3570
No-Reference Assessment of Perceptual Noise Level Defined by Human Calibration and Image Rulers1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States
Synopsis
We propose accessing the MRI quality, perceptual noise level in particular, during a scan to stop it when the image is good enough. A convolutional neural network is trained to map an image to a perceptual score. The label score for training is a statistical estimation of error standard deviation calibrated with radiologist inputs. Image rulers for different scan types are used in the inference phase to determine a flexible classification threshold. Our proposed training and inference methods achieve a 89% classification accuracy. The same framework can be used to tune the regularization parameter for compressed-sensing reconstructions.
Introduction
The signal to noise ratio (SNR) of MRIs increases with the number of averages of repetitively acquired data. Oversampling is practiced to achieve higher SNR and better diagnostic quality, especially for relatively fast scans on static body parts. Given the tradeoff between scan time and image quality, we want to find the optimal point to stop a scan. Normally, the number of averages is set before a scan or fixed for all scans. We propose using a neural network (NN) to access a perceptual noise level from radiologists' view and make real-time decisions on when to stop the scan. This saves total scan time and decreases the number of undesired scan outcomes.Previous no-reference noise estimations1-3 are content independent and not particularly perceptual. The same amount of noise has different effects on the diagnostic or perceptual quality of scans with different fat suppression, contrast, and field of view. We propose using a perceptual standard set consistently across all types of scans by a radiologist to calibrate a quantitative noise estimation. A NN 'perceive' images and learn to output the calibrated scores which better correlate with the perceptual noise level. For the inference phase, we propose using adjustable pass/fail thresholds defined by image rulers (Fig.1). The user can pick a desired perceptual noise level for each scan by choosing a sample in the image ruler of the corresponding scan type.
Methods
To construct the training data, we simulate four noisier versions of an MRI slice by adding white Gaussian noises with incremental standard deviations in the k-space. For the training label, we start with two calculated quantities as the initial approximation of the perceptual noise level: the pixel averaged SNR in dB, based on the difference between each noise-injected image and its clean version; the estimated noise standard deviation by iterative estimation in DCT domain (IEDD) method1 from each single image. Then we collect human inputs to roughly calibrate SNR and IEDD using the interface shown in Fig.2. For every five versions of a slice $$$i$$$, a radiologist selects one version $$$h(i)$$$ that meets the minimal desired perceptual noise level for that specific slice. We calibrate/align calculated quantities of all images as follow:$$c=\frac{1}{n}\sum^n_{i=1}y^{h(i)}_i,\hspace{1mm}\hat{\ y}^v_i=y^v_i+c-y^{h(i)}_i,$$where $$$y^v_i$$$ is the original calculated quantity for $$$i$$$th slice $$$v$$$th version.In the inference phase, we present an image ruler — eight versions of a sample slice from a similar scan (Fig.1). The user can indicate the desired level of noise for the upcoming scan by selecting one version in the ruler. The score given by the model on the selected slice is used as the pass/fail threshold. This is motivated by the assumption that the CNN outputs similar value for similar looking images. As new measurements keep coming, images are reconstructed then passed to the model every few seconds until their score reaches the threshold.
Convolutional NNs are competent at capturing perceptual quality4. Our model utilizes a pyramidal CNN with max-poolings and one fully-connected layer to map images to scalar scores. The training objective is the root-mean-square error between the model output and the label.
