3574
3D MRI Processing Using a Video Domain Transfer Deep Learning Neural Network1Imaging Physics Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 2Cancer Systems Imaging Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States
Synopsis
3D deep-learning neural networks can help ensure the slice-to-slice consistency. However, the performance of 3D networks may be degraded due to limited hardware. In this work, we developed a video domain transfer framework for 3D MRI processing to combine benefits of 2D and 3D networks with less graphical processing unit memory demands and slice-by-slice coherent outputs. Our approach consists of first translating “3D MRI images” to “a time-sequence of 2D multi-frame motion pictures,” then applying the video domain transfer to create temporally coherent multi-frame video outputs, and finally translating the output back to compose “spatially consistent volumetric MRI images.”
INTRODUCTION
Deep learning (DL) convolutional neural network (CNN)1,2 and generative adversarial network (GAN)3 have found an increasing number of applications in MRI. In general, CNNs and GANs have been applied to each slice image separately or to all the slices together, depending on whether the network is 2D1 or 3D.2 3D networks can help ensure the slice-to-slice consistency. However, the performance of 3D networks may be degraded and even worse than a 2D network due to limited hardware. For example, high demands on graphical processor unit (GPU) memory by 3D networks with a large number of nodes and interconnections often require a high degree of network-structure simplification and approximation.In this