3575
Transfer learning framework for knee plane prescription1GE Global Research, Niskayuna, NY, United States, 2GE Healthcare, Rio de Janeiro, Brazil, 3GE Healthcare, Bangalore, India, 4Mayo Clinic, Rochester, MN, United States
Synopsis
On model deployment, ideally deep learning models should be able learn continuously from new data, but data privacy concerns in medical imaging do not allow for ready sharing of training data. Retraining with incremental data generally leads to catastrophic forgetting. In this study, we evaluated the performance of a knee plane prescription model by retraining with incremental data from a new site. Increasing the number of incoming training data sets and transfer learning significantly improved test performance. We suggest that partial retraining and distributed learning frameworks may be more suitable for retraining of incremental data.
Introduction
Deep learning is a promising approach for automated analysis of medical imaging data. Ideally, we would like these models to continuously learn and adapt with new data; but this is remains a challenge for neural network models since most of these models are trained with stationary large batches of data. Retraining with incremental data generally leads to catastrophic forgetting1, i.e., training a model with new information interferes with previously learned knowledge. Although retraining from scratch is the best solution for catastrophic forgetting, data privacy and ethical concerns in medical imaging do not allow for sharing of training data. In this study, we evaluated the performance of a knee plane prescription model by retraining with incremental numbers of incoming data from a new site.Methods
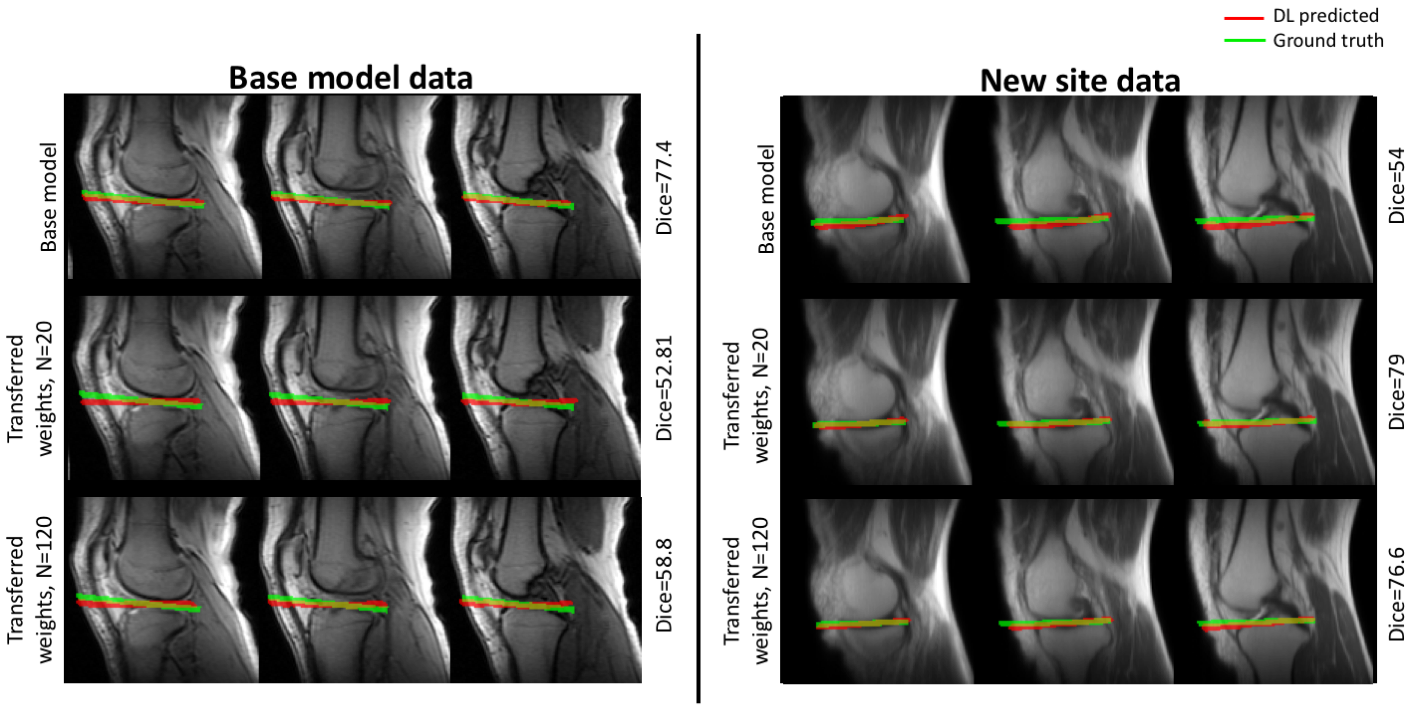
DL base model: Our intelligent slice placement (ISP) approach uses pre-trained DL-models to estimate both coronal and sagittal scan plan prescriptions from 2D tri-planar localizer images. These DL-models were derived from previous work2 and uses 3D u-net to predict segmentations for scan-planes from input tri-planar localizer images. The DL-models for ISP were trained with knee dataset from multiple sites, multiple MRI scanners with different coil configurations (>20,000 localizer images; GE 3T Discovery MR 750w, GE Signa HDxt 1.5T, GE 1.5T Optima 450w; 16-/18-channel TR Knee coil, GEM Flex coil).Data: In this study, for retraining with new clinical site data, we used 120 exams from a clinical site acquired over 6-month period as scanned by several technicians (GE 3T Discovery MR 750w, GE Signa HDxt 1.5T; several coils). In this study we focused on the meniscus plane, defined as the plane passing through the top of the tibia-plateau crossing the meniscus. To generate the ground truth scan plane for each case, we used markings from an in-house expert. Scan-planes were marked on localizer images following the same anatomical definitions as the clinical-scans (high-resolution images were available for reference whenever needed). To mimic the scenario of incremental incoming data from a new clinical site that does not have access to the base model training data, we retrained the DL-models with batches of data (20 additional new training data in each batch, transfer model) in two scenarios (1) random weight initialization (2) transferred weights from base model.
