3539
A Multi-Stream GAN Approach for Multi-Contrast MRI Synthesis1Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey, 2National Magnetic Resonance Research Center, Bilkent University, Ankara, Turkey, 3Department of Computer Engineering, Hacettepe University, Ankara, Turkey, 4Neuroscience Program, Sabuncu Brain Research Center, Bilkent University, Ankara, Turkey
Synopsis
For synthesis of a single target contrast within a multi-contrast MRI protocol, current approaches perform either one-to-one or many-to-one mapping. One-to-one methods take as input a single source contrast and learn representations sensitive to unique features of the given source. Meanwhile, many-to-one methods take as input multiple source contrasts and learn joint representations sensitive to shared features across sources. For enhanced synthesis, we propose a novel multi-stream generative adversarial network model that adaptively integrates information across the sources via multiple one-to-one streams and a many-to-one stream. Demonstrations on neuroimaging datasets indicate superior performance of the proposed method against state-of-the-art methods.
Introduction
Synthesis of a single target contrast in a multi-contrast MRI protocol can be performed via either one-to-one methods that receive a single source 1-4 or many-to-one methods that receive multiple sources 5-8. One-to-one mapping inherently manifests increased sensitivity to unique, detailed features of the source, but it may prove suboptimal when source-target images are poorly correlated. On the other hand, many-to-one mapping sensitively captures shared features across multiple sources. Yet, it might be less sensitive to complementary features uniquely present in specific sources. To mitigate the limitations of conventional one-to-one and many-to-one mappings, here we propose a novel multi-stream generative adversarial network model (mustGAN) that incorporates information flow in multiple one-to-one streams and a many-to-one stream. The unique feature maps captured in the one-to-one streams and the joint feature maps captured in the many-to-one stream are combined via a fusion block that is adaptively positioned in the architecture to maximize task-specific performance.Methods
