3541
A Lightweight deep learning network for MR image super-resolution using separable 3D convolutional neural networks
Li Huang1, Xueming Zou1,2,3, and Tao Zhang1,2,3
1School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, China, 2Key Laboratory for Neuroinformation, Ministry of Education, Chengdu, China, 3High Field Magnetic Resonance Brain Imaging Laboratory of Sichuan, Chengdu, China
1School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu, China, 2Key Laboratory for Neuroinformation, Ministry of Education, Chengdu, China, 3High Field Magnetic Resonance Brain Imaging Laboratory of Sichuan, Chengdu, China
Synopsis
The existing deep learning networks for MR super-resolution image reconstruction using standard 3D convolutional neural networks typically require a huge amount of parameters and thus excessive computational complexity. This has restricted the development of deeper neural networks for better performance. Here we propose a lightweight separable 3D convolution neural network for MR image super-resolution. Results show that our method can not only greatly reduce the amount of parameters and computational complexity but also improve the performance of image super-resolution.
Introduction
Single image super-resolution (SISR) reconstruction technique for magnetic resonance (MR) images aims to reconstruct a high-resolution (HR) MR image from a low-resolution (LR) MR image. It improves the resolution of three-dimensional (3D) MR images while balancing the resolution, signal-to-noise ratio (SNR) and acquistion time, which is considered as an valuable alternative to directly obtain high-resolution 3D MR images substantially increasing scanning time. With the development of convolution neural networks (CNNs), SISR technology based on deep learning has achieved good results in 3d MRI image. Howerver, the existing deep learning networks typically use standard 3d convolution to extract 3d structure information from images, which requires a huge amount of parameters and results in excessive computational complexity. This problem has prevented us from building a deeper and more sophisticated neural network for better super-resolution performance. Therefore, reducing the number of parameters and the amount of computational complexity while improving the super-resolution reconstruction performance remains as a key challenge for 3D MR image super-resolution.Methods
As shown in Figure 1, we replace the original standard 3D convolution with a module called "separable 3D convolution", which separates the convolution of a 3x3x3 into the parallel or series forms of a 1x3x3 convolution and a 3x1x1 convolution. Two different types of S3D modules are depicted in Figure 1, named as S3D-A and S3D-B respectively. The number of parameters (Params) and floating-point operations (FLOPs) are used to represent the spatial complexity and time complexity of the algorithm. Figure 2 compares the proposed S3D-A, S3D-B and the standard 3D convolution neural network in terms of Params and FLOPs, assuming all input and output feature map channels are 64 and the size of each input is 24×24×24. It can be seen that the S3D-A and S3D-B can greatly reduce the number of parameters and calculations by more than 50 percent. One big advantage is that the computational complexity and time can be greatly reduced which allow to build a deeper model for a direct 3D MRI SR network for better performance while using limited computing resources.As shown in Figure 3, we designed a deep neural network based on S3D (separable 3D) module for 3D MRI super-resolution reconstruction. The proposed network can be divided into three parts, feature extraction, nonlinear mapping, and image reconstruction.
- Feature extraction: The feature extraction network contains two convolution layers with a convolution layer in the middle. The convolution layer works as a point-to-point linear transformation of the feature map of the first convolution layer for enhancing the robustness of the extracted features. The feature extraction network transforms the input as a set of shallow features.
- Nonlinear mapping: The input of the nonlinear mapping network is the shallow feature extracted by the feature extraction network. Here we put S3D-A and S3D-B into the residual block in EDSR4 and name as S3D-ResBlock”. The S3D-ResBlock contains a S3D-A block and a S3D-B block with the ReLU activation function in the middle. The entire nonlinear mapping network includes ten S3D-ResBlocks.
- Image Reconstruction: This is only one 3x3x3 convolution for restoring HR images.
