3546
A Self-Regularized and Over-Determined Deep Network for Cranial Pseudo-CT Generation1Hong Kong Sanatorium & Hospital, Hong Kong, Hong Kong
Synopsis
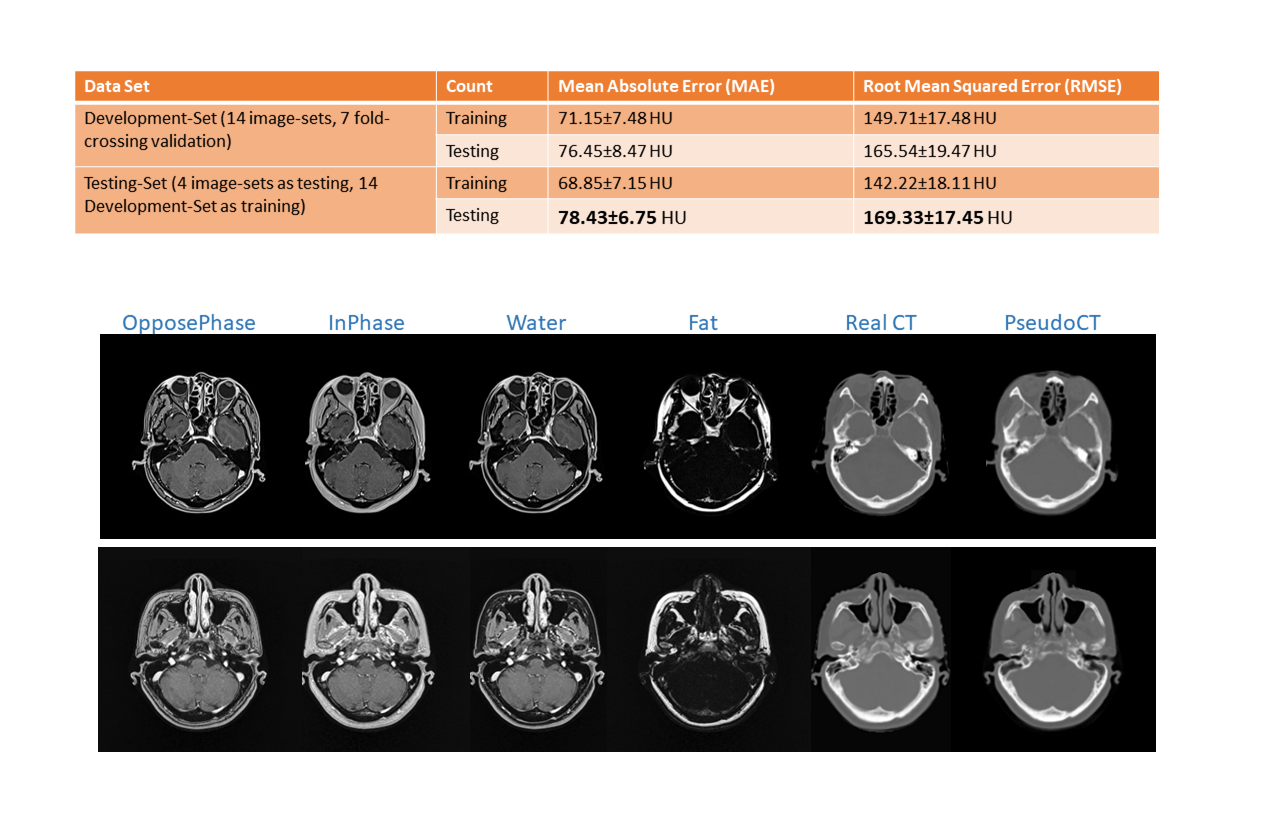
This study presented a hyperparameter-free deep network modal for cranial pseudo-CT generation. The model was potentially universal to various scanning machines without the need of network hyperparameter adjustment and could handle testing images from MR- and CT-simulators different from the training data. It is beneficial to perform clinical trial in institutions where multiple MR- and CT-machines are in operations, without supervision by deep learning experts. The proposed model was examined using training and testing datasets acquired from two sets of MR- and CT-simulators, showing promising accuracy, <79 mean-absolute-error and <170 root-mean-squared-error.
