TR= 8s, Echo time = 100, Phase Encoding Steps = 187, Echo Train Length = 16, Reconstruction Diameter =240, Flip Angle = 90). We use two steps for image pre-processing, including: 1) rigid registration using SPM software [9]; 2) intensity normalization to the range [0, 1] by dividing the maximal intensity value. The final size of each subject is 256*256*60.
Results
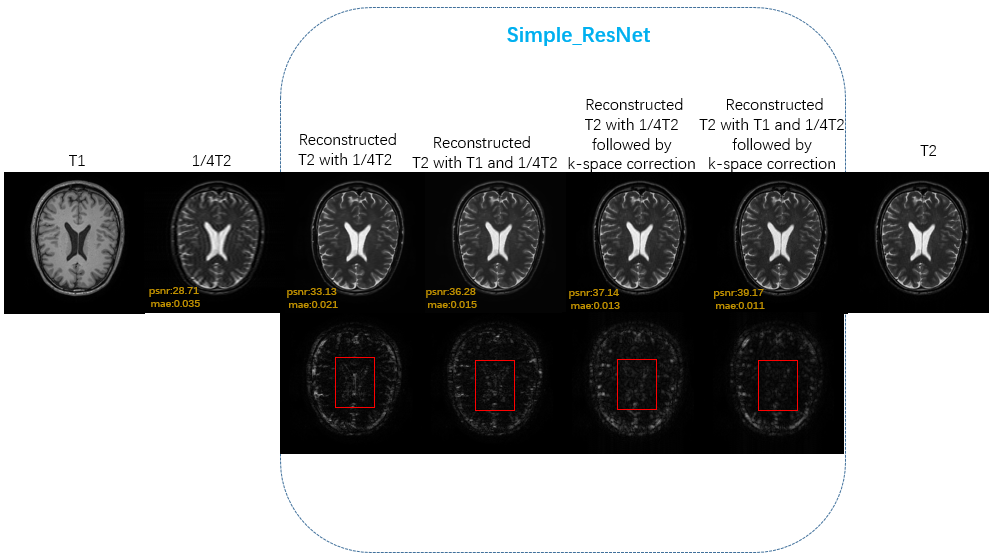
Representative images are shown in Fig.4 for visual inspection. Compared to others, our proposed method, in which the synthesized T2 images are reconstructed with fully-sampled T1 image and 1/4 down-sampled T2 image followed by k-space correction, provides the best image quality by preserving both image contrast and tissue details. We believe that adding a k-space correction following the Simple-ResNet is effective since this can partially retrieve the missing k-space data points due to the simple k-space masking as shown in Fig.1. Table 1 shows that the average PSNR for reconstructed T2 with T1 and 1/4 T2 followed by k-space correction is 39.47dB, comparing to 36.03dB for reconstructed T2 with T1 and 1/4 T2 and 33.58dB for reconstructed T2 with 1/4 T2.Conclusion
A deep-learning based synthesize T2 imaging method was presented. Our model use a Simple-ResNet followed by a k-space correction module to synthesize full-sampled T2 images with the mulit-modality information of full sampled T1 and under-sampled T2 images. Experimental results show that our method can achieve better synthesized T2 images.Acknowledgements
No acknowledgement found.References
1. K. Krupa and M. Bekiesi´nska-Figatowska, “Artifacts in magnetic resonance imaging,” Polish journal of radiology, vol. 80, p. 93, 2015.
2. J. Sun, H. Li, Z. Xu et al., “Deep admm-net for compressive sensing mri,” in Advances in Neural Information Processing Systems, 2016, pp.10–18.
3. S. Yu, H. Dong, G. Yang, G. Slabaugh, P. L. Dragotti, X. Ye, F. Liu, S. Arridge, J. Keegan, D. Firmin et al., “Deep de-aliasing for fast compressive sensing mri,” arXiv preprint arXiv:1705.07137, 2017.
4. J. Schlemper, J. Caballero, J. V. Hajnal, A. N. Price, and D. Rueckert, “A deep cascade of convolutional neural networks for dynamic mr image reconstruction,” IEEE transactions on Medical Imaging, vol. 37, no. 2, pp. 491–503, 2018.
5. D. Lee, J. Yoo, and J. C. Ye, “Deep residual learning for compressed sensing mri,” in Biomedical Imaging (ISBI 2017), 2017 IEEE 14th International Symposium on. IEEE, 2017, pp. 15–18.
6. Xiang, Lei & Chen, Yong & Chang, Weitang & Zhan, Yiqiang & Lin, Weili & Wang, Qian. (2018). Deep Leaning Based Multi-Modal Fusion for Fast MR Reconstruction. IEEE Transactions on Biomedical Engineering. PP. 1-1. 10.1109/TBME.2018.2883958.
7. He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
8. Min H C , Pyung K H, Min L S , et al. Deep learning for undersampled MRI reconstruction[J]. Physics in Medicine and Biology, 2018.
9. The software is available from http://www.fil.ion.ucl.ac.uk/spm at the Wellcome Trust Centre for Neuroimaging, London, UK.
Figures