3564
Landmark detection of fetal pose in volumetric MRI via deep reinforcement learning1Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, United States, 2Fetal-Neonatal Neuroimaging and Developmental Science Center, Boston Children’s Hospital, Boston, MA, United States, 3Harvard Medical School, Boston, MA, United States, 4Computer Science and Artificial Intelligence Laboratory (CSAIL), Massachusetts Institute of Technology, Cambridge, MA, United States, 5Institute for Medical Engineering and Science, Massachusetts Institute of Technology, Cambridge, MA, United States
Synopsis
Fetal pose estimation could play an important role in fetal motion tracking or automatic fetal slice prescription by real-time adjustments of the prescribed imaging orientation based on fetal pose and motion patterns. In this abstract, we used a multiple image scale deep reinforcement learning method (DQN) to train an agent finding the target landmark of fetal pose by optimizing searching policy based on landmark features and its surroundings. Under an error tolerance of 15-mm, the detection accuracy reaches 58%.
Introduction
Fetal Pose Estimation in MRI is helpful for fetal motion tracking and automatic fetal slice prescription by real-time adjustments of the prescribed imaging orientation based on fetal pose and motion patterns. An ongoing study of placenta1 with EPI time series (110 subjects, 300-500 EPI volumes each, 20-30 minute observations) yields over 44,000 volumes upon which fetal pose estimation models can be trained. Deep neural networks for fetal pose estimation have demonstrated success on the aforementioned data2. However, this method relies heavily on the feature extracting ability of the neural network as only locations