3637
Image Reconstruction Using Generative Adversarial Networks with MR-Specific Feature Map1Department of Biomedical Engineering, Department of Electrical Engineering, The State University of New York at Buffalo, Buffalo, NY, United States, 2Paul C. Lauterbur Research Center for Biomedical Imaging, SIAT, CAS,, Shenzhen, China, 3Program of Advanced Musculoskeletal Imaging (PAMI), Cleveland Clinic, Cleveland, OH, United States, 4Department of Biomedical Engineering, The State University of New York at Buffalo, Buffalo, NY, United States
Synopsis
Deep learning methods have demonstrated great potential in image reconstruction due to its ability to learn the non-linearity relationship between the undersampled k-space data and the corresponding desired image. Among these methods, Generative Adversarial Networks (GANs) is known to reconstruct images that are sharper and more realistic-looking. In this abstract, we study whether an MR-specific feature map that is trained on a large number of MRI images and used in the loss function can improve the GAN-based reconstruction. We demonstrate that the MR-specific feature map is superior to the pre-trained feature map typically used for GAN-based reconstruction.
Introduction
Deep learning has recently been studied for reconstructing MR images from undersampled k-space data1-5. Most studies have found that high-frequency details are lost in deep learning-based reconstruction, and images are perceptually unsatisfactory with overly smooth textures. Generative Adversarial Network (GAN) has gained popularity due to its ability to infer photo-realistic natural images6. Although many works have demonstrated superior reconstruction performance using GAN-based compressed sensing (CS)7-9, the reconstruction time is still too long. The end-to-end reconstruction using deep learning avoids the conventional CS iterations and has the benefit of ultrafast online reconstruction. For GAN-based end-to-end reconstruction, loss function for training is very important. Among the existing loss functions, the hybrid function9 considering both pixel-wise mean square error (MSE) and perceptual loss (VGG networks10,11) has shown to achieve better reconstruction details. However, the perceptual loss uses a high-level feature map pre-trained on ImageNet10, which contains natural images only. Although such a perceptual loss function improves image sharpness, it might hallucinate and introduce natural-looking artifacts when applied to MR reconstruction because the feature map is extracted from natural images only. Here we investigate whether the MR-specific feature maps can improve the GAN-based MR reconstruction in replace of a pre-trained feature map from ImageNet. MR knee images are used to obtain the MR-specific feature map trained on a VGG network and to test the reconstruction performance.Methods
