3594
A deep network for reconstruction of undersampled fast-spin-echo MR images with suppressed fine-line artifact
Sangtae Ahn1, Anne Menini2, and Christopher J Hardy1
1GE Global Research, Niskayuna, NY, United States, 2GE Healthcare, Menlo Park, CA, United States
1GE Global Research, Niskayuna, NY, United States, 2GE Healthcare, Menlo Park, CA, United States
Synopsis
Fine-line artifact is suppressed in Fast Spin Echo (FSE) images reconstructed with a deep-learning network. The network is trained using many examples of fully sampled Nex=2 data. In each case the two excitations are combined to generate fully sampled ground-truth images with no fine-line artifact, which are used for comparison with the generated image in the loss function. However only one of the excitations is retrospectively undersampled and fed into the input of the network during training. In this way the network learns to remove both undersampling and fine-line artifacts. At inferencing, only Nex=1 undersampled data are acquired and reconstructed.
Introduction
Deep-learning MRI reconstruction networks, including unrolled iterative compressed-sensing networks1-3, have been shown to outperform conventional PICS (Parallel Imaging and Compressed Sensing) methods for reconstructing high-quality images from undersampled data. When applied to FSE (Fast Spin Echo) data, however, these networks can yield images exhibiting fine-line artifact (e.g. Figs. 1B and D). This arises because the refocusing pulses are typically not perfect 180-degree pulses, resulting in free-induction-decay (FID) signals from the refocusing pulses that bleed into the echoes in the echo train (Fig. 2). This problem can be exacerbated at fields of 3T and higher, because the amplitude of the refocusing pulses is often dialed back to reduce SAR. While crusher gradients can help ameliorate this problem, they are often imperfect due to limits on amplitude and slew rate and the need to minimize echo spacing.Fine-line artifact can be prevented by use of Nex=2 imaging, as shown in Figs. 1 and 2. Inverting the phase of the RF excitation on the second excitation will invert the phase of the echoes in the echo train, but not the FIDs (since these arise from the refocusing pulses). Subtraction of the second excitation from the first will thus subtract the artifactual signals while effectively adding the echoes from the two excitations. The result, as seen in Figs. 1A and C, is an image with no fine-line artifact.
The drawback of this approach is that the imaging time has now been doubled. This is especially problematic if fast imaging is required. Raising R values while using Nex=2 generally yields suboptimal SNR (due to g-factor), and halves the maximum possible imaging speed. We present here a method for generating Nex=1 FSE images with no fine-line artifact, including accelerated (R>1) images.
Methods
Normally in unrolled iterative reconstruction networks, Nex=1 data are retrospectively undersampled and fed into the network, for training against the corresponding fully sampled images at the output. Instead, to suppress fine-line artifact in our deep network, we use many examples of Nex=2 raw FSE data to train the network, as shown in Fig. 3. Specifically, for each dataset the two excitations are combined and reconstructed into a fully-sampled ground truth (GT) image that has no fine-line artifact, for comparison with the generated image in the loss function. However, only one of the two excitations is retrospectively undersampled and fed into the input of the network during training (Fig. 3). In this way the network is trained to both remove undersampling artifacts and to suppress fine-line artifact. At inferencing, only Nex=1 undersampled data are acquired and reconstructed.A DCI network3 was trained using 28 series of Nex=2 FSE data, comprising 754 slices, with independent datasets of 113 slices used for validation and 110 slices for testing. The network used 16 iterations, 16 convolutional layers – with 48 filters – per iteration, and dense skip connections among iterations.
Results
Example test results are shown in Fig. 4. A fully-sampled Nex=1 image (Fig. 4B) reconstructed by conventional means shows fine-line artifact, unlike the corresponding fully-sampled Nex=2 image (Fig. 4A). The output of the network, with the input undersampled fourfold, is shown in Fig. 4C. Imaging time is fourfold lower in C) than in B) and eightfold lower than in A), with fine-line artifact suppressed. Table 1 compares results for the test images generated by two networks, both trained against Nex=2 ground-truth images. The first, fine-line suppressing network was trained using Nex=1 undersampled data at the input, and the second, control network used Nex=2 undersampled data.Discussion
Other means of minimizing fine-line artifacts include increasing the crusher gradient area or windowing out that portion of k-space containing the artifactual signal. However, the first of these methods generally increases echo spacing and thus aggravates blurring, while the second reduces spatial resolution. Higher crusher areas are required as the voxel size decreases, making the problem especially acute for smaller fields of view and slice thickness. In these cases, a fine-line suppressing neural network should be especially useful. The results from Table 1 are not significantly different for the FLS and control networks, indicating that overall image quality is not sacrificed by training the network for fine-line suppression.Conclusions
Our deep MR reconstruction network suppresses both fine-line and undersampling artifacts in Nex=1 undersampled MR images, allowing the use of highly accelerated FSE imaging.Acknowledgements
No acknowledgement found.References
- Hammernik K, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med 2018;79(6):3055-3071.
- Schlemper J, et al. A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans Med Imaging 2018;37(2):491-503.
- Malkiel I, et al. Densely connected iterative network for sparse MRI reconstruction. ISMRM 2018, p. 3363.