Results and Discussion
The validation PSNR(dB) curves are shown in Figure 4a. For quantitative comparison, the PSNR and SSIM are used to evaluate the performance of each model and Params and FLOPs are also listed in Figure 4b. Apparently the proposed method not only has less Params and FLOPS but also has a certain improvement in performance (+0.20dB PSNR). This proves that the proposed method is more suitable for 3D MRI SR than conventional standard 3D convolution. Figure 5 shows the visual effect comparison of different models.Conclusion
The proposed separable 3D convolutional neural network is a lightweight deep learning network with much reduced number of parameters and computational complexity. This will allow us to develop deeper neural networks for better performance in regard to 3D MR super-resolution.Acknowledgements
The work is supported in part by School of Life Science and Technology, University of Electronic Science and Technology of China.References
- Pham C H, Ducournau A, Fablet R, et al. Brain MRI super-resolution using deep 3D convolutional networks[C]// 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017). IEEE, 2017.
- Pham C H, Tor-Díez C, Meunier H, et al. Multiscale brain MRI super-resolution using deep 3D convolutional networks[J]. Computerized Medical Imaging and Graphics, 2019, 77: 101647.
- Lim B, Son S, Kim H, et al. Enhanced Deep Residual Networks for Single Image Super-Resolution[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2017.
- B. A. Landman, A. J. Huang, A. Gifford, D. S Vikram, I. A. L. Lim, J. AD. Farrell, J. A Bogovic, J. Hua, M. Chen, S. Jarso, et al., “Multi-parametric neuroimaging reproducibility: a 3-t resource study,” Neuroimage, vol. 54, no. 4, pp. 2854–2866, 2011.
- Shi F, Cheng J, J, ng L, et al. LRTV: MR Image Super-Resolution with Low-Rank and Total Variation Regularizations[J]. IEEE Transactions on Medical Imaging, 2015, 34(12):1-1.
Figures
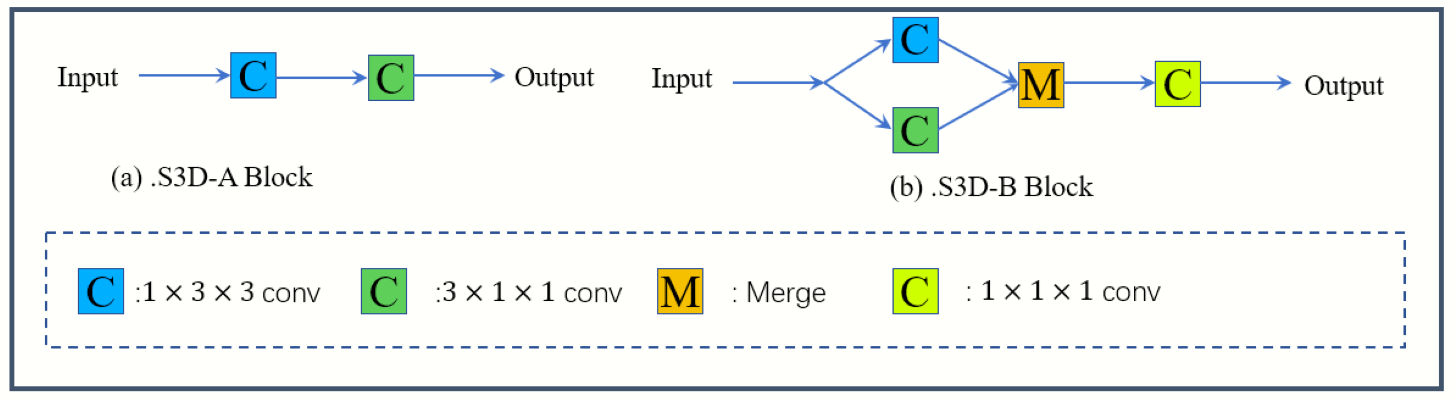
Fig.1
The architecture of the proposed S3D-A (a) block and
S3D-B (b) block.
