3598
Attention Based Scale Recurrent Network for Under-Sampled MRI Reconstruction1Electrical Engineering Department, Pontificia Universidad Católica de Chile, Santiago, Chile, 2Biomedical Imaging Center, Pontificia Universidad Católica de Chile, Santiago, Chile, 3Millennium Nucleus for Cardiovascular Magnetic Resonance, Santiago, Chile, 4Institute for Biological and Medical Engineering, Pontificia Universidad Católica de Chile, Santiago, Chile
Synopsis
We propose an Attention Based Scale Recurrent Network for reconstructing under-sampled MRI data. This network is a variation of the recently proposed Scale Recurrent Network for blind deblurring1. We treat the reconstruction problem as a deblurring problem. Thus the under-sampling pattern does not need to be known. We trained and tested our network with the NYU knee dataset available for the fastMRI challenge. The proposed model shows promising results for single-coil reconstruction outperforming both baselines.
Introduction
We aim to reconstruct MR images from under-sampled data in the Fourier domain. We used the knee dataset made publicly available by NYU for the fastMRI challenge3. The data correspond to proton density (PD) and fat-saturated proton density (PDFS) acquisitions with acceleration factors of 4x and 8x. Our system takes as input the complex-valued minimum energy reconstruction (zero-filled) and outputs an image with minimal aliasing artifacts. For training purposes, we undersampled with three different random patterns each slice of the fastMRI dataset3.Methods
Network architecture.We based our architecture on the one proposed by Tao et al1. for image deblurring. Inspired by the success of a “coarse-to-fine” resolution strategy, they propose a scale-recurrent network (SRN), that is, a scaled network with a recurrent layer in the bottle-neck with shared weights. This idea avoids the large number of parameters of deeper convolutional networks, needed to handle the spatial dependency correctly. This type of architecture is well fit for our reconstruction problem since the under-sampling in k-space can be thought of as a blurring in the image-space, with a very particular point spread function. Our Attention Based Scale Recurrent Network (AB-SRN), shown in Figure 3, differs from the SRN in that:
- For simplicity we used a gating recurrent unit (GRU) at the bottle-neck instead of “long short term memory” (LSTM).
- We added a self-attention module after the recurrent layer. The self-attention module is connected to the output of the recurrent layer of the next scale. This way of handling the attention similar to that of the sequence to sequence models. The attention is resized with a convolutional layer. This output is later multiplied with the output of the following scale recurrent layer. The idea is to consider the useful features of the previous scale to the reconstruction of the current one.
We normalized each sample by the largest magnitude present in the zero-fill image. Then we used the magnitude of the zero-filled as input and the magnitude of the fully sampled as output. The magnitude of the fully sampled is also normalized by the same constant used in the normalization of the zero-filled example.
Loss function
We used the following differentiable loss function:
$$\mathcal{L}(\theta) = \mathbb{E}_{(\hat{x},y)}\{L_0(f_\theta(\hat{x}), y) + \text{DSSIM}(f_\theta(\hat{x}), y)\},$$where $$$\hat{x}$$$ is the input (zero-filled image), $$$y$$$ is the ground truth (fully sampled magnitude), $$$L_0$$$ is the annealed version of the $$$\ell_0$$$ quasi-norm2 : $$$L_0(x,y) = (|x - y|+\epsilon)^\gamma$$$ ($$$\gamma$$$ was varied linearly from 2 to 0 during the 50 epochs of training), $$$\mathrm{DSSIM}$$$ is the structural dissimilarity index, and $$$f_{\theta}(x)$$$ is the network output with parameters $$$\theta$$$.
We trained on the splits proposed by fastMRI undersampling three times each slice of the training set. The same was done with the validation split.
Results
The results are reported in Table 1.Even though our method did not win the fastMRI challenge, the proposed architecture outperformed (when looking at the NMSE, SSIM and PSNR indices) the baseline classical reconstruction model in every category in the single-coil reconstruction task. Examples of reconstructions made by the model can be seen in Figure 1 and Figure 2.
Discussion and conclusion
Our AB-SRN showed promising results in the NYU dataset, outperforming the given baseline. This method has the advantage that we do not need to know the under-sampling pattern to reconstruct the image. A more extensive data set could improve our single-coil reconstructions, as we were limited on the number of simulated under-samplings per image. Using only three under-sampling patterns per image. Visually, it can be appreciated some blurring remaining, although most of the aliasing artifacts were considerably reduced. Future research must be done to assess the effect of different configurations of attention to use the learned features from the previous scales through the neural network.Acknowledgements
The Millennium Nucleus for Cardiovascular Magnetic Resonance is supported by the Millennium Scientific Initiative of the Ministry of Economy, Development and Tourism (Chile).References
1. Tao, X. , Gao, H., Shen, X. , Wang, J., & Jia, J. (2018). Scale-Recurrent Network for Deep Image Deblurring.2018 IEEE/CVFConference on Computer Vision and Pattern Recognition.doi: 10.1109/cvpr.2018.00853.
2. Jaakko Lehtinen, Jacob Munkberg, Jon Hasselgren, Samuli Laine, Tero Karras, Miika Aittala, & Timo Aila(2018). Noise2noise: Learning image restoration without clean data. preprint arXiv:1803.04189.