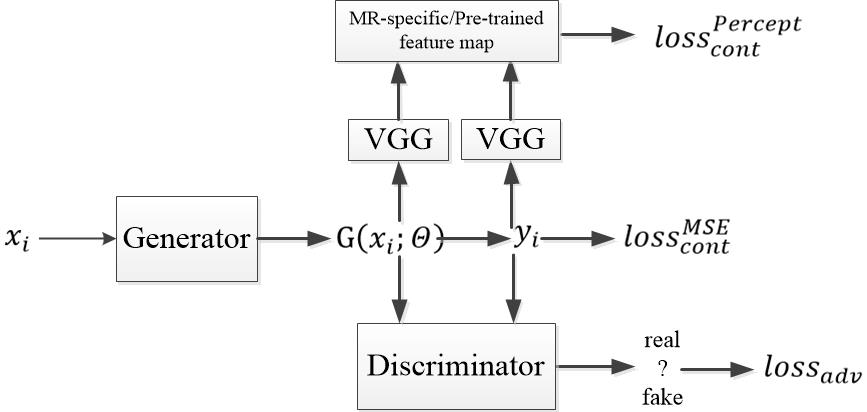
In GAN, there are two networks, a generator G and a discriminator D. The generator can generate high perceptual quality images according to the discriminator, which is a very good classifier to separate realistic and generated images. The loss function used for the generator is a combination of a content and an adversarial term: $$$loss_G=loss_{cont}+\lambda loss_{adv}(1)$$$, where λ=0.001. For the content term, we use a hybrid loss function: $$$loss_{cont}^{hybrid}=\alpha loss_{cont}^{MSE}+\beta loss_{cont}^{Percept}(2)$$$, where $$$\alpha+\beta \approx 1$$$ , which has shown to be superior to MSE or perceptual loss alone9. The first term is the traditional loss function using mean squared error (MSE): $$$loss_{cont}^{MSE}=\frac{1}{n}\sum_{i=1}^{n}\left \| G(x_i;\theta) -y_i \right \|^{2}(3)$$$, where n is the number of training samples, $$$G(x_i;\theta)$$$ is the reconstructed image generated by generator, $$$y_i$$$ is the ground truth image, and $$$x_i$$$ is the corresponding undersampled k-space data. The second term is the feature-based loss function: $$$loss_{cont}^{Percept}=\frac{1}{n}\sum_{i=1}^{n}\left \| \varphi _{i}G(x_i;\theta) -\varphi _{i}y_i\right \|^{2}(4)$$$, which defines the perceptual similarity using the high-level feature maps $$$\varphi _{i}$$$ from the i = 1,…, n training samples. We compare two different feature maps: one is the widely used feature map pre-trained on ImageNet, the other is our proposed MR-specific feature map. The term $$$loss_{adv}$$$ is defined based on the probabilities of the discriminator D overall training datasets as $$$loss_{adv}=\sum_{i=1}^{n}log\left ( 1-D\left ( G(x_i;\theta )) \right ) \right (5)$$$ , where $$$D\left ( G(x_i;\theta ) \right )$$$ is the probability that the reconstructed image is a ground truth image.6 The architecture of GAN is shown in Figure 1. For all existing GAN with pre-trained feature map, only the parameters in sub-networks G and D are learned during training, while keep the VGG sub-network fixed. In contrast, our proposed method learns the parameters in all three networks during training. Therefore, the feature maps generated by the online learned VGG sub-network include unique features specific to MR images.A total of 100 subjects were randomly selected from the Osteoarthritis Initiative (OAI) (SAG IW TSE with fat suppression, TR/TE=3200/30ms, resolution 0.5mm × 0.36mm × 3mm, a mixture of radiographic KL grades). 80% (2000 images) were used for training and obtain the MR-specific feature maps, 20% (500 images) were for testing to reconstruct images. 2D Poisson random sampling pattern was used with an acceleration factor of 6. For a fair comparison, we used the same epochs for training which takes around 1 day. The hardware specification is CPU i7-8700K (6 cores 12 threads @4.7GHz); Memory 64 GB; GPU 2x NVIDIA GTX 1080Ti.