work, we propose to use video domain transfer (VDT)4 to ensure the slice-to-slice consistency in 3D MRI image processing. Our approach consists of first translating “3D MRI images” to “a time-sequence of 2D multi-frame motion pictures,” then applying a VDT network to create temporally coherent multi-frame video outputs, and finally translating the output back to compose “spatially consistent volumetric MRI images.”
METHODS
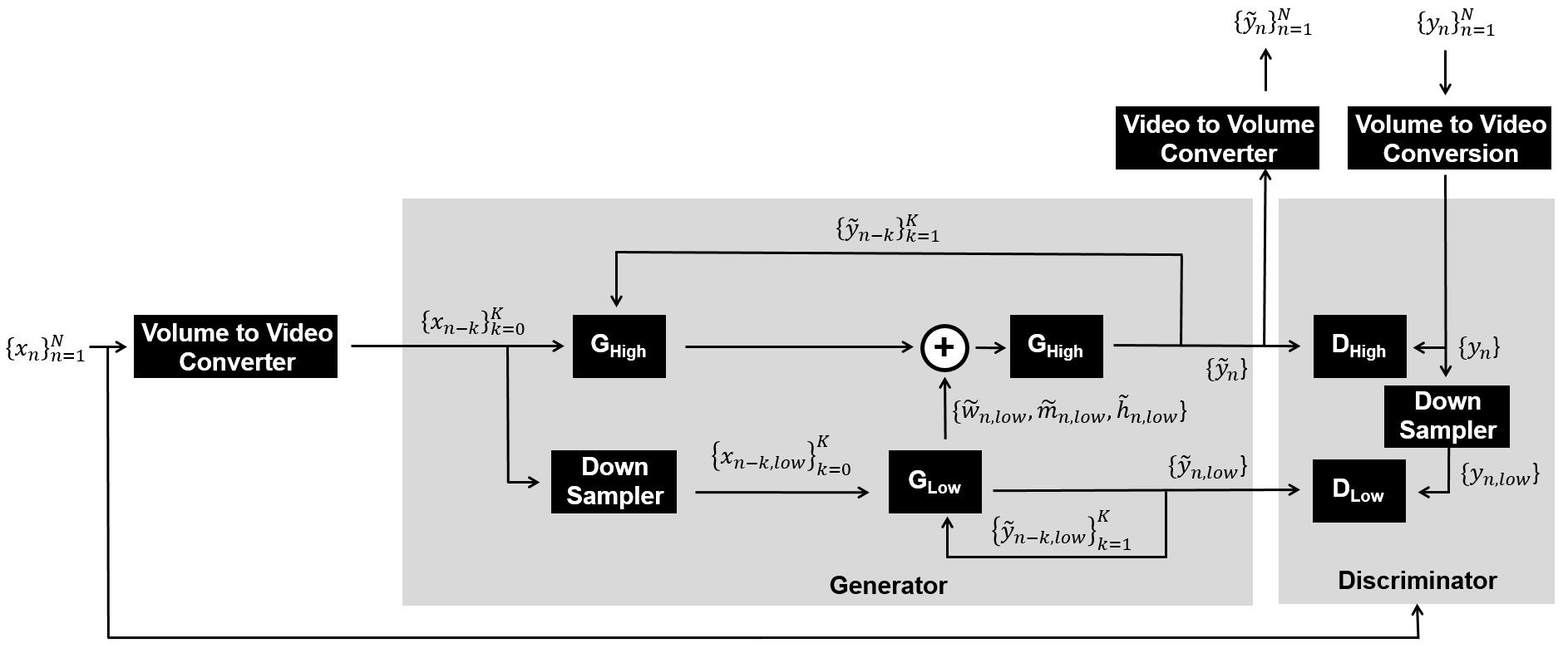
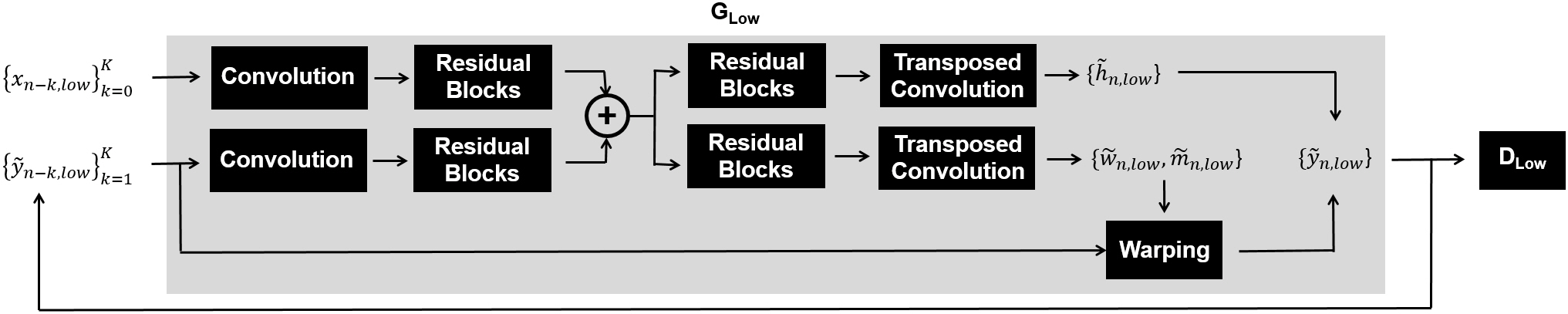
Fig. 1 shows our proposed framework including the spatio-temporal progressive conditional generative adversarial network (CGAN) for VDT. Volumetric input and output image pairs $$$\left\{{x_{n},y_{n}}\right\}_{n=1}^N$$$ from a total of N slices were first translated to time-sequential multi-frame moving pictures, then trained with multi-scale and multi-frame generators and discriminators (Fig. 2 and Fig. 3). The proposed method assumes an output slice-image $$$\left\{{\tilde{y}_{n}}\right\}$$$ can be determined by a current input image $$$\left\{{x_{n}}\right\}$$$ and previously processed input and output pairs from K neighboring slices $$$\left\{{x_{n-k},\tilde{y}_{n-k}}\right\}_{k=1}^K$$$.In the first step of training, an input image from the current slice $$$\left\{{x_{n}}\right\}$$$ and previously processed K image pairs $$$\left\{{x_{n-k},\tilde{y}_{n-k}}\right\}_{k=1}^K$$$ were down-sampled, then trained with a “low-resolution temporal-progressive generator (GLow)” to create a low-resolution output image $$$\left\{{\tilde{y}_{n,low}}\right\}$$$ (Fig. 2). The GLow consists of four cascaded processing blocks: front-end