Results
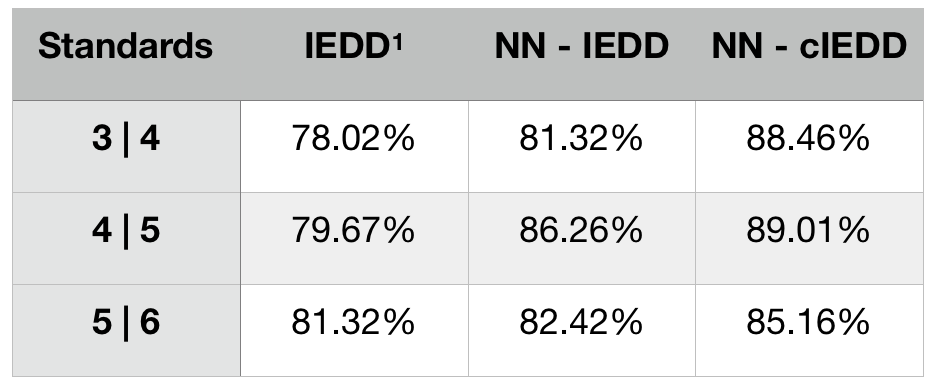
Dataset: All images are from 2D fast-spin-echo scans of knee and elbow with sum-of-squares reconstruction. There are 1250 unique slices(five versions/images each) from 180 objects in the training set and 91 unique slices (two versions/images each) from 20 subjects in the test set. Images in the test set are matched to versions in its corresponding image ruler that appears most similarly noisy. We use two image rulers: fat-suppressed (FS), non-FS. 11,15,18,20,21,17,27,53 of test images are marked as 0-7, respectively.We train our CNN model with four sets of labels: SNR, calibrated SNR (cSNR), IEDD, and calibrated IEDD (cIEDD). Classification accuracies on the default standard (split between 4 and 5 in rulers) from the four models compared with three previous methods1-3 are shown in Tab.1. The calibrated models are better than their counterparts. Our proposed CNN trained with cIEDD, achieves the best performance under the image-ruler-defined-thresholds setting; its confusion matrix is shown in Fig.3. Test accuracies achieved by one fixed threshold that best classifies the test set itself are included in Tab.1. Despite not generalizable to unseen data, most of the accuracies are significantly lower than using ruler-defined thresholds.
We examine the robustness of trained models to changing thresholds on the ruler. Tab.2 shows test accuracies from the same models on three standards. The NN models perform best on the default standard used for validation and calibration. The accuracy drop on other standards is not severe from the calibrated model, and the default is the most commonly used.
Conclusion
We introduced a CNN model to estimate the perceptual noise level of an image and make real-time decisions to stop a scan right after a desired noise level is obtained. The desired noise level can be tailored at inference time by referring to image rulers. Both the proposed human calibration for training label and the ruler-defined thresholds for inference contribute significantly to the classification accuracy.Next, we will expand the dataset, try adding rulers, and deploy the model for clinical use. The same framework can be used for tuning the regularization parameter for compressed-sensing reconstruction.
Acknowledgements
Work in this paper was supported by the NIH R01EB009690 and NIH R01EB026136 award, and GE Precision Healthcare. The labeling interface is developed by Cedric Yue Sik Kin. The MRI raw data is collected at Stanford Lucile Packard Children's Hospital and managed by Marcus Alley.References
1. Ponomarenkoa M, Gaponb N, Voroninb V, Egiazariana K. Blind estimation of white Gaussian noise variance in highly textured images. CoRR, vol. abs/1711.10792, 2017.
2. Liu X, Tanaka M, Okutomi M. Noise level estimation using weak textured patches of a single noisy image. 19th IEEE International Conference on Image Processing, Orlando, FL, 2012, pp. 665-668.
3. Chen G, Zhu F, Heng P. A.. An Efficient Statistical Method for Image Noise Level Estimation. IEEE International Conference on Computer Vision (ICCV), Santiago, 2015, pp. 477-485.
4. Johnson J, Alahi A, Li F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. European Conference on Computer Vision (ECCV), 2016.