3. Zbontar J., Knoll F., et al. fastMRI: An Open Dataset and Benchmarks for Accelerated MRI.arXiv:1811.08839
Figures

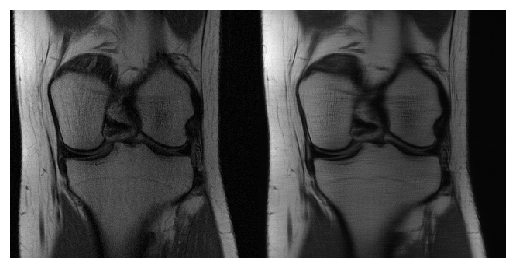
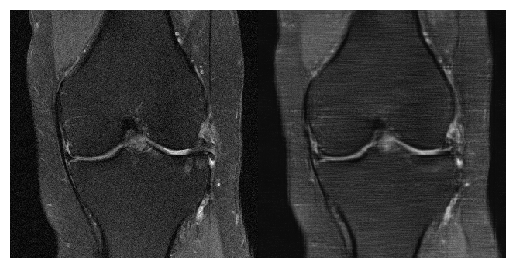
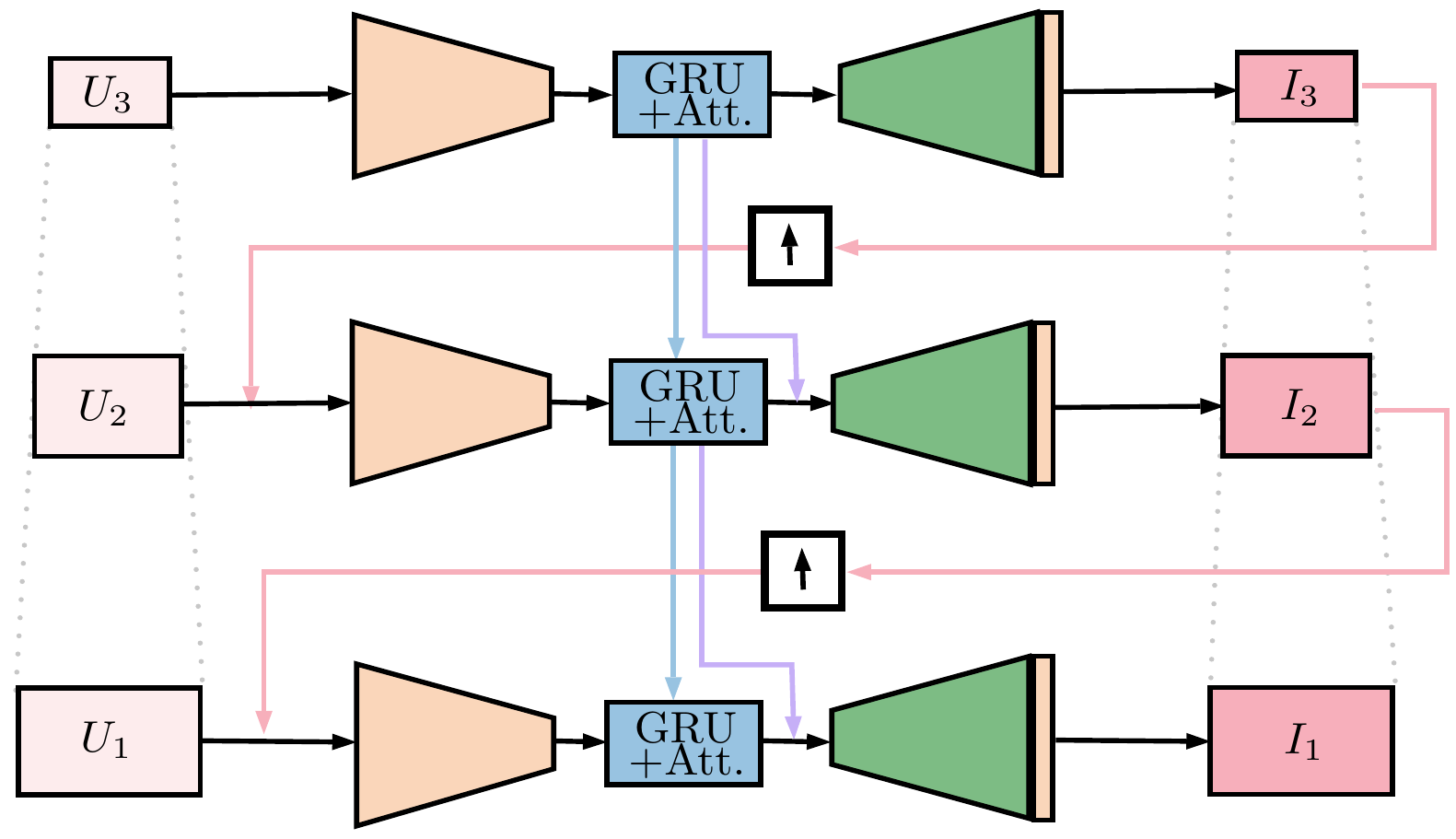
Figure 3: Neural Network Architecture.The main difference in contrast to Tao's 1 model, is the bottleneck, where we used GRU's (blue) also passing the attention information (purple) to the next levels in the pyramidal scheme.