of pose landmarks are used. In this work we draw on applications of deep reinforcement learning method(DQN)3 to train an agent to find the target landmark of fetal pose by learning both searching strategy and features of the target landmark.Under an error tolerance of 15mm, the detection accuracy reaches 58%.Method
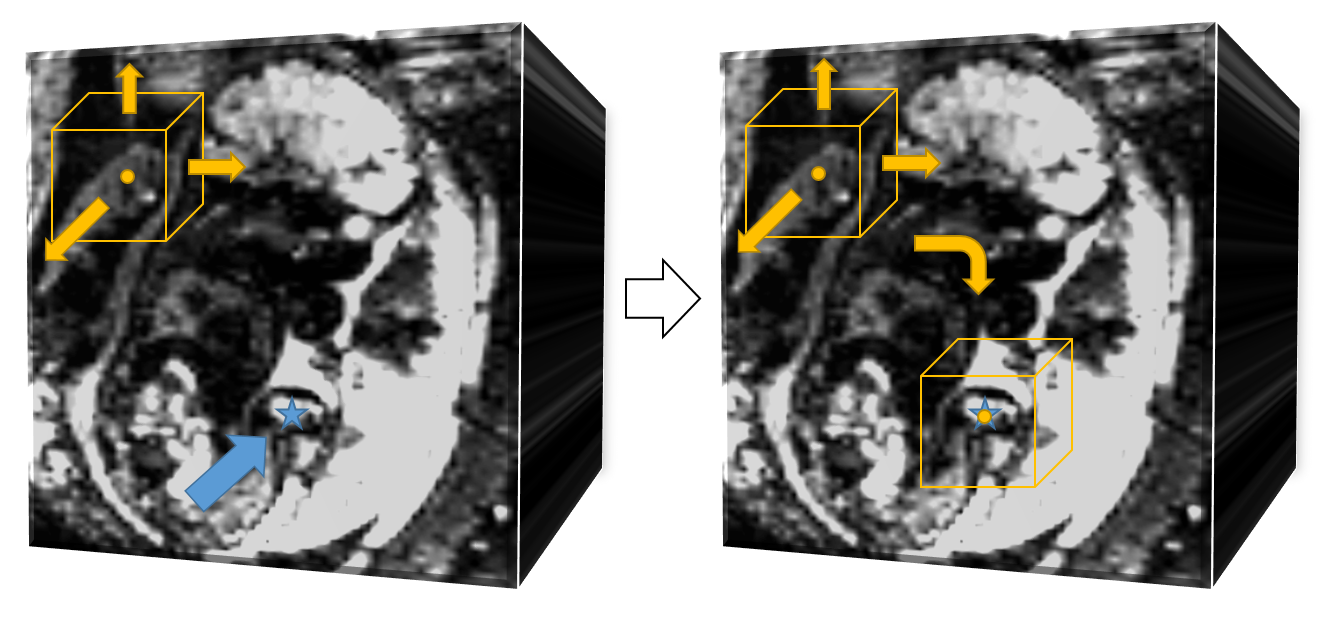
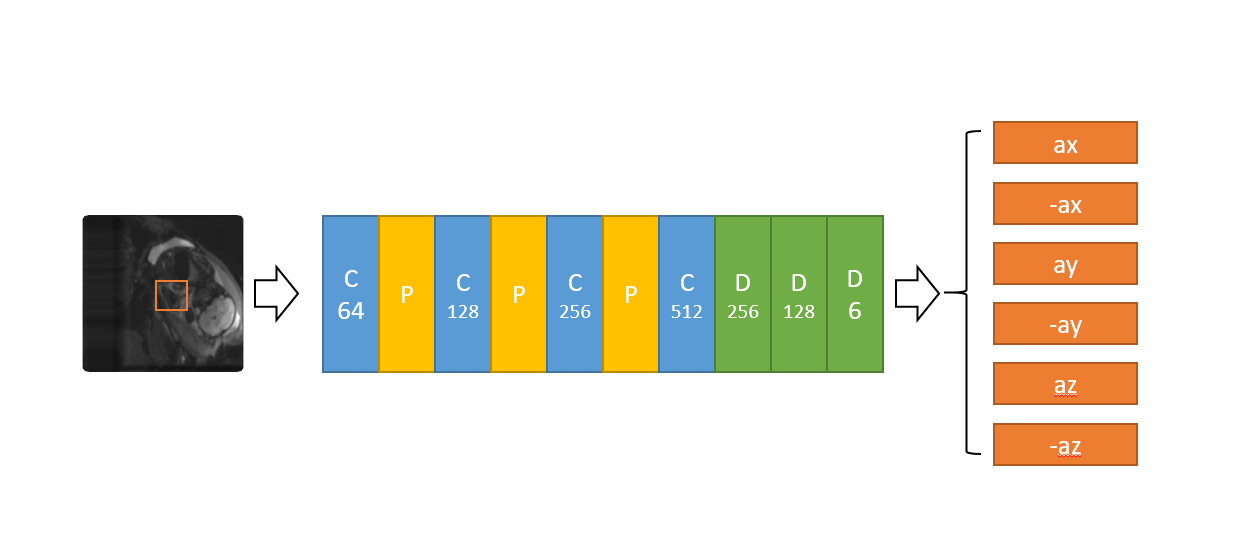
Q-learning in Reinforcement learning is an interactive learning process between agent and environment. At each state, the agent will take actions based on a corresponding Q-table. Then it will get a reward from the environment to update the Q-table based on this state. For MRI images, it’s not sufficient to take correct action only using the Q-table. Thus we used Deep Q learning where a deep neural network is applied to analyze contents and features of images and to take actions. Deep Q learning has been used for medical imaging landmark detection, achieving high detection accuracy and speed.As shown in Figure 1, the agent is a searching point in the whole 3D fetal MRI image, the state is the surrounding image of 32 x 32 x 32 voxels with the agent at the center. The set of actions is composed of six moving direction, {x direction: -step size, +step size; y direction: -step size, +step size, -step size, + step size}. The deep neural network taking actions consists of multiple convolutional layers and pooling layers for feature extraction in various scales (Figure 2).
The reward for training DQN to take correct action at current state $$$s$$$ is determined by the distance between current location of the agent and target landmark, $$$d(s,t)$$$. The reward for each action is defined by $$$ r(s,a) = d(s,t+1)-d(s,t)$$$.