Purpose
To present a deep network model that required no heuristic tuning of model hyperparameter for cranial pseudo-CT generation. Mathematically, the model automatically regularized network weights, a unique benefit from over-determined network construction. It possessed no bias towards the MR- and CT-simulators used for training data acquisitions. Therefore, it could be applied to various scanning machines without hyperparameter adjustment, distinct from most existing approaches. This advantage was experimentally shown by using testing set acquired from different MR- and CT- simulators than training data.Methods
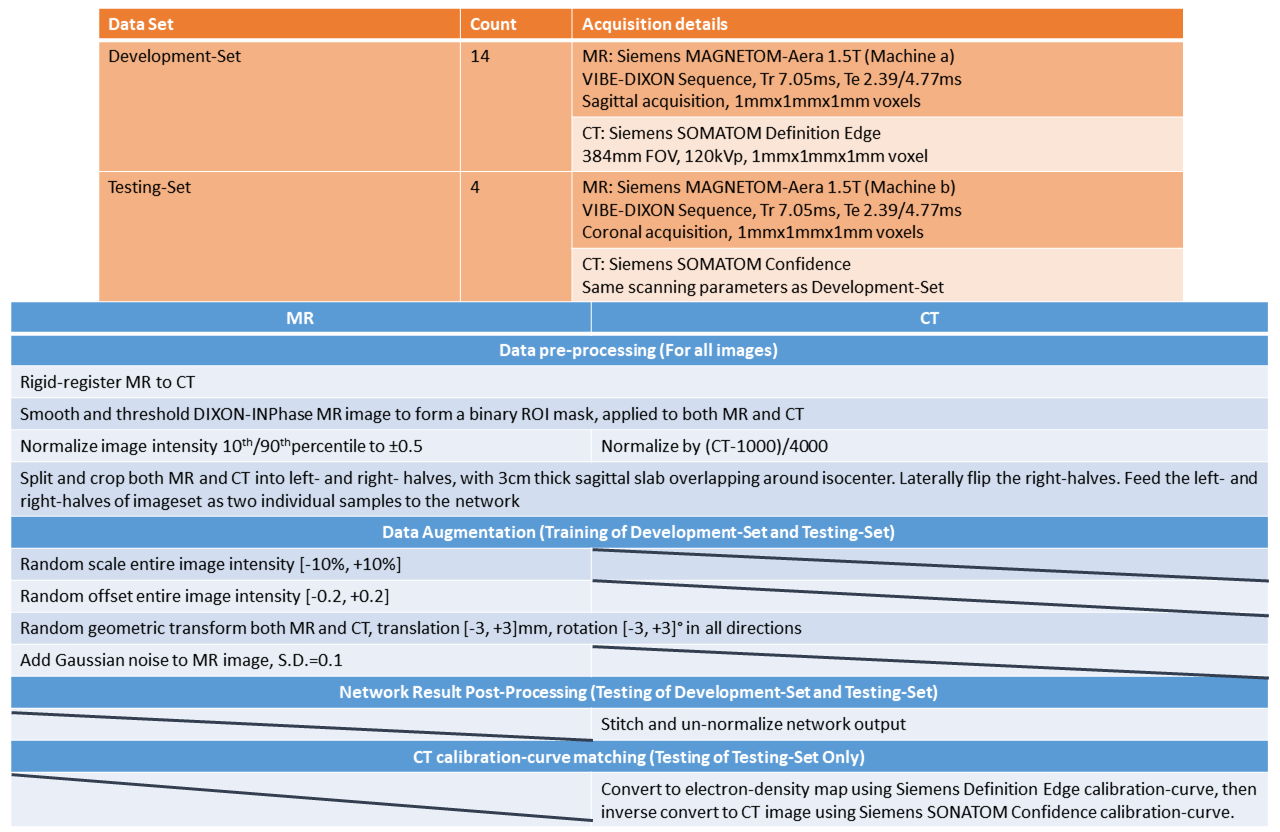
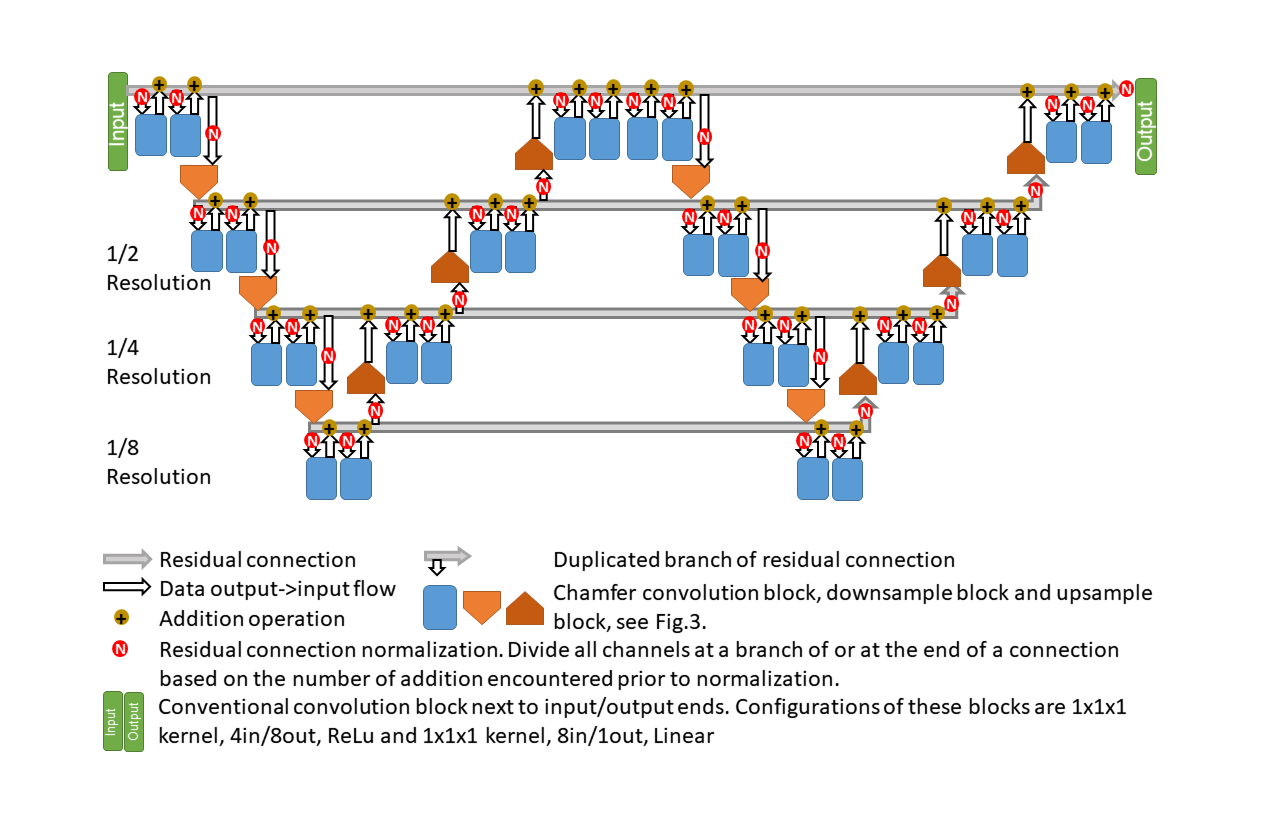
18 patients diagnosed to have tumors in Head-and-Neck regions and prescribed to receive radiotherapy were recruited (Fig.1-Top). They underwent same-day CT- and MR-simulation using thermoplastic casts for immobilization during simulations and treatments. These 18 sets of data were divided into Development-Set and Testing-Set, according to which MR- and CT-simulators the images were acquired from. The images were registered, normalized and cropped prior to feeding to the network (Fig.1-Bottom).While the network model was being designed, intermediate testing results were obtained using 7-fold cross-validation only on Development-Set. The entire Testing-Set and information regarding the corresponding simulators were isolated from the network design and training. After the network was finalized (Figs.2 and 3), the entire Development-Set served as training for Testing-Set experiments. The pseudo-CT generated from Testing-Set was converted to match the calibration of groundtruth CT-images in Testing-Set for accuracy evaluation (Fig.1-Bottom).