mustGAN involves an adversarial training procedure 10 to learn recovery of a target-contrast image $$$y$$$ from $$$K$$$ source-contrast images denoted as $$$X:\{x_k:k=1,2,...K\}$$$.One-to-one streams: mustGAN first learns $$$K$$$ independent one-to-one streams, where the $$$k^{th}$$$ stream synthesizes $$$y$$$ from $$$x_k$$$ using a generator $$$G_k$$$ that is trained together with a discriminator $$$D_k$$$. To train $$$G_k$$$ and $$$D_k$$$, adversarial and pixel-wise losses are used. The aggregate loss $$$L_k$$$ then becomes:$$L_k=\underbrace{-E_{x_ky}[(D_k(x_k,y)-1)^2]-E_{x_k}[D_k(x_k,G_k(x_k))^2]}_\text{adversarial loss}+\underbrace{E_{x_ky}[||y-G_k(x_k)||_1]}_\text{pixel-wise loss}$$where $$$E$$$ denotes expectation.
Many-to-one streams: mustGAN also learns a many-to-one stream that synthesizes $$$y$$$ from $$$X$$$ using a generator $$$G_{K+1}$$$ that is trained together with a discriminator $$$D_{K+1}$$$. Again, adversarial and pixel-wise losses are used.$$L_{K+1}=\underbrace{-E_{Xy}[(D_{K+1}(X,y)-1)^2]-E_{X}[D_{K+1}(X,G_{K+1}(X))^2]}_\text{adversarial loss}+\underbrace{E_{Xy}[||y-G_{K+1}(X)||_1]}_\text{pixel-wise loss}$$
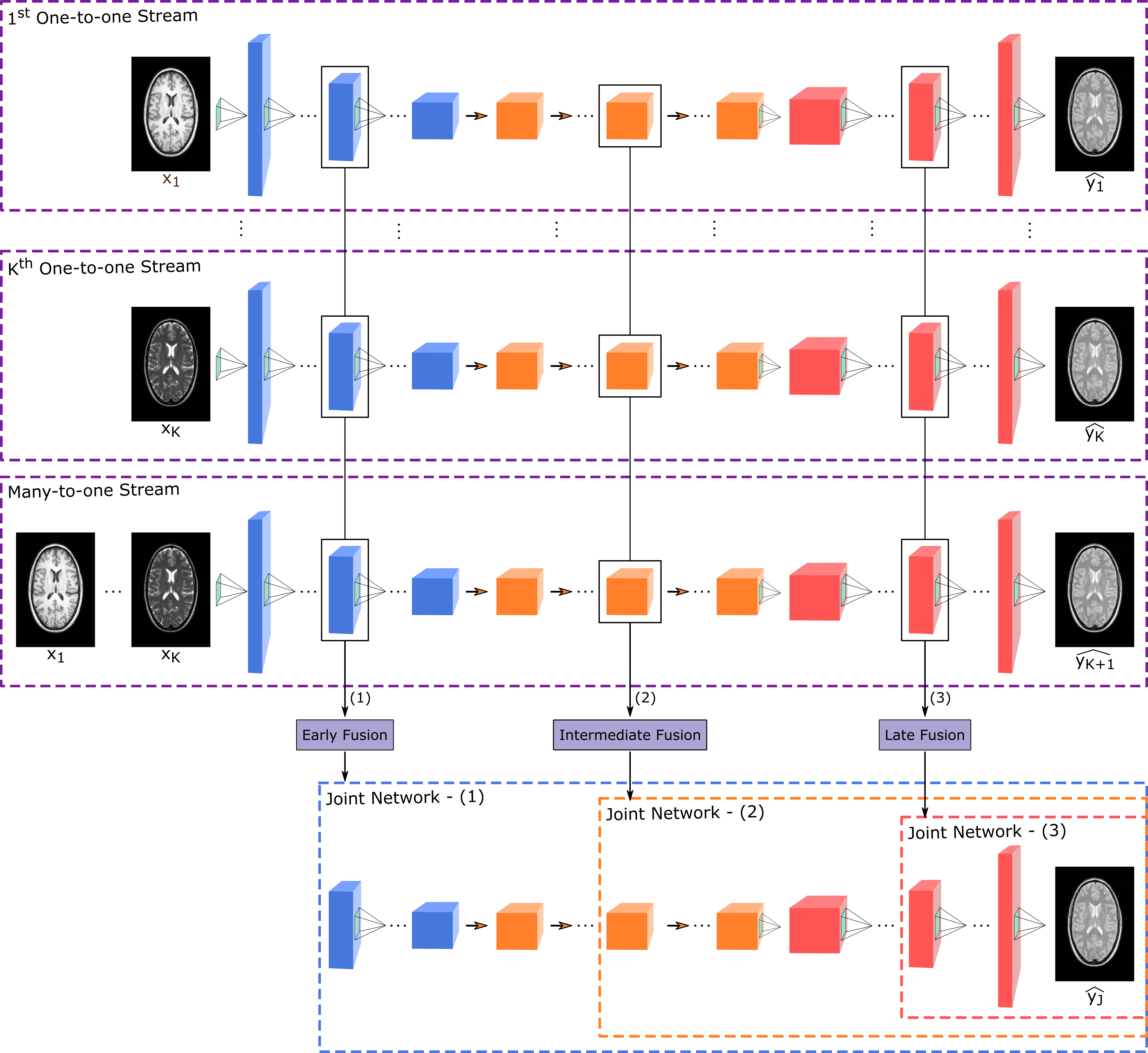
Joint network: Once the streams are independently trained, the sources are propagated through the streams up to the fusion block ($$$F$$$) located at the $$$i^{th}$$$ layer. $$$F$$$ performs feature integration by concatenating feature maps generated by the one-to-one and many-to-one streams at this layer ($$$\mathrm{Figure\:1}$$$). A joint network ($$$J$$$) is then trained to recover the target image from the fused feature maps $$$g_f^i$$$. The architecture of $$$J$$$ adaptively varies depending on the location of $$$F$$$, yielding early, intermediate or late fusion ($$$\mathrm{Figure\:1}$$$). $$$J$$$ is also trained together with a discriminator $$$D_j$$$ using adversarial and pixel-wise losses.$$L_{J}=\underbrace{-E_{Xy}[(D_{J}(X,y)-1)^2]-E_{X}[D_{J}(X,J(g_f^i))^2]}_\text{adversarial loss}+\underbrace{E_{Xy}[||y-J(g_f^i)||_1]}_\text{pixel-wise loss}$$
The proposed method was demonstrated on two neuroimaging datasets (IXI 11 and ISLES 12). T1, T2 and PD synthesis were considered in IXI using $$$25$$$ training, $$$10$$$ validation and $$$18$$$ test subjects. From each subject, approximately $$$100$$$ axial cross-sections were selected. Images were acquired with ($$$\mathrm{volume\:size=256x256x150,resolution=0.94x0.94x1.2mm^3}$$$). T1, T2 and FLAIR synthesis were considered in ISLES using $$$25$$$ training, $$$10$$$ validation and $$$18$$$ test subjects. From each subject, approximately $$$100$$$ axial cross-sections for T1 and FLAIR synthesis, and $$$120$$$ sagittal cross-sections for T2 synthesis were selected. Images were acquired with heteregenous set of scanning parameters 12.