convolution for down-scaling, residual blocks for feature extraction, transposed convolution to estimate three feature maps (an optical flow-map $$$\left\{{\tilde{w}_{n,low}}\right\}$$$, an occlusion map $$$\left\{{\tilde{m}_{n,low}}\right\}$$$, and a hallucinated image $$$\left\{{\tilde{h}_{n,low}}\right\}$$$), and the final back-end blocks to generate $$$\left\{{\tilde{y}_{n,low}}\right\}$$$ from three feature maps.4,5
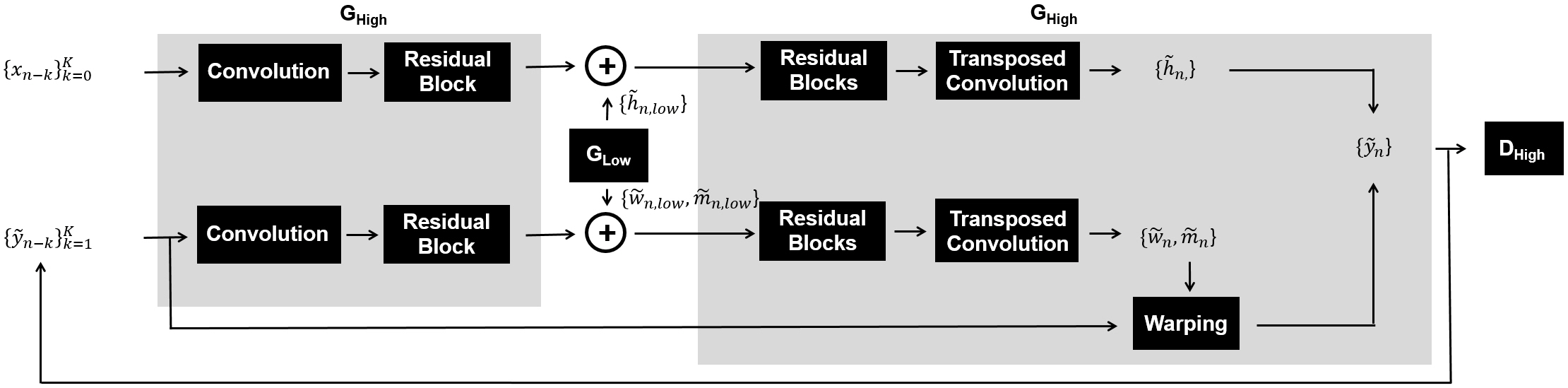
The second step is to append the “high-resolution spatio-progressive generator (GHigh)” to the front and back-ends of GLow to jointly train both generators (GHigh and GLow) for generating a high-resolution slice image $$$\left\{{\tilde{y}_{n}}\right\}$$$ (Fig. 3). While jointly training both generators with multiple scale image pairs, GHigh repeatedly creates high-resolution feature maps $$$\left\{{\tilde{w}_{n},\tilde{m}_{n},\tilde{h}_{n}}\right\}$$$, then synthesizes six feature maps to learn how to generate high-resolution slice images $$$\left\{{\tilde{y}_{n}}\right\}$$$ which are indistinguishable with $$$\left\{{y_{n}}\right\}$$$ to the discriminators. These two steps of slice generation processes were alternated and repeated until all the slices are reconstructed.
For the discriminator architecture, we adapted the multi-frame and multi-scale discriminators5-8 to collectively evaluate multiple slice images with different scales from the current and neighboring slice locations. After the training, temporally coherent multi-frame video images were created from 3D test images, then finally rearranged to compose the spatially consistent volumetric MRI images.