Figures
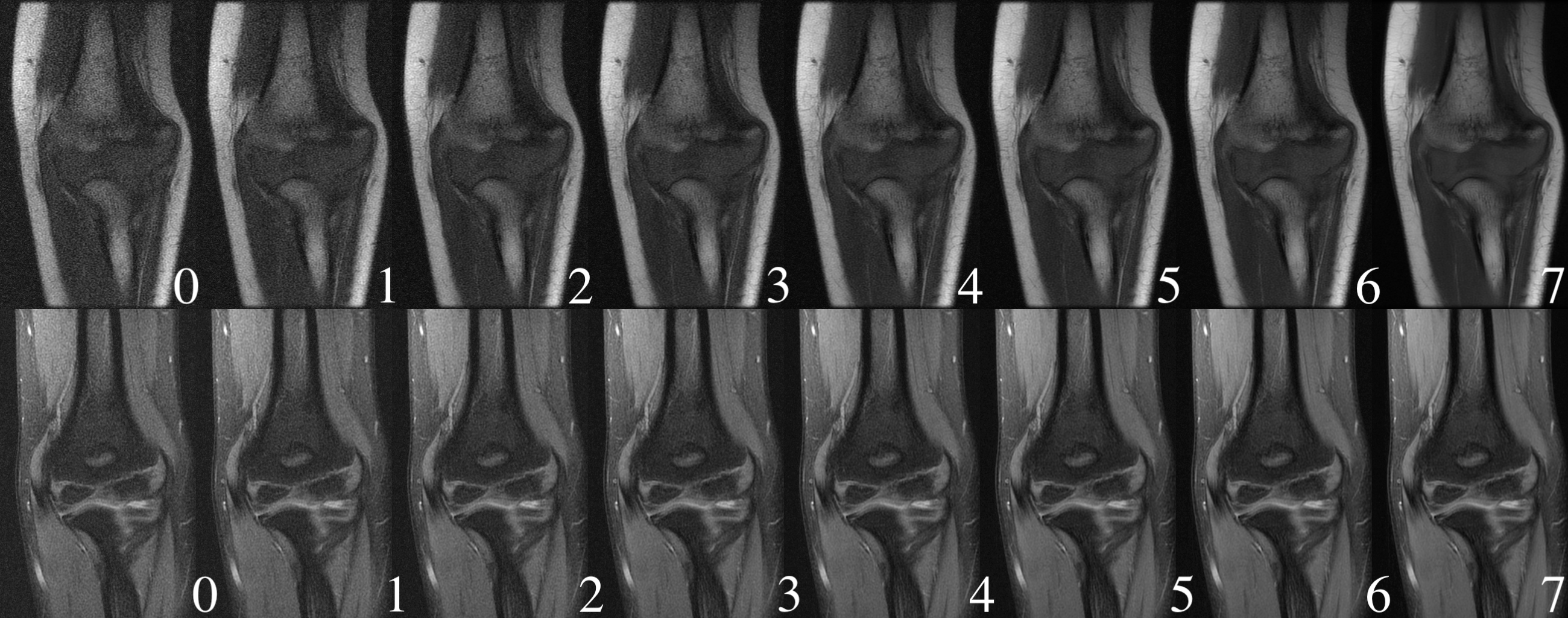
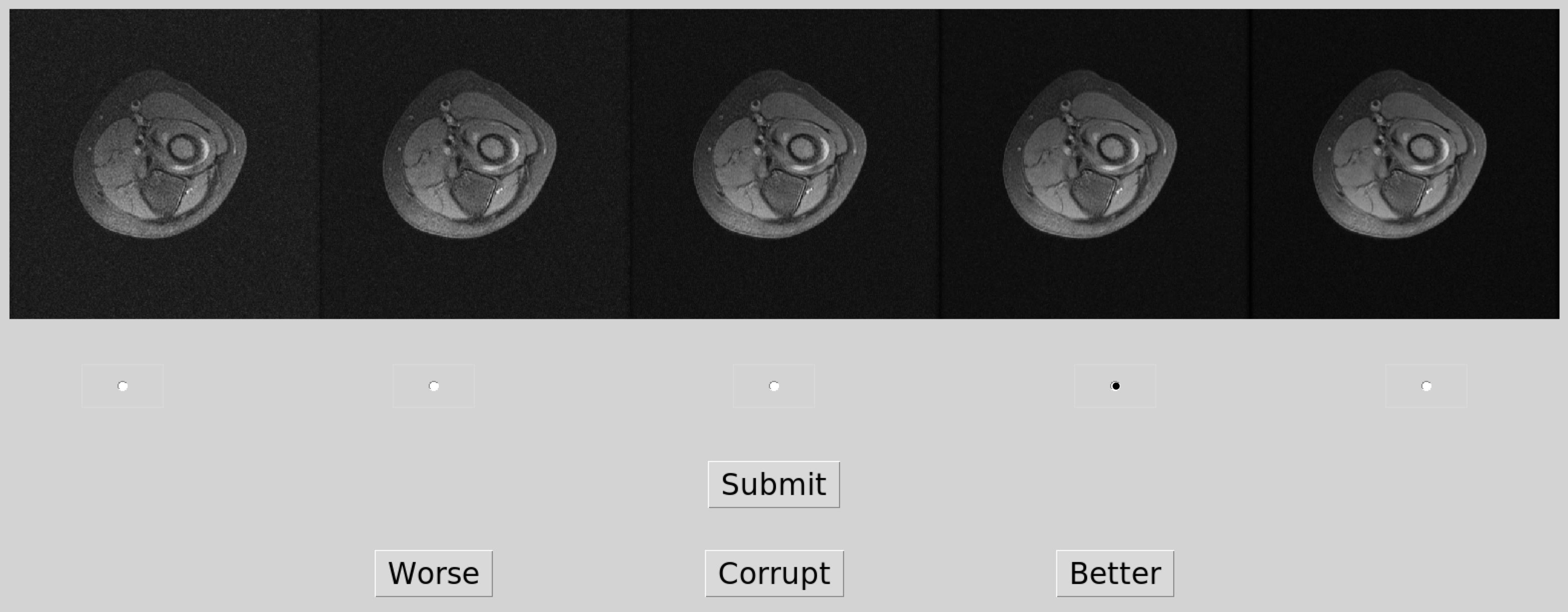
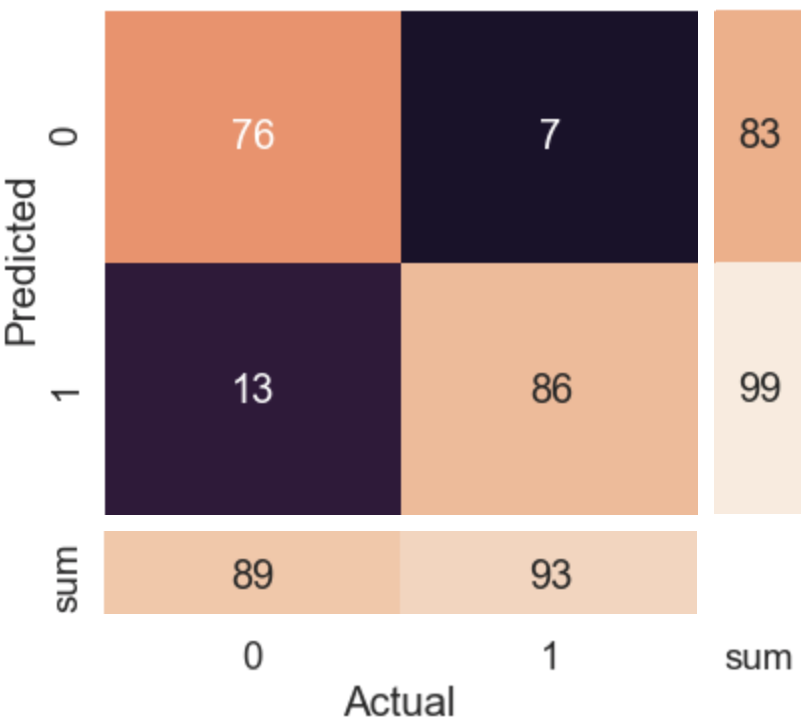

Table 1. Test accuracies of two patch-PCA-based method (i.e. Chen3, Liu2), IEDD1 and our NN model trained with four sets of labels. Inference on the test set is performed with the ruler-defined flexible thresholds (optimized on a small validation set) and a single best threshold (optimized for the exact same test set).