The proposed method was compared against three MRI synthesis methods: Multimodal that learns to recover the target from multiple sources with a convolutional encoder-decoder network 8, pGAN that learns to synthesize target from a single source in an adversarial setup 1, and pGANmany that is a many-to-one variant of pGAN receiving multiple sources as input.
Implementation details: $$$G_k$$$ and $$$G_{K+1}$$$ consist of an encoder with $$$3$$$ convolutional layers, a residual network with $$$9$$$ ResNet blocks, and a decoder with $$$3$$$ convolutional layers. As mentioned above, $$$F$$$ is adaptively located in the network to maximize task-specific performance, therefore the precise architecture of $$$J$$$ varies depending on $$$i$$$. $$$D_k,D_{K+1}$$$ and $$$D_j$$$ contain $$$5$$$ convolutional layers.
Hyper-parameters for training the streams were adopted from 1. The streams were trained for $$$100$$$ epochs via the Adam optimizer ($$${\beta}_1=0.5,{\beta}_1=0.999$$$). Learning rate was $$$0.0002$$$ for the first $$$50$$$ epochs and linearly decayed to $$$0$$$ in the last $$$50$$$ epochs. Relative weighing of the adversarial loss to pixel-wise loss was set to $$$100$$$. The joint network was also trained with the same hyper-parameters except for the number of epochs. One-fold cross-validation was performed to determine optimal number of epochs along with fusion block position varied in $$$[1:1:14]$$$. See 9 for further details.