During training, we adopted multi-scale searching strategy as used in previous works4. The agent first performs a coarse search in a down-sampled image in which the agent could get an overall view of fetal body structure. The second scale is in the original image which maintains the details of the target pose landmark. The search is terminated if the agent is oscillating in one place or getting close enough to the target landmark. During testing, oscillating is the only terminating state as the target landmark location is unknown.
We used the basic TD error as the training loss and Adam optimizer to optimize the network parameters. The learning rate decayed to half after every 5000 episode from the initial starting leaning rate of 1e-6.
For evaluating the performance of our deep reinforcement learning method, we used the Percentage of Correct Keypoint (PCK) metric. $$$PCK(r)$$$ is defined as the percentage of distance between location of agent at terminating state and location of ground truth less than r.
Results and Discussion
In this work, we aided training convergence by considering the simple situation of fixing the bladder as the as initial starting point which is a stable feature in low-resolution EPI images. We only search for the fetal right knee to illustrate the feasibility of deep reinforcement learning in landmark detection of fetal pose.The multi-slice EPI (matrix size ~100*100*80, resolution = 3mm*3mm*3mm, TR = 3.5s) data were acquired with IRB approval on pregnant women with fetuses at gestational age between 25 and 35 weeks. We labeled 20000; 12000 were used for training and 8000 for testing.