Results and Discussion
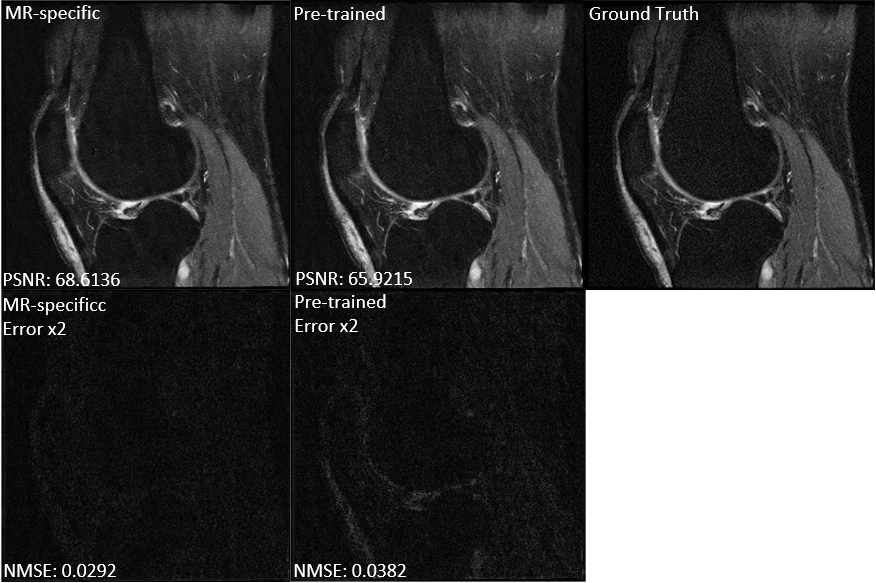
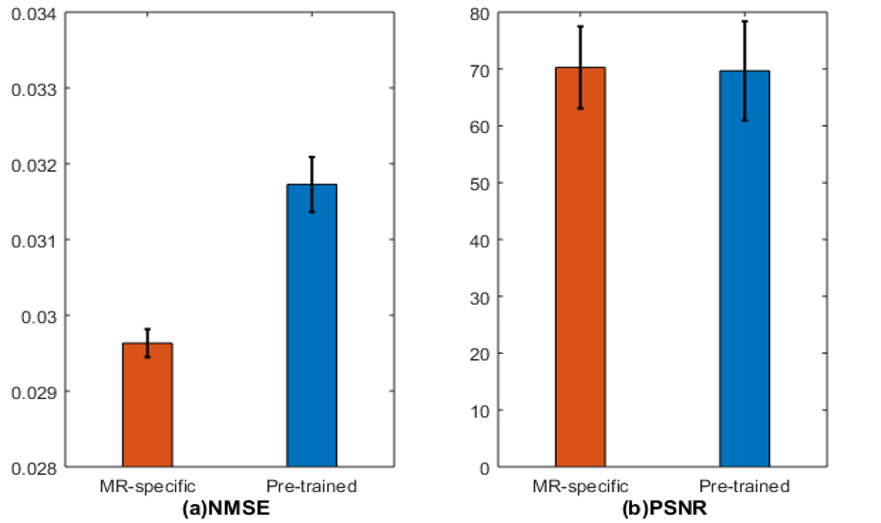
Figure 2 compares the GAN-based reconstructions using two different feature maps. It can be seen that the reconstruction with pre-trained feature maps suffers from loss of sharpness, while the reconstruction using our proposed MR-specific feature maps has sharp edges. The improvement can be seen more clearly in the error images in error images. The corresponding PSNRs and NMSEs shown on the bottom left of each image also indicate the MR-specific feature maps are better. Figures 3 shows the mean and standard deviation of the NMSEs and PSNRs of the two different feature maps, which are based on a total of 500 testing images. The top of bar is the mean value and error bar indicates the standard deviation. All these quantitative metrics indicate that it is worthwhile to retrain the feature map using MR images for MR reconstruction. It is also worth noting that the result depends to some extent on the training data. A larger-scale statistical analysis will be performed in future work.Conclusion
In this abstract, we investigate the use of an MR-specific feature map for GAN-based image reconstruction. Experimental results show that the proposed feature map is able to reconstruct images superior to those reconstructed with the conventional pre-trained feature maps. Larger data sets will be used for evaluating diagnostic performance and tissue quantification accuracy (cartilage thickness and composition) in future studies.Acknowledgements
Acknowledgments: This work is supported in part by the National Institute of Health U01EB023829.References
1. Wang S, et al. Accelerating magnetic resonance imaging via deep learning. ISBI 2016, pp. 514-517.
2. Jin K H. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4509-4522, Sept. 2017.
3. Zhu B, et al. Image reconstruction by domain-transform manifold learning. Nature 555, 2018.
4. Lee D, et al. Deep residual learning for compressed sensing MRI. ISBI 2017 pp. 15-18.
5. Schlemper J, et al. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. arXiv:1704.02422, 2017.
6. Ledig C. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
7. Mardani M, et al. Deep Generative Adversarial Networks for Compressed Sensing Automates MRI. arXiv: 1706.00051, 2017.
8. Quan T M. Compressed Sensing MRI Reconstruction Using a Generative Adversarial Network With a Cyclic Loss. IEEE Transactions on Medical Imaging, vol. 37, no. 6, pp. 1488-1497, June 2018.
9. Yang G. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Transactions on Medical Imaging, vol. 37, no. 6, pp. 1310-1321, June 2018.
10. Simonyan K. Very deep convolutional networks for large-scale image recognition, in ICLR, 2015.
11. He K. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1026–1034.
Figures