Results
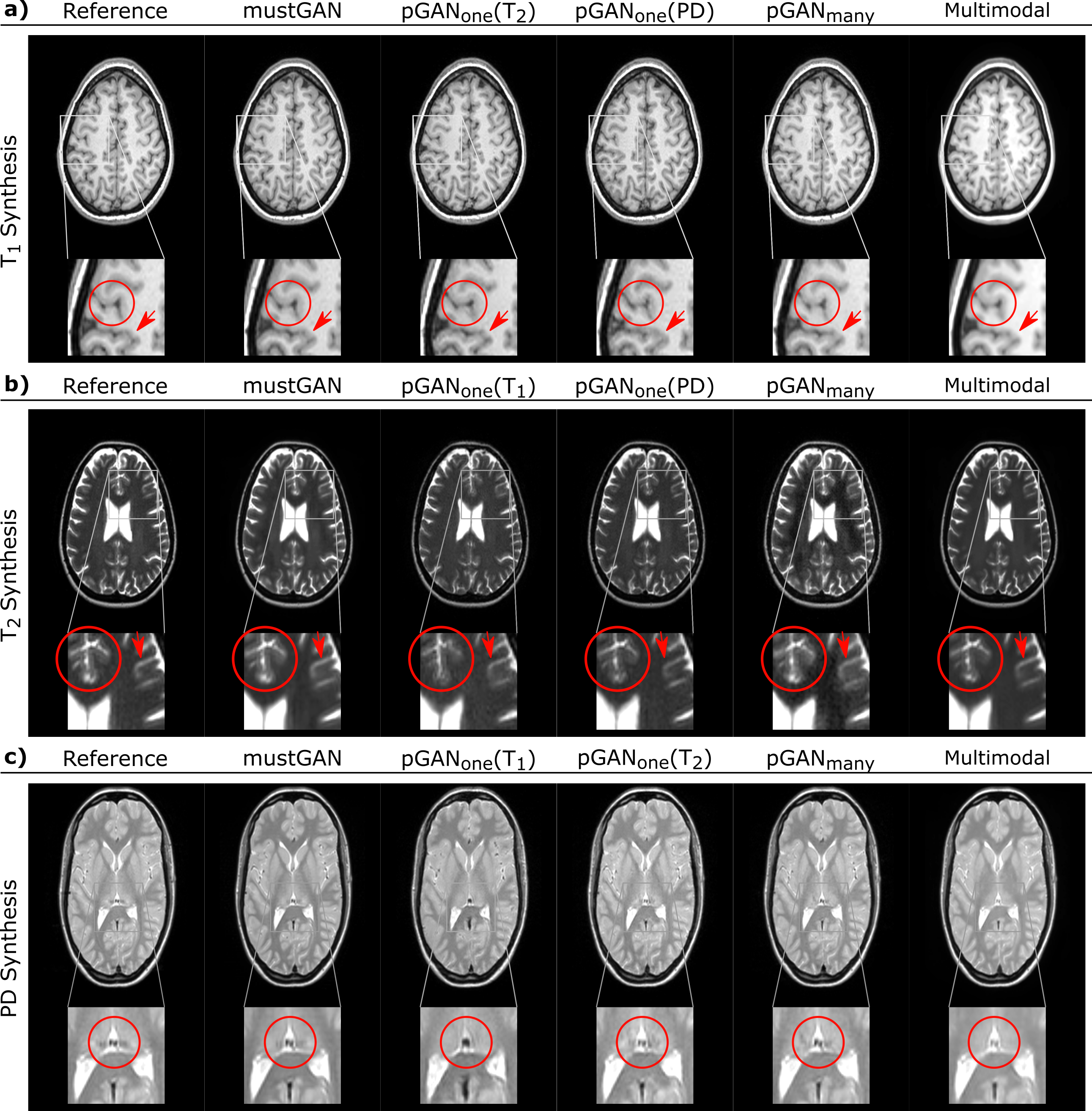
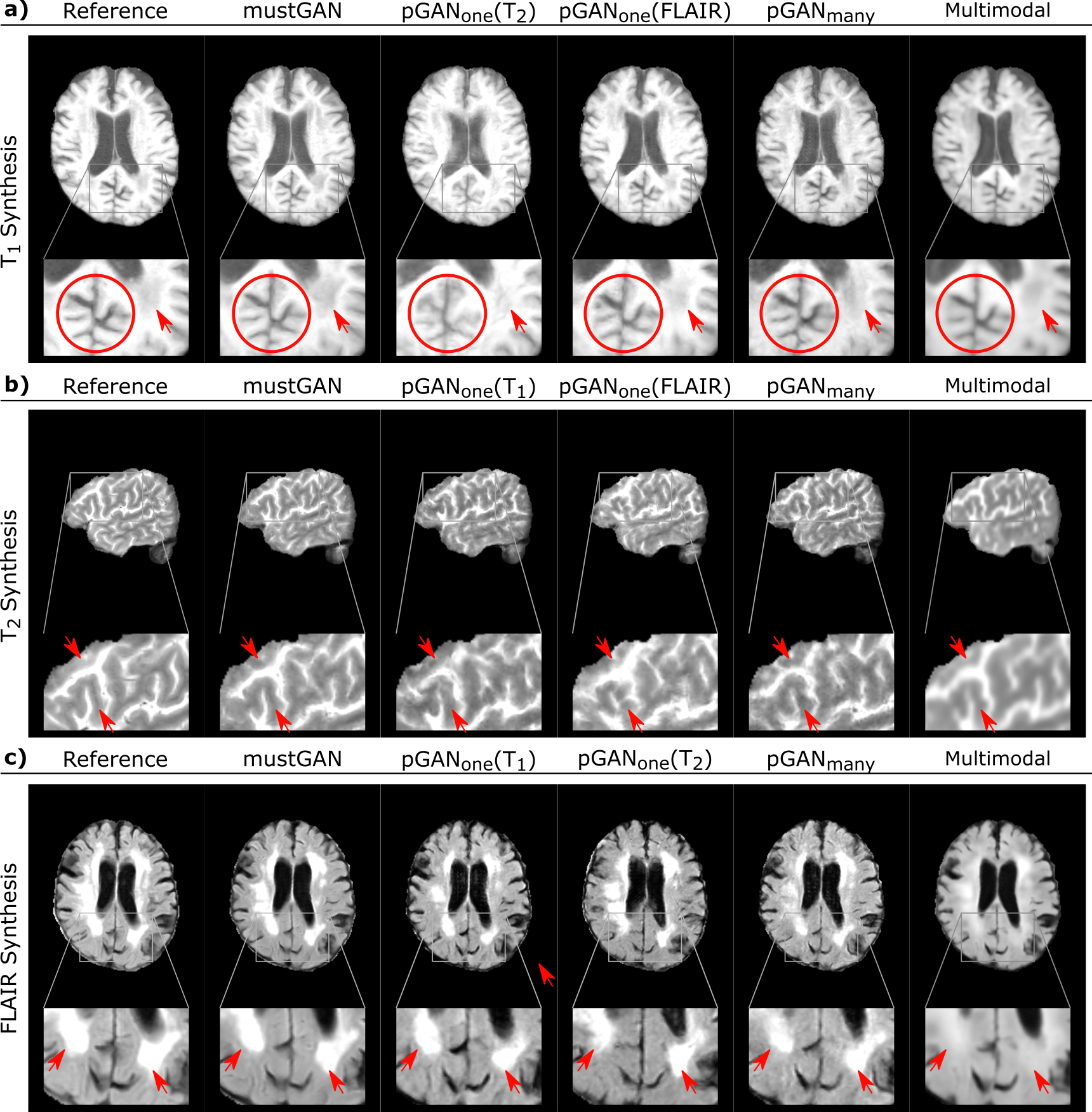
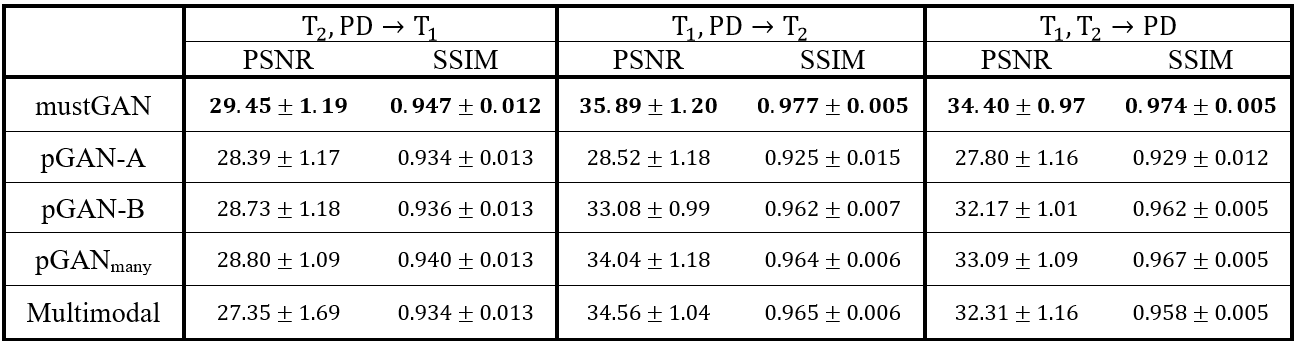
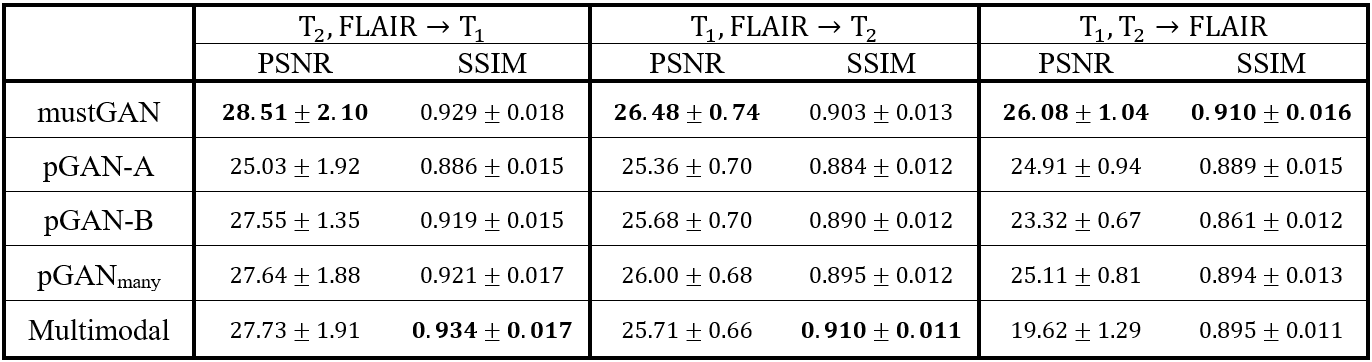
The proposed and competing methods were compared via PSNR-SSIM metrics. $$$\mathrm{Table\:1}$$$ lists PSNR-SSIM measurements across test subjects in IXI. On average, mustGAN yields $$$1.097$$$ dB higher PSNR and $$$0.909\%$$$ higher SSIM as compared to the second-best method in each task. $$$\mathrm{Table\:2}$$$ lists PSNR-SSIM measurements across test subjects in ISLES. On average, mustGAN yields $$$0.743$$$ dB higher PSNR and $$$0.110\%$$$ higher SSIM as compared to the second-best method in each task. Representative displays also demonstrate the superior performance of mustGAN against the competing methods. $$$\mathrm{Figure\:2a-c}$$$ respectively show representative results for T1, T2 and PD synthesis in IXI; and $$$\mathrm{Figure\:3a-c}$$$ respectively show representative results for T1, T2 and FLAIR synthesis in ISLES. In both datasets, mustGAN attains less-noisy depiction of white-matter and sharper depiction of gray-matter boundaries as compared to the competing methods.Discussion
We proposed a novel multi-stream GAN model that performs within-modality synthesis for multi-contrast MRI. The proposed method effectively pools information across one-to-one streams sensitive to complementary features in individual sources and a many-to-one stream sensitive to shared features across multiple sources.Conclusion