Results
The results obtained from Development-Set and Testing-Set were shown in Fig.4. The discrepancies among all training and testing MAE for both Development-Set and Testing-Set were minor (~10 HU), suggesting that the self-regularized network remarkably avoided overfitting. Its outstanding performance was also unaffected by the difference between the simulators employed for Development-Set and Testing-Set acquisitions. The <79 HU MAE and <170 HU RMSE testing accuracies were comparable to previously published studies. Fig.4-Bottom presented slices containing multiple tissue-types which had dissimilar CT number: soft-tissue, cortical-bone, trabecular-bone and air-cavity. The proposed method successfully reconstructed CT images despite of the ambiguous tissue intensity in MR images.Discussions
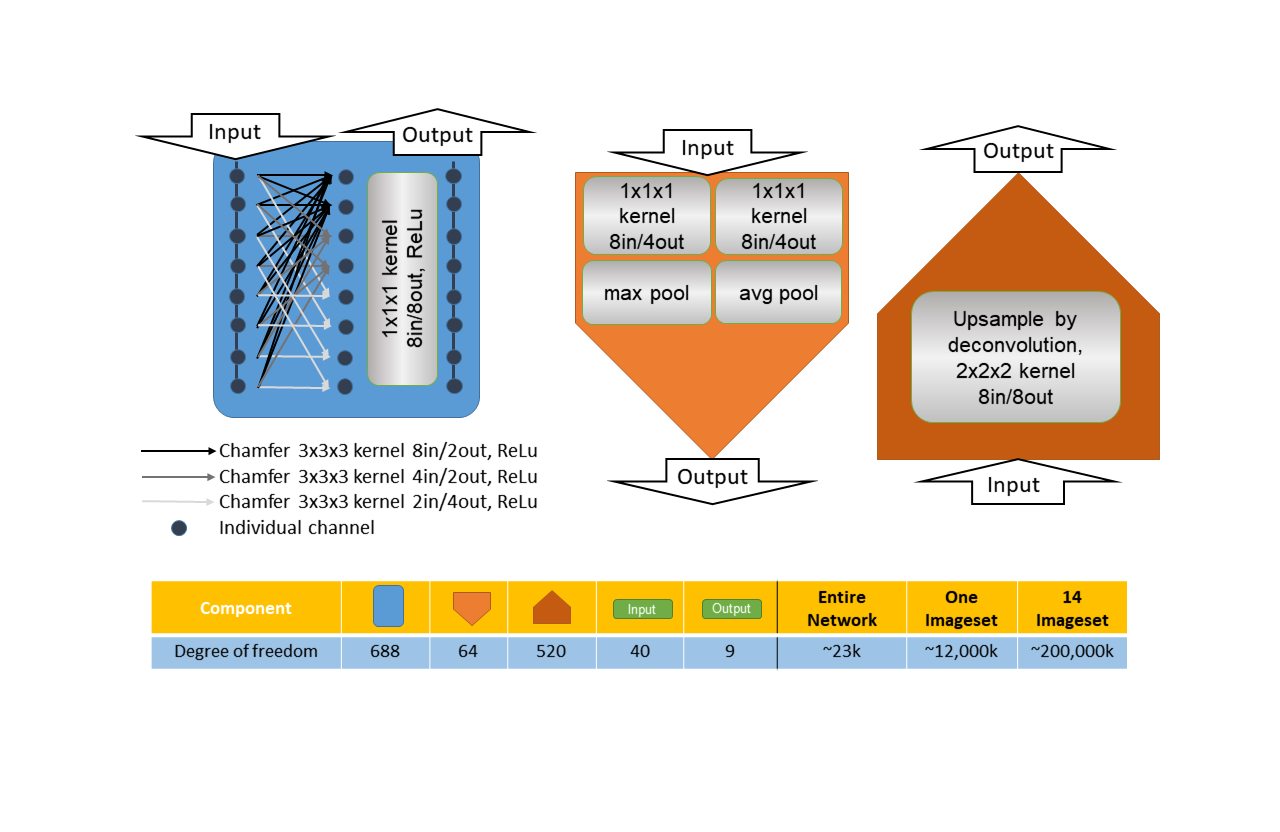
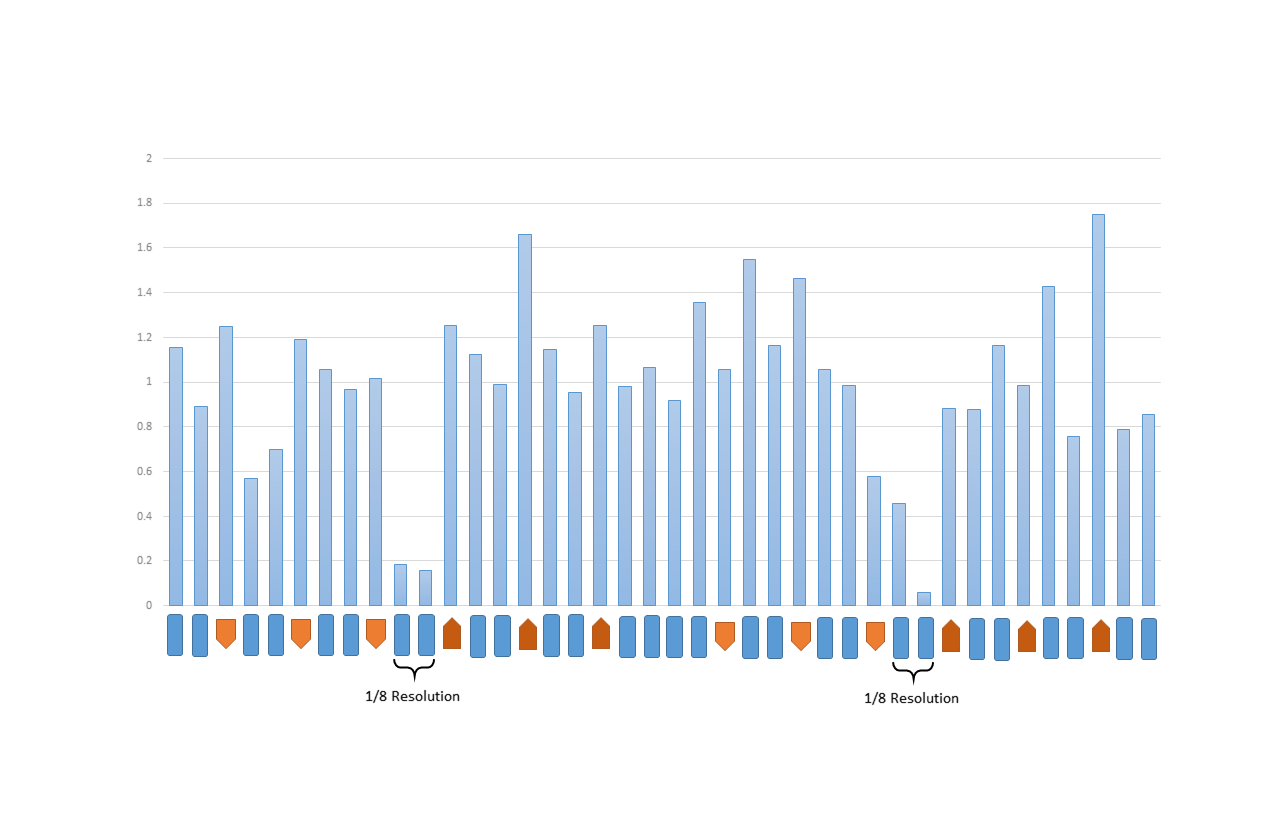
The network was constructed using minimal, approximately 23k of trainable weights. It was <0.02% of foreground voxels of a complete training set (Fig.3-Bottom), one-third [Dinkla et al.] to one-thousandth [Han] of published approaches. It was an over-determined system that naturally avoided over-fitting [Springenberg et al.]. In addition, no block could dominate the network (Fig.5), exhibiting self-regularization. It was because a small subset of blocks dominating the network further reduced the number of effective weights. The network also successfully identified and suppressed less-contributing blocks (1/8 Resolution blocks in Fig.5). Both self-regularization and suppressing counter-productive weights were benefits of adding block outputs directly to residual connections [He et al. 2] without batch-normalization.The network had a great variety of block-types (Fig.3-Top), kernel sizes (Fig.3-Top), resolution levels (Fig.2) and residual connections (Fig.2). They operated in synergy and constituted complimentary forms of data non-linearity, leading to a highly descriptive network using minimal number of weights. Weight initialization [He et al.] and residual connection normalization (Fig.2) also rigorously maintained the gains of every network block regardless of the data passing through the network, as opposed to batch-normalization. Both the performance and theoretical grounding of this over-determined network were fundamentally different from existing lightweight networks [Howard et al., Hasanpour et al.] which possessed lower degree of variety and utilized batch-normalization. The associated mathematical prove will be published in due course.