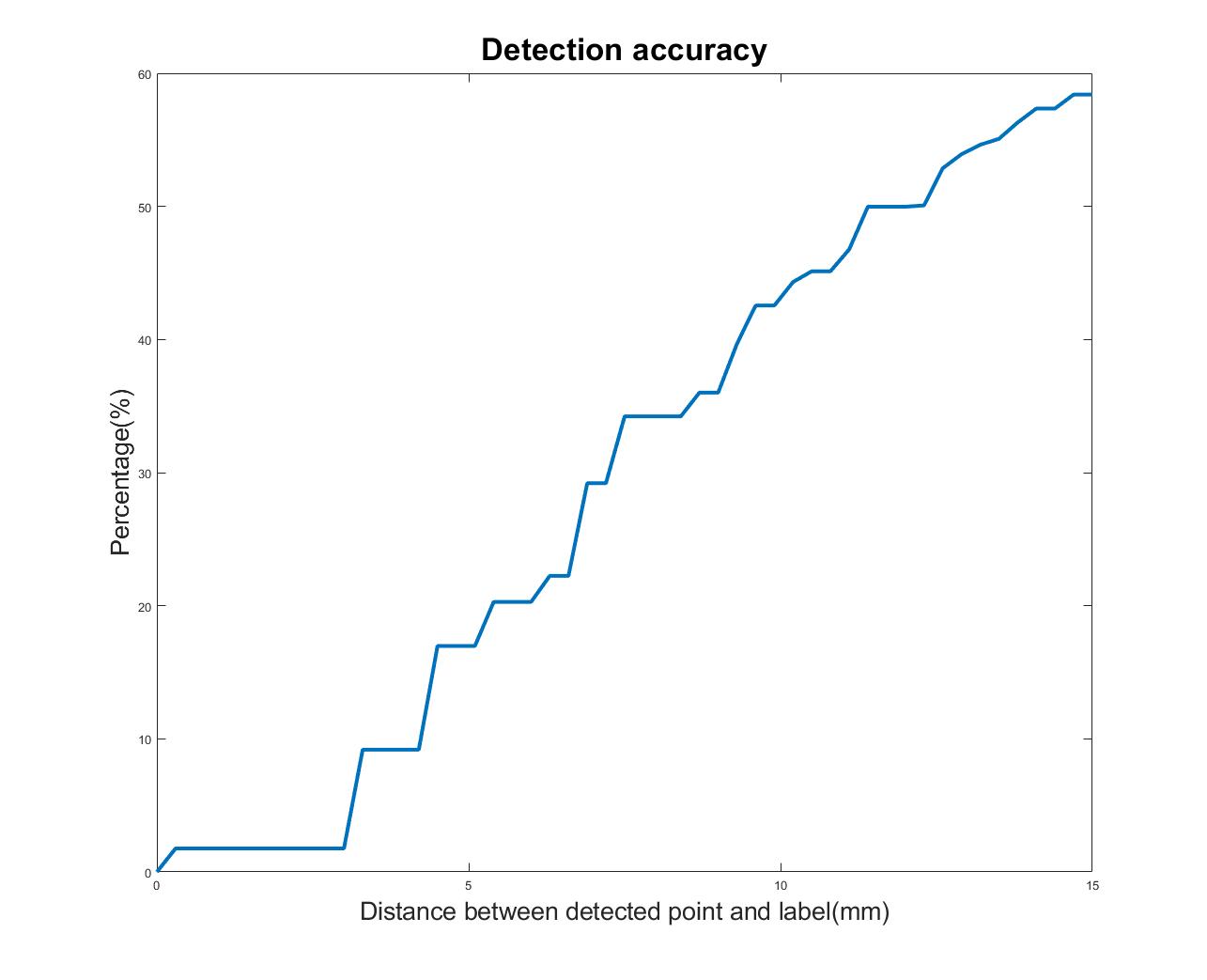
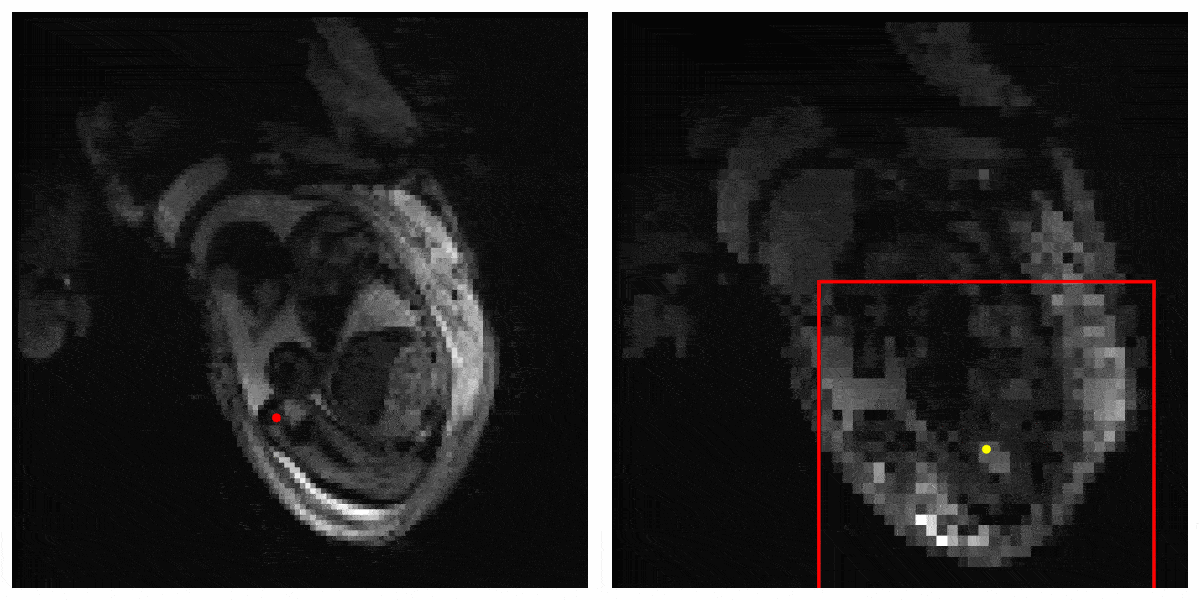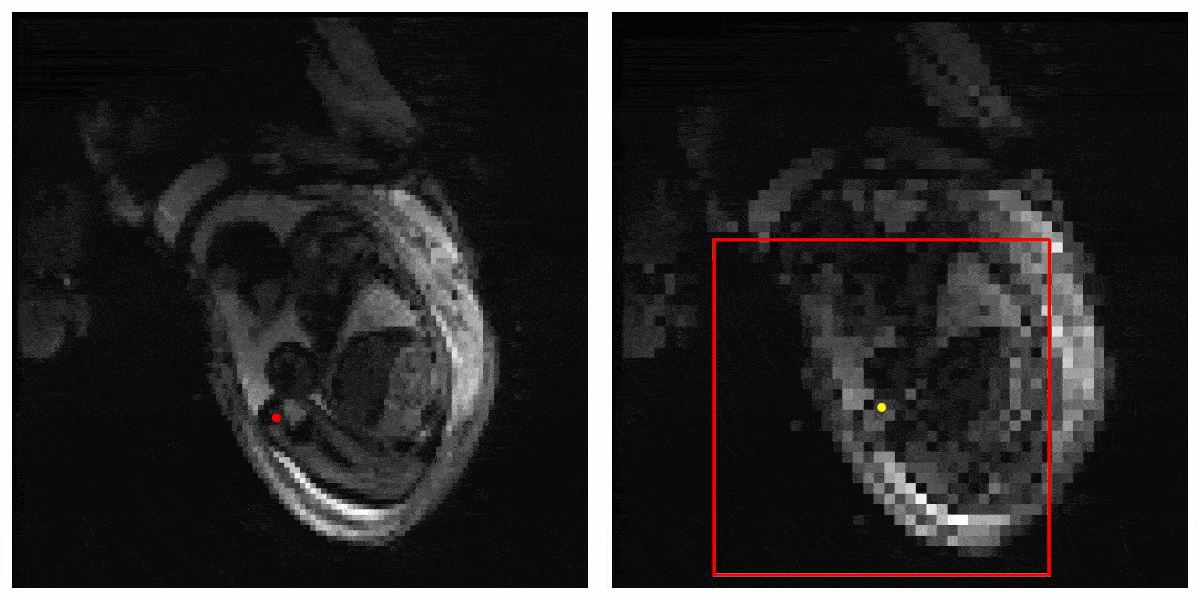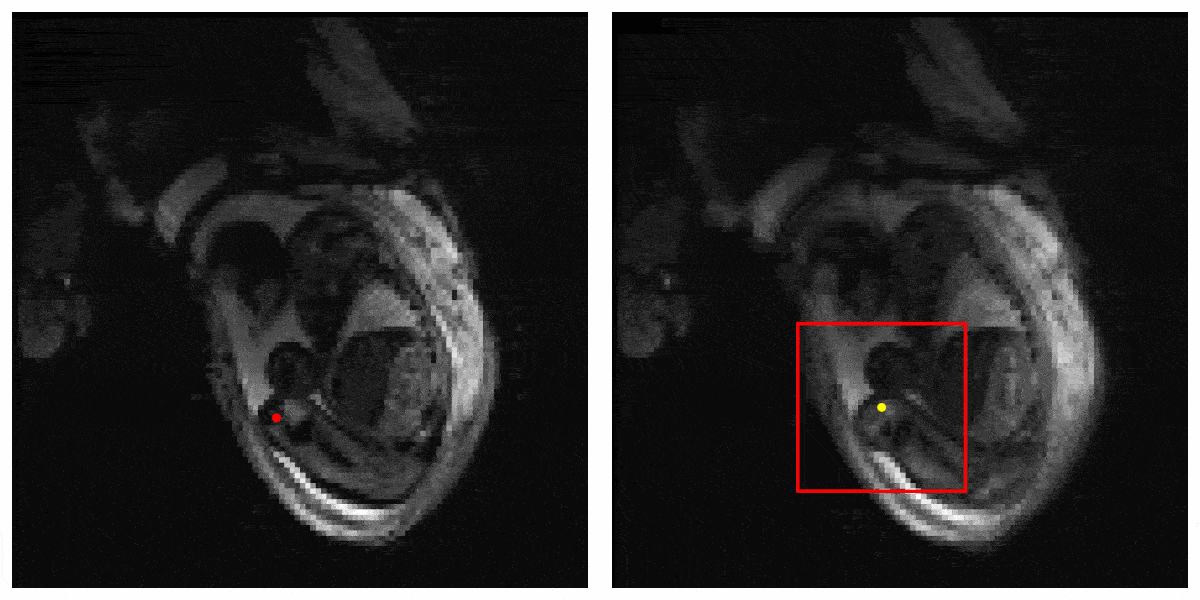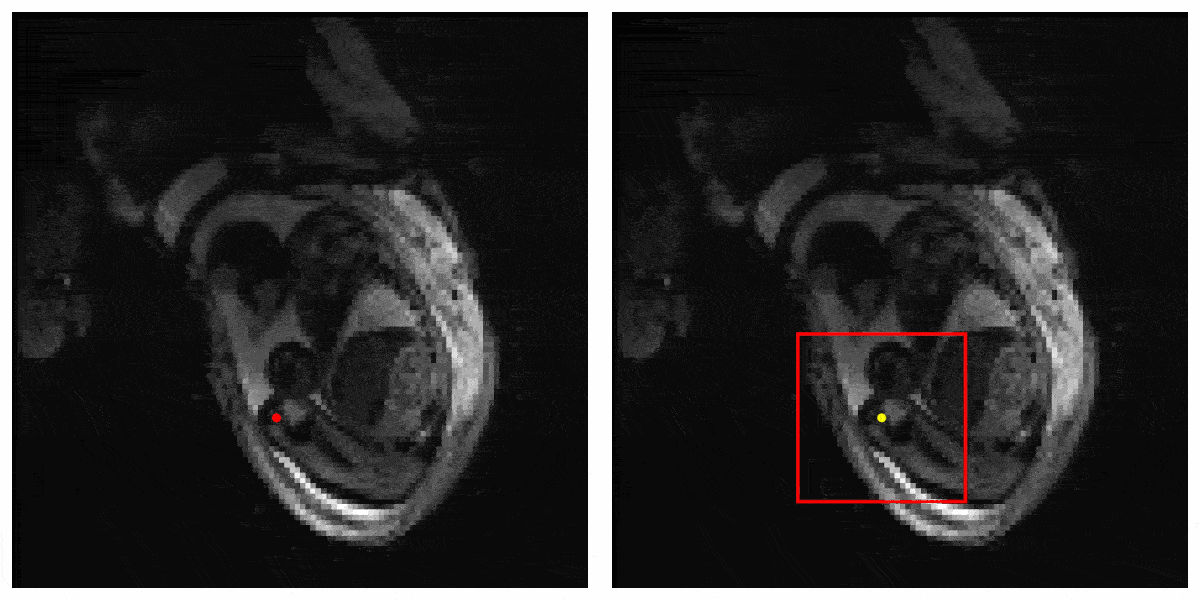
Figure 3 shows the result of our Deep Q learning method. Under an error tolerance of 15mm, the accuracy reaches 58%. It shows the potential of Deep Q learning in handling fetal pose landmark detection. Figure 4 is an illustration of detection process during testing.
Conclusions
Deep reinforcement learning shows its potential usage in fetal landmark pose detection. As fetuses are not rigid, finding landmarks of pose is more difficult than traditional landmark detection where images could be registered first. Our reinforcement learning model could learn the searching strategy and features of landmark during training. Future work will explore full usage of reward designing on bone structures which are more stable as well as multi-agent models to find multiple landmarks at the same time.Acknowledgements
NIH R01 EB017337, U01 HD087211, R01HD100009 and Nvidia.References
1. Luo J, Abaci Turk E, Bibbo C, Gagoski B, Roberts DJ, Vangel M, et al. In Vivo Quantification of Placental Insufficiency by BOLD MRI: A Human Study. Sci Rep 2017;7:3713.
2. Xu, Junshen, et al. "Fetal Pose Estimation in Volumetric MRI Using a 3D Convolution Neural Network." International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2019.
3. Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
4.Alansary, Amir, et al. "Evaluating reinforcement learning agents for anatomical landmark detection." Medical image analysis 53 (2019): 156-164.
Figures