The proposed method enables enhanced multi-contrast MRI synthesis by task-specific combination of information flow in one-to-one and many-to-one models.Acknowledgements
This work was supported in part by a Marie Curie Actions Career Integration Grant (PCIG13-GA-2013-618101), by a European Molecular Biology Organization Installation Grant (IG 3028), by a TUBA GEBIP fellowship, by a TUBITAK 1001 Grant (118E256), and by a BAGEP fellowship awarded to T. Çukur. We also gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.References
1. Dar SUH, Yurt M, Karacan L, Erdem A, Erdem E, Çukur T. Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Transactions on Medical Imaging. 2019;38(10):2375-2388.
2. Yang H, Sun J, Carass A, Zhao C, Lee J, Xu Z, Prince J. Unpaired brain MR-to-CT synthesis using a structure constrained cycleGAN. Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. 2019:175-182.
3. Huang Y, Shao L, Frangi A. Simultaneous super-resolution and cross-modality synthesis of 3d medical images using weakly-supervised joint convolutional sparse coding. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017:5787-5796.
4. Yu B, Zhou L, Wang L, Shi Y, Fripp J, Bourgeat P. EA-GANs: edge aware generative adversarial networks for cross-modality MR image synthesis. IEEE Transactions on Medical Imaging. 2019;38(7):1750-1762.