In data preparation of MR images for deep learning analysis, the efficacy of conventional intensity normalization significantly influenced by intensity levels of both of the darkest and brightness tissues presented in an image or image patch. The outcome of normalization could be undesirable owing to inconsistency of MR tissue-intensity across image-regions/scans/scanners. As a part of data augmentation (Fig.1-Bottom), we randomly altered MR brightness and contrast after image intensity normalization to grant the network robustness against MR intensity inconsistency. The effect was remarkable and echoed in the outstanding performance in the experiment based on Testing-Set, despite of the difference on the imaging machines between Development-Set and Testing-Set.
The self-regularization, over-determined nature and robustness against MR intensity inconsistency were always valid regardless of optimizer initial time-step, the only parameter required by the proposed network. It was recommended to be the largest possible [Hoffer et al.]value without causing exploding-gradient (0.004 in experiments). On one hand no model hyperparameter presented that no heuristic network tuning was needed to kick-start the model. On the other hand the model could be universal for different scanning machines based on similar time-step values.
Conclusions
A hyperparameter-free deep network modal was proposed to generate cranial pseudo-CT. No network hyperparameter tuning was required, thus very beneficial to perform clinical trials when deep learning expert absents. It offered promising accuracy when the testing data was acquired from different MR- and CT-simulators from the training samples. The proposed model well-suited institutions where multiple CT- and MR-simulators are in operations. The next step will inspect the dosimetric impact of substituting real-CT with pseudo-CT. One may also consider training/generating pseudo-Electron-Density images instead of pseudo-CT, coupling with the robustness against MR intensity inconsistency of the proposed network, to fully enable training using a large image cohort collected from different MR- and CT-simulators.Acknowledgements
No Acknowledgement
References
[Hoffer et al.] E. Hoffer, I. Hubara, D. Soudry, "Train longer, generalize better: closing the generalization gap in large batch training of neural networks", Advances in Neural Information Processing Systems (NIPS 2017)
[Tryggestad et al.] E. Tryggestad, M. Christian, E. Ford, C. Kut, Y. Le, G. Sanguineti, D.Y. Song, L. Kleinberg,"Inter- and Intrafraction Patient Positioning Uncertainties for Intracranial Radiotherapy: A Study of Four Frameless, Thermoplastic Mask-Based Immobilization Strategies Using Daily Cone-Beam CT", Int J Radiat Oncol Biol Phys. 2011 May 80(1):281-90
[Springenberg et al.] J.T. Springenberg, A. Dosovitskiy, T. Brox, M. Riedmiller, "Striving For Simplicity: The All Convolutional Net", ICLR Workshop 2015
[He et al.] K. He, X. Zhang, S. Ren and J. Sun, "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification", Computer Vision and Pattern Recognition (CVPR 2015)
[Hasanpour et al.] S.H. Hasanpour, M.Rouhani, M. Fayyaz, M. Sabokrou and E. Adeli, "Towards Principled Design of Deep Convolutional Networks: Introducing SimpNet", CoRR 2018, ePrint 1802.06205
[Han] X. Han, "MR-based Synthetic CT Generation using a Deep Convolutional Neural Network method", Med Phys. 2017 Apr 44(4):1408-1419
[Dinkla et al.] A.M. Dinkla, J.M. Wolterink, M. Maspero, M.H.F. Savenije, J.J.C. Verhoeff, E. Seravalli, I. Isgum, P.R. Seevinck and C.A.T. van den Berg, “MR-Only Brain Radiation Therapy: Dosimetric Evaluation of Synthetic CTs Generated by a Dilated Convolutional Neural Network”, Intl. J. Rad. Onco. Bio. Phy. 2018 Nov 102(4):801-812
[Howard et al.] A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”
[He et al. 2] K. He, X. Zhang, S. Ren and J. Sun, “Deep Residual Learning for Image Recognition”, Computer Vision and Pattern Recognition (CVPR 2015)
Figures