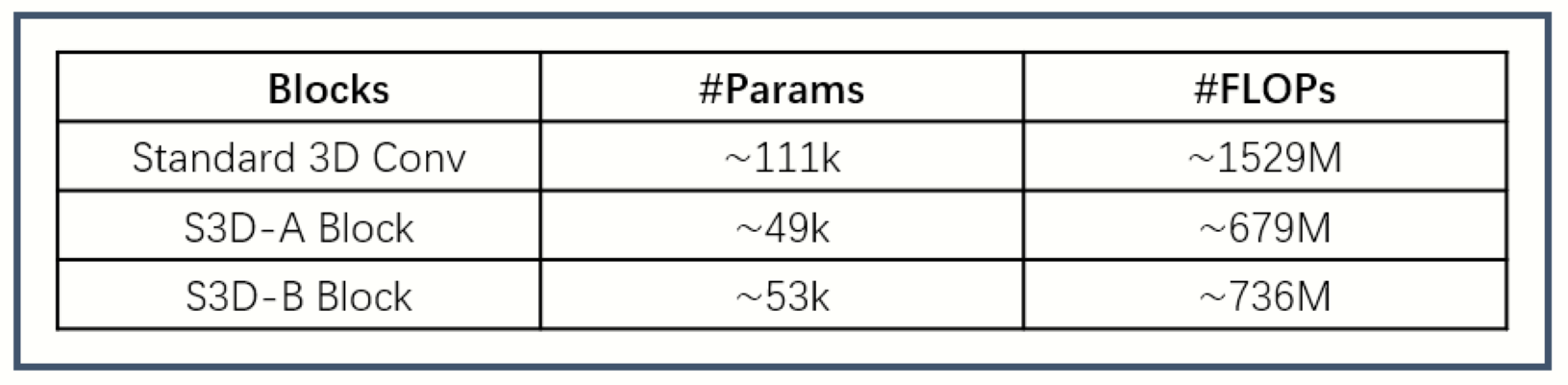
Fig.2 #Params
and #FLOPs comparisons of S3D-A Block(Fig 1.a), S3D-B(Fig 1.b) and
Standard 3D Conv.
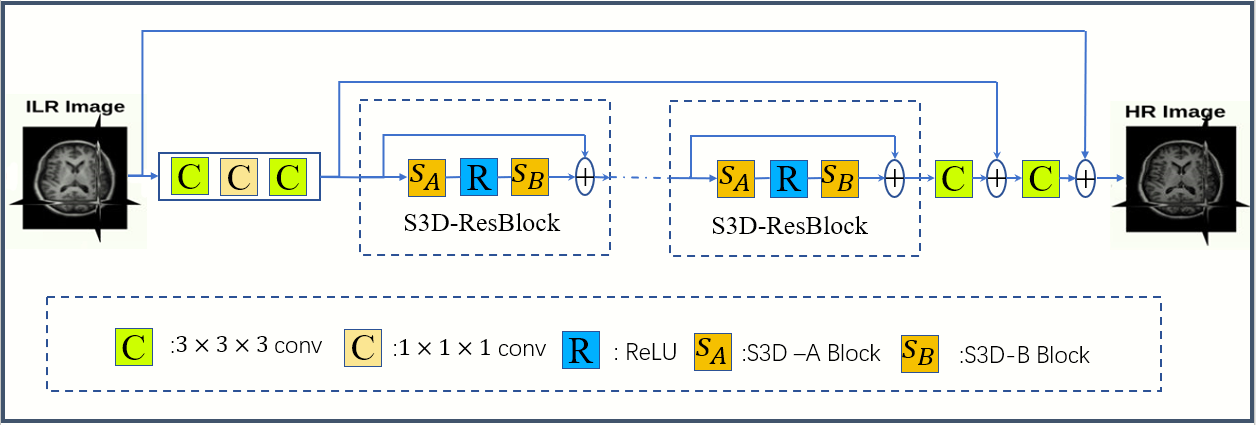
Fig.3
The architecture of the proposed deep separable 3D convolutional networks.