5. Li H, Paetzold JC, Sekuboyina A, Kofler F, Zhang J, Kirschke JS, Wiestler B, Menze B. DiamondGAN: unified multi-modal generative adversarial networks for MRI sequences synthesis. Medical image computing and computer assisted intervention (MICCAI). 2019;11767:795-803.
6. Sharma A, Hamarneh G. Missing MRI pulse sequence synthesis using multi-modal generative adversarial network. IEEE Transactions on Medical Imaging. 2019:1-1.
7. Lee D, Kim J, Moon W-J, Ye JC. CollaGAN: Collaborative GAN for missing image data imputation. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019:2487-2496.
8. Chartsias A, Joyce T, Valerio M, Tsaftaris S. Multi-modal MR synthesis via modality-invariant latent representation. IEEE Transactions on Medical Imaging. 2017;37(3):803-814.
9. Yurt M, Dar SUH, Erdem A, Erdem E, Çukur T. mustGAN: Multi-stream generative adversarial networks for MR image synthesis. arXiv Preprint. 2019.
10. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial networks. Advances in Neural Information Processing Systems. 2014;6(3):2672-2680.
11. https://brain-development.org/ixi-dataset/
12. Maier O, Menze BH, von der Gablentz J, Häni L, Heinrich MP, Liebrand M, Winzeck S, Basit A, Bentley P, Chen L, Christiaens D. ISLES 2015-A public evaluation benchmark for ischemic stroke lesion segmentation from multispectral MRI. Medical image analysis. 2017;35:250-269.
Figures