RESULTS
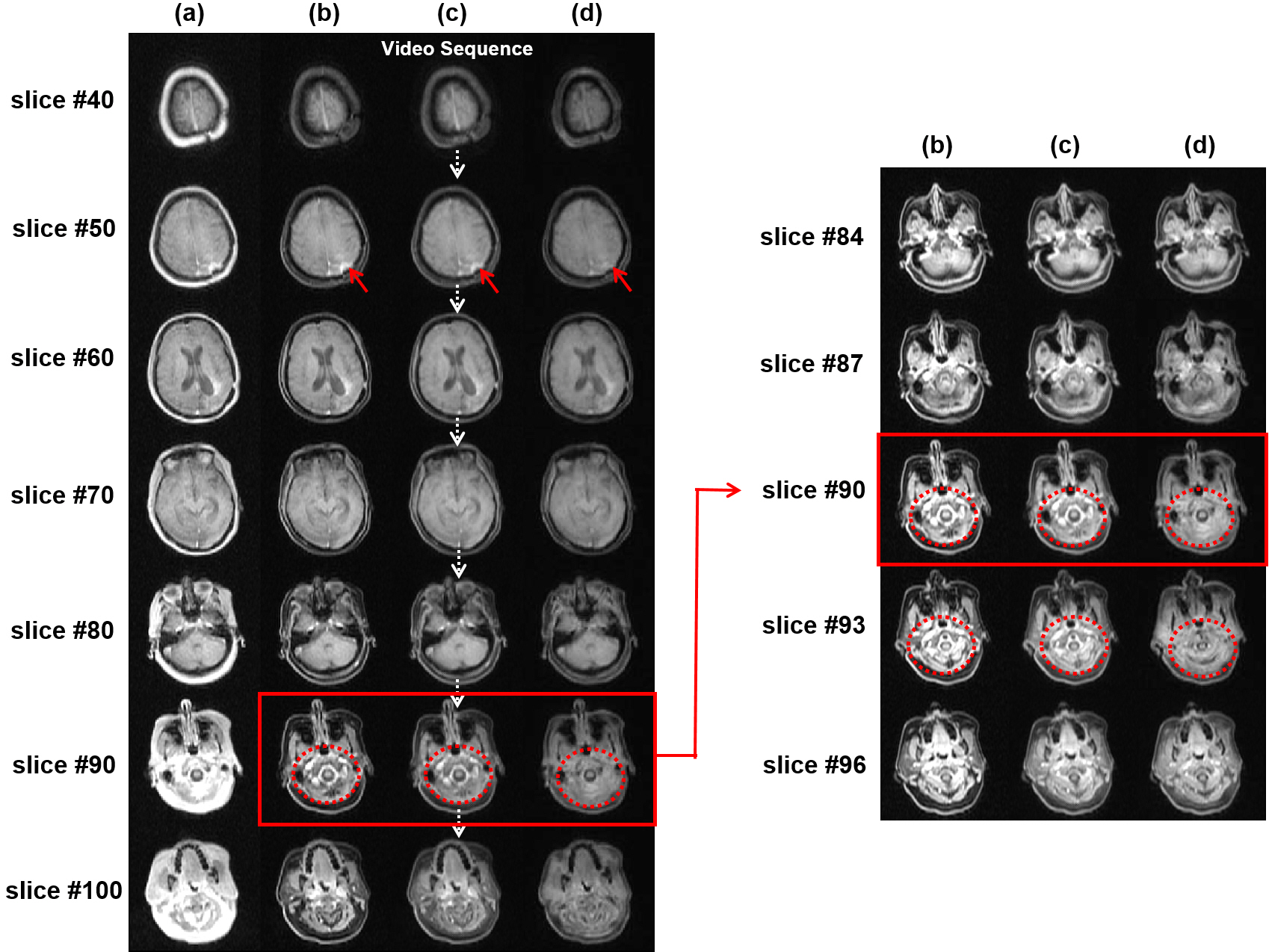
We implemented the proposed framework on a NVIDIA DGX-1 system with two 32GB Tesla V100 GPUs (NVIDIA, Santa Clara, CA, USA) and tested it on Dixon water and fat separation for a 3D dual-echo gradient echo sequence. The multi-frame and multi-scale CGAN (Fig. 2 and Fig. 3) was trained with 16 sets of 3D images. The input images were acquired on a SIGNA PET/MR 3T scanner (GE Healthcare, Waukesha, WI, USA) with the following scan parameters: TE1/TE2/TR = 1.1/2.2/4.0ms, Nx x Ny x Nz = 256 x 256 x 120, NFE x NPE = 256 x 128, slice-thickness/slice-gap = 5.2/-2.6mm, FOV = 50 x 37.5cm, RBW = ±166.7kHz, NEX = 0.7, and scan-time = 15secs. The network input and output image pairs are in-phase and water-only images respectively, and both were generated on the scanner. We trained our model for 20 epochs with a least squares generative adversarial network (LSGAN) loss model and an adaptive moment estimation (ADAM) optimizer (mini-batch for instance normalization=2, initial learning rate=0.0002, β1=0.5, and β2=0.999). During the CGAN training, three generators and three discriminators were used to create and evaluate three different scales of images.Fig. 4 (a-b) show the ground-truth input and output image pairs provided for the network training. The proposed framework was able to reconstruct consistent water-only images (Fig. 4 (c)) for all the test images compared to a reference set of images from pix2pixHD (Fig. 4 (d)).9 The pix2pixHD is an image domain transfer network that processes each slice image separately while ignoring the slice-to-slice correlations.
DISCUSSION AND CONCLUSION
The VDT network was originally designed to synthesize high-resolution (2K, 2048 x 1024) photorealistic video images from a series of edge-maps or semantic segmentation labels.4 Our results show that the same network can be adapted to reconstruct 3D MRI images. Compared to a 2D network, the spatio-temporal progressive CGAN used in VDT can create temporally coherent