Retrained model: To compare test performance, we also retrained the model from scratch with the combined data from base model and new site.
Test performance: The test data cohort consisted of data from the base model sites and data from the new clinical site. By definition, the test data was never a part of the training data sets. Note that the test data was the same across all experiments. Test performance was evaluated using three metrics (1) dice coefficient (2) angle error and (3) mean absolute distance error (MAD).
Results
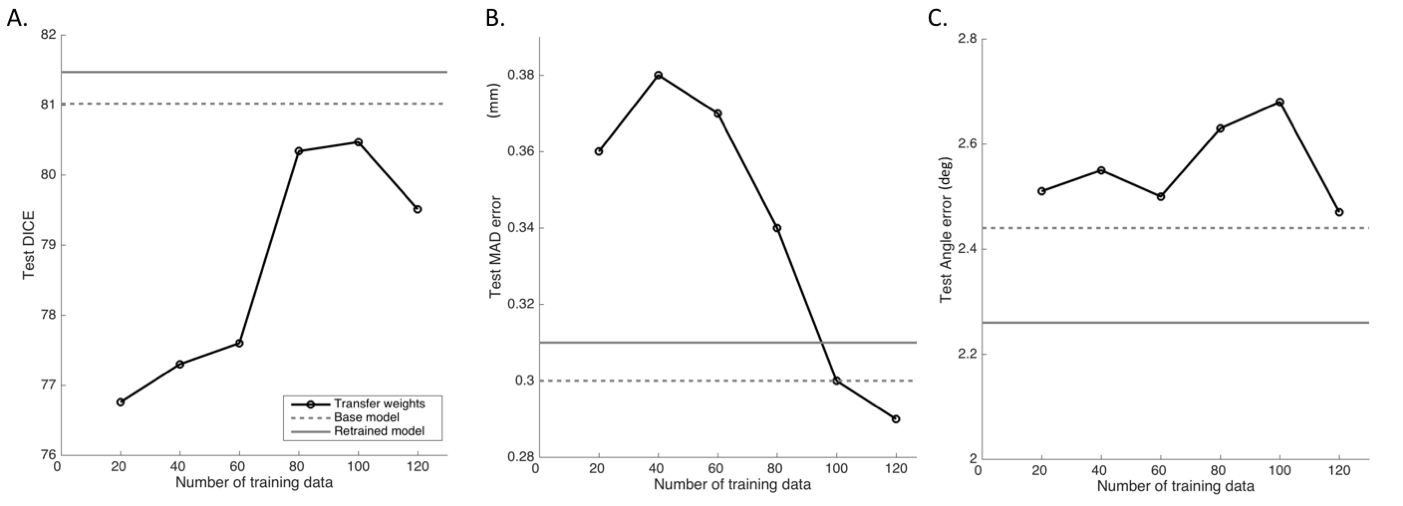
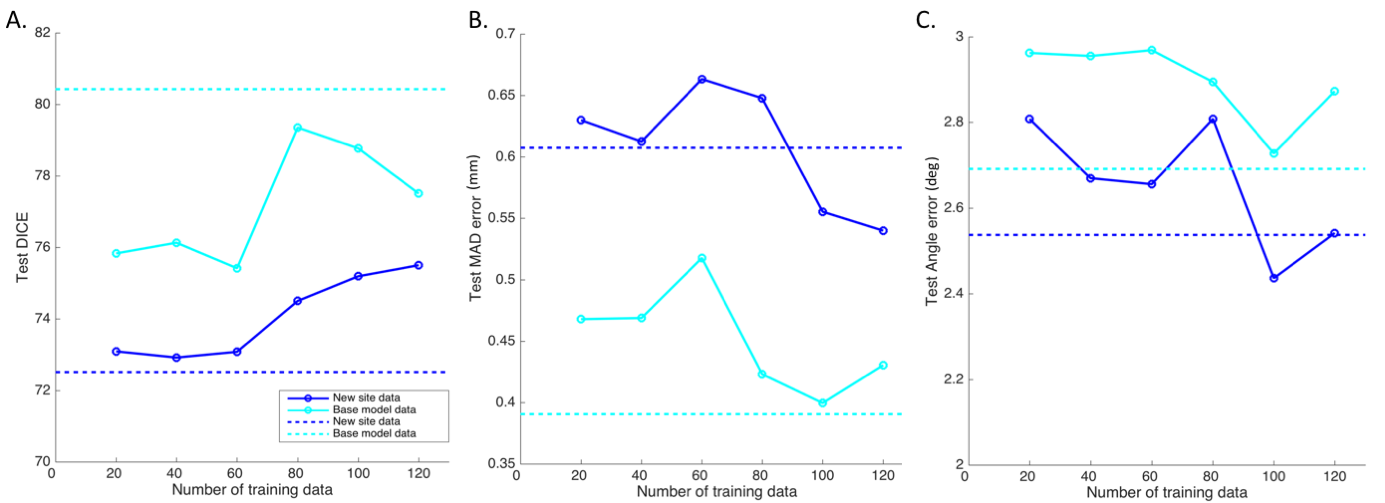
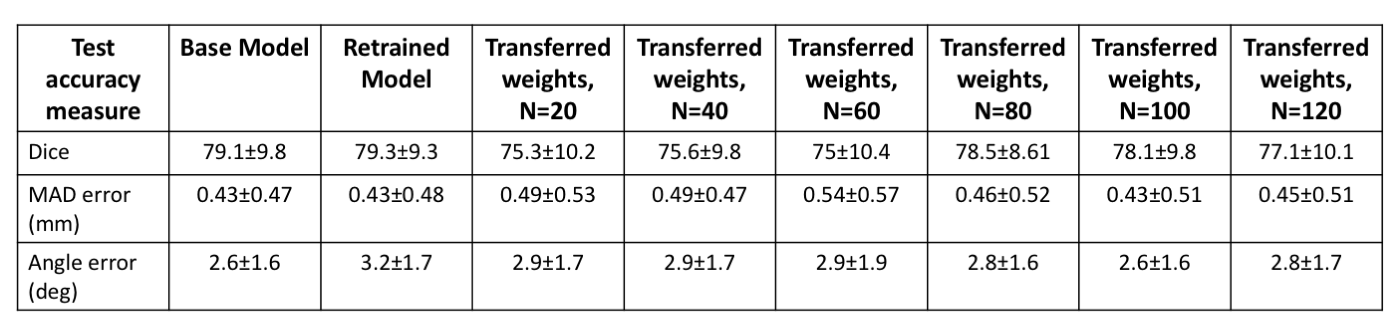
The test performance of the retrained model with the combined data was better than the base model (Figure 1, Table 1). To evaluate the effects of retraining with incremental batches of data, we compared test performance of the transfer model with the (1) base model and (2) retrained model. Performance was significantly improved when retraining models for incoming batches of data with transferred weights from base model instead of random weight initialization. For a training batch size of 120 exams from the new site, the mean test dice for randomly initialized weights was 72.7 ± 13 compared to 77.1 ± 10 for transferred weights. While increasing the number of exams in each batch did improve the test accuracy, performance remained lower than both the base model and the retrained model (Table 1, Figure 1). As expected the base model performance on new site data was lower than base model site data (Figure 2). Retraining the model with incremental batches of new site improved model performance on the new site data (compared to base model), but the model performance on the base model site data remained lower (compared to base model) (Figure 2,3).Discussion and Conclusion
While increasing the number of incoming training data sets and initializing the model with trained model weights significantly improves test performance for the transfer model, it still remained lower than the test performance of the base model. Further, retraining with new site data has the effect of tuning the model for the new data while sacrificing performance on the base model test data. Creative forms of retraining for incremental data3 including partially retraining of network and other distributed learning frameworks4 might be effective in scenarios in which the training patient data cannot be shared.Acknowledgements
No acknowledgement found.References
1. French. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 3, 128–135 (1999).
2. Shanbhag, D. et al. A generalized deep learning framework for multi-landmark intelligent slice placement using standard tri-planar 2D localizers. in Proceedings of ISMRM 2019 p.670 (2019).
3. Kirkpatrick, J. et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. U. S. A. 114, 3521–3526 (2017).
4. Chang, K. et al. Distributed deep learning networks among institutions for medical imaging. J. Am. Med. Inform. Assoc. 25, 945–954 (2018).
Figures