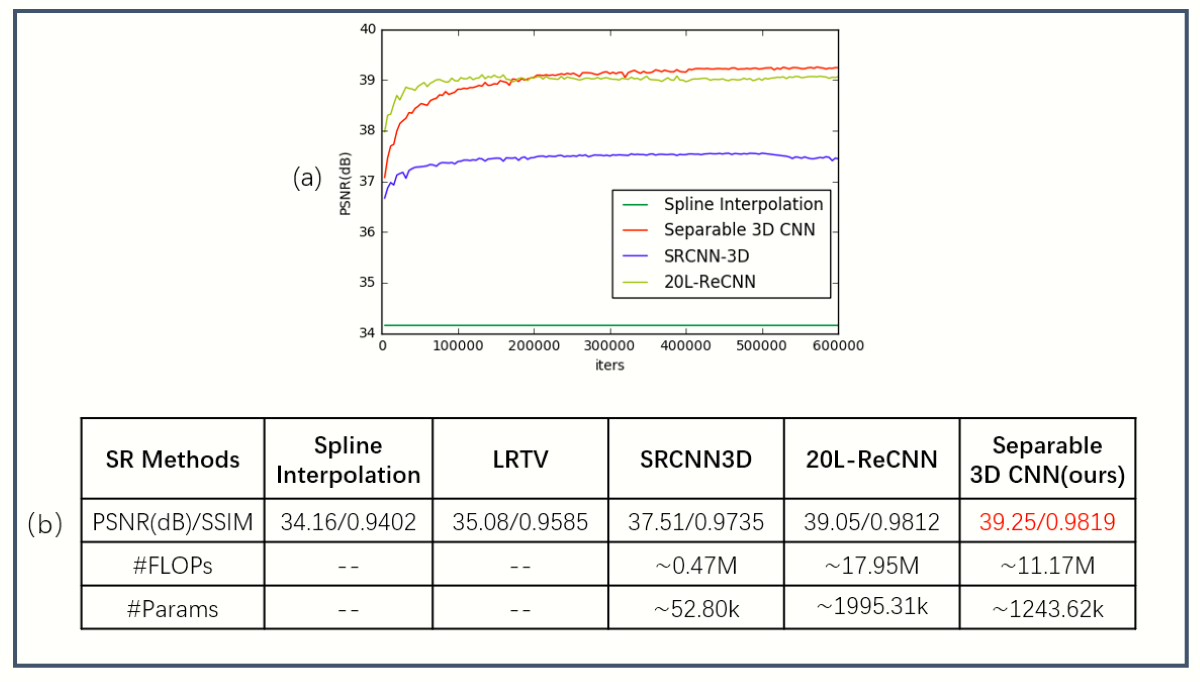
Fig.4
The evolution of the mean PSNR of SRCNN-3D1
and ReCNN2, LRTV5 with respect to the number of iterations(a),
Qualitative comparison of the performance of different methods (b).
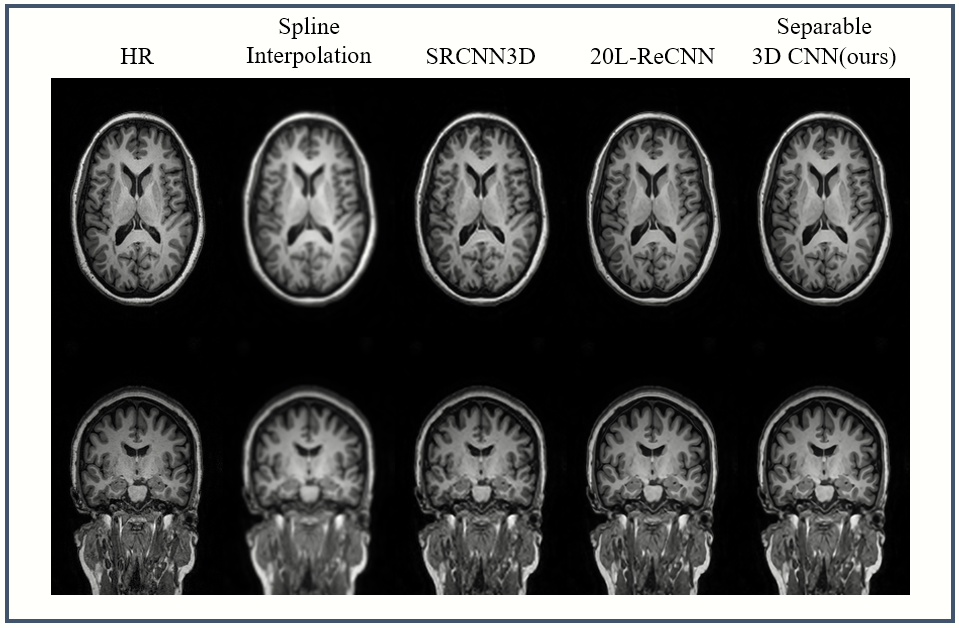
Fig.5
The visual effect comparisons of different models