images and effectively aggregate both global and local image features and details during the processing.The proposed method has the combined benefits of 2D and 3D networks with less GPU memory demands and slice-by-slice coherent outputs. The method may also be extended to 4D MRI applications that require coherent reconstructions such as dynamic contrast enhanced imaging.
Acknowledgements
No acknowledgement found.References
1. Ronneberger O, Fischer P, and Brox T. U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention. 2015:234-241.
2. Cicek O, Abdulkadir A, Lienkamp SS, Brox T, and Ronneberger O. 3D U-Net: learning dense volumetric segmentation from sparse annotation. Medical Image Computing and Computer-Assisted Intervention. 2016:424-432.
3. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, and Bengio Y. Generative adversarial networks. In Advances in Neural Information Processing Systems. 2014:2672-2680.
4. Wang TC, Liu MY, Zhu JY, Liu G, Tao A, Kautz J, and Catanzaro B. Video-to-video synthesis. In Advances in Neural Information Processing Systems. 2018.
5. Wang TC, Liu MY, Zhu JY, Tao A, Kautz J, and Catanzaro B. High-resolution image synthesis and semantic manipulation with conditional GANs. In IEEE Conference on Computer Vision and Pattern Recognition. 2018.
6. Isola P, Zhu JY, Zhou T, and Efros AA. Image-to-image translation with conditional adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2017.
7. Ghosh A, Kulharia V, Namboodiri V, Torr PH, and Dokania PK. Multi-agent diverse generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2018.
8. Shrivastava A, Pfister T, Tuzel O, Susskind J, Wang W, and Webb R. Learning from simulated and unsupervised images through adversarial training. In IEEE Conference on Computer Vision and Pattern Recognition. 2017.
9. Wang TC, Liu MY, Zhu JY, Tao A, Kautz J and Catanzaro B. High-resolution image synthesis and semantic manipulation with conditional GANs. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
Figures