Figures
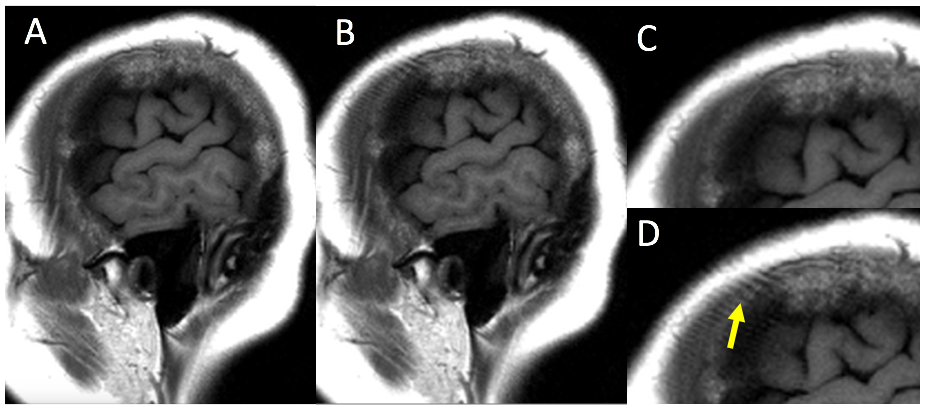
Figure 1. Fast-spin-echo images acquired with A) Nex=2, and B) Nex=1, with corresponding regions of interest in C) and D), respectively. Fine-line artifact (arrow) is evident in Nex=1 image but not Nex=2 image.
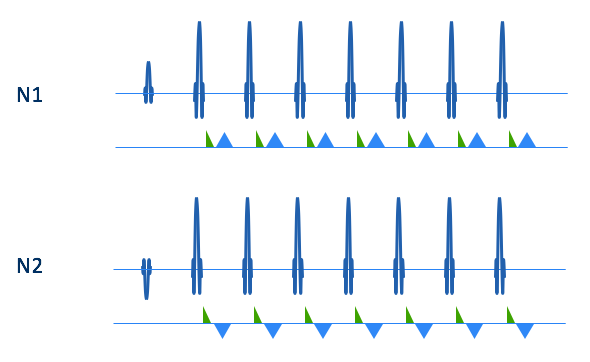
Figure 2. Illustration of fine-line suppression by Nex=2 scanning. Echo trains from first (N1) and second (N2) excitations, with phase of excitation pulse inverted on second excitation. If refocusing pulses are not exactly 180 degrees, and gradient crushing is not complete, the echo train will include artifactual free-induction decays (green triangles) as well as echoes (blue triangles), which can lead to fine-line artifact. If the second excitation is subtracted from the first, then the artifactual signal is cancelled, while the true echo-based signal is added.
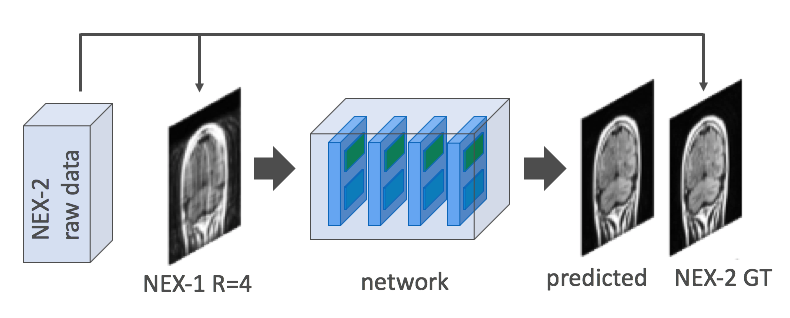
Figure 3. In order to suppress fine-line artifact, our unrolled iterative network is trained using Nex=2 raw data. The two excitations are combined and reconstructed into a fully-sampled ground truth (GT) image that has no fine-line artifact. However, only one of the two excitations is undersampled and fed into the input of the network. In this way the network is trained to remove both fine-line and undersampling artifacts.
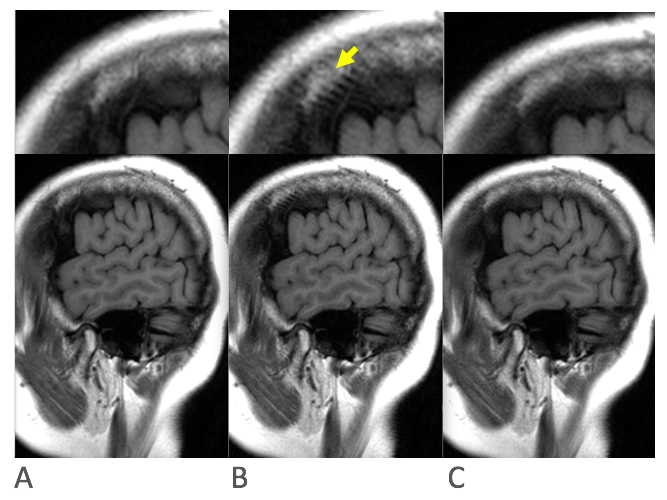
Figure 4. Results C) of training using DCI-net with fine-line suppression: A) fully-sampled Nex=2 image, B) fully-sampled Nex=1 image, C) Nex=1 image undersampled by a factor of 4, generated by DCI network. Imaging time is fourfold lower in C) than B) and eightfold lower than in A), with minimal fine-line artifact.

Table 1. Normalized
mean-square error (nMSE) and structural similarity (SSIM) measures of network test images relative to
Nex=2 ground-truth, for the fine-line suppressing (FLS) network inferenced with
R=4 and Nex=1, and for a similar control network, inferenced with R=4 and Nex=2.
Both networks were trained against Nex=2 ground-truth, but with Nex=1 input for
FLS and Nex=2 for the control.