3456
Combining Supervised and semi-Blind Dictionary (Super-BReD) Learning for MRI Reconstruction1Electrical and Computer Engineering, University of Michigan, Ann Arbor, MI, United States, 2Computational Mathematics, Science and Engineering, and Biomedical Engineering, Michigan State University, East Lansing, MI, United States
Synopsis
Regularization in MRI reconstruction often involves sparse representation of signals using linear combinations of dictionary atoms. In 'blind' settings, these dictionaries are learned during reconstruction from the corrupt/aliased images, using no training data. In contrast, 'Fully supervised' dictionary learning (DL) requires uncorrupted/fully sampled training images, and the learned dictionary is used to regularize image reconstruction from undersampled data. We combine the aforementioned DL frameworks to learn two separate dictionaries in a residual fashion to jointly reconstruct an undersampled image. Our algorithm, Super-BReD Learning, shows promising results on reconstruction from retrospectively undersampled data, and outperforms recent DL schemes.
Introduction
Sparse representation of signals using a linear combination of dictionary atoms is a popular choice in regularizing MR image reconstruction. Data-driven dictionary learning has often shown to provide better results than hand-crafted dictionaries in Compressed Sensing(CS)-MRI[1,5]. Data-driven dictionaries are either learned in a 'supervised' fashion from training images obtained from fully sampled k-space measurements, and then used to reconstruct images from undersampled k-space measurements, or are learned assuming knowledge of only the undersampled k-space measurements, and hence dubbed 'blind'.This work investigates combining supervised and blind learning of patch-based dictionaries for image reconstruction, especially when very limited fully sampled data is available for supervised training. We represent the image being reconstructed jointly using two dictionaries[2]: one learned from uncorrupted data, and one in a semi-blind fashion, combined in a residual manner. We also 'tailor' the supervised learning to the undersampled image being reconstructed using a block matching operation. Including a supervised dictionary should boost image quality when blind dictionary learning alone is insufficient.
Methods
Given $$$y\in\mathbb{C}^p$$$, an undersampled k-space measurement vector, $$$T\in\mathbb{C}^{n\times N_1}$$$ a matrix of$$$~N_1$$$ vectorized patches (as columns) from a few images obtained from fully sampled k-space measurements, and $$$\hat{x}$$$ an image being reconstructed from $$$y$$$, the proposed reconstruction approach alternates between solving the following sub-problems:- Block-Matching (For each patch in$$$~\hat{x}$$$, find the best matching patch in the training data$$$~T$$$ ):
where$$S_j=\tau_j(T,\mathcal{P}_j\hat{x})=T_{\hat{i}(j)},\qquad\hat{i}(j)=\underset{i\in\{1,...,N_1\}}{\text{arg}~\text{min}}\|H_{\lambda_0}\bigg(W\big(T_i-\mathcal{P}_j\hat{x}\big)\bigg)\|_2^2,$$
$$$\mathcal{P}~$$$extracts$$$~(\sqrt{n}\times\sqrt{n})~$$$patches from an image as a vector and places them as columns of a matrix with $$$\mathcal{P}\hat{x}\in\mathbb{C}^{n\times N_2}$$$,$$$~W\in\mathbb{C}^{n\times n}~$$$is a DCT matrix,$$$~H_{\lambda}(\cdot)$$$ is the hard-thresholding operator, $$$j~$$$indexes the columns of $$$S,\mathcal{P}\hat{x}\in\mathbb{C}^{n\times N_2}$$$, and $$$i~$$$indexes the columns of$$$~T$$$. We applied DCT hard-thresholding before non-local block-matching to reduce the influence of aliasing artifacts on the results.
- Supervised Dictionary Learning (learn a dictionary$$$~\hat{D}_1~$$$from the selected training patches):
where $$$(d_1)_j$$$ is the $$$j$$$th column of the supervised dictionary $$$D_1\in\mathbb{C}^{n\times J_1}$$$, $$$Z_3\in\mathbb{C}^{J_1\times N_2}$$$ is a matrix of sparse codes, and $$$\lambda_3$$$ is a regularization parameter.
- Semi-Blind Residual Dictionary Learning and Image Update:
where $$$F_u$$$ is the undersampled Fourier encoding matrix, $$$(d_2)_j~$$$is the $$$j$$$th column of $$$D_2\in\mathbb{C}^{n\times J_2}$$$, and $$$Z_1\in\mathbb{C}^{J_1\times N_2}$$$, $$$Z_2\in\mathbb{C}^{J_2\times N_2}$$$ are matrices of sparse codes, and $$$\lambda_1,\lambda_2$$$ are regularization parameters.
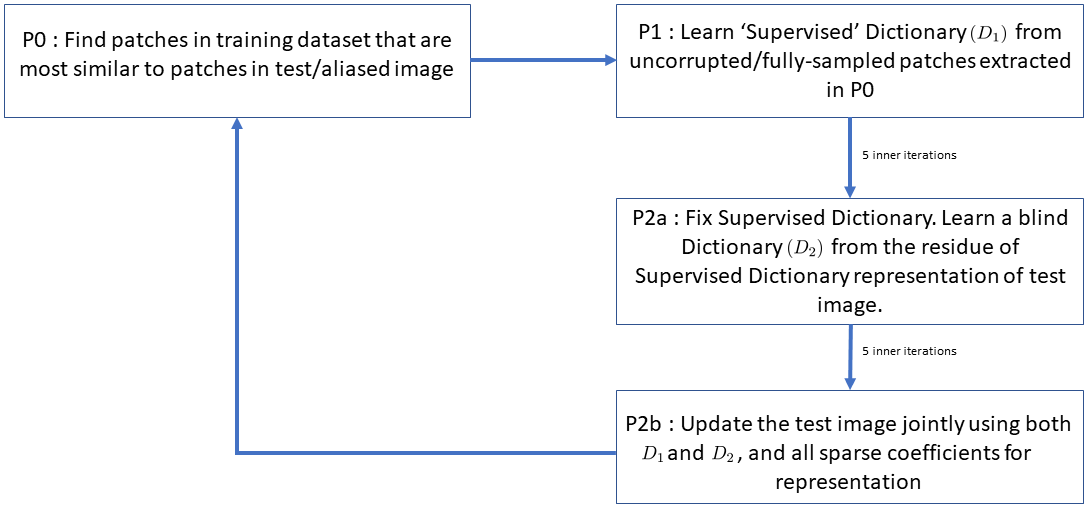
Effectively, we learn a blind dictionary to fit the residual of the supervised dictionary representation of the aliased image patches. Once the image $$$\hat{x}$$$ is updated, We repeat the steps $$$P0-P2$$$ as an outer iteration, as shown in Fig 1, to iteratively refine the image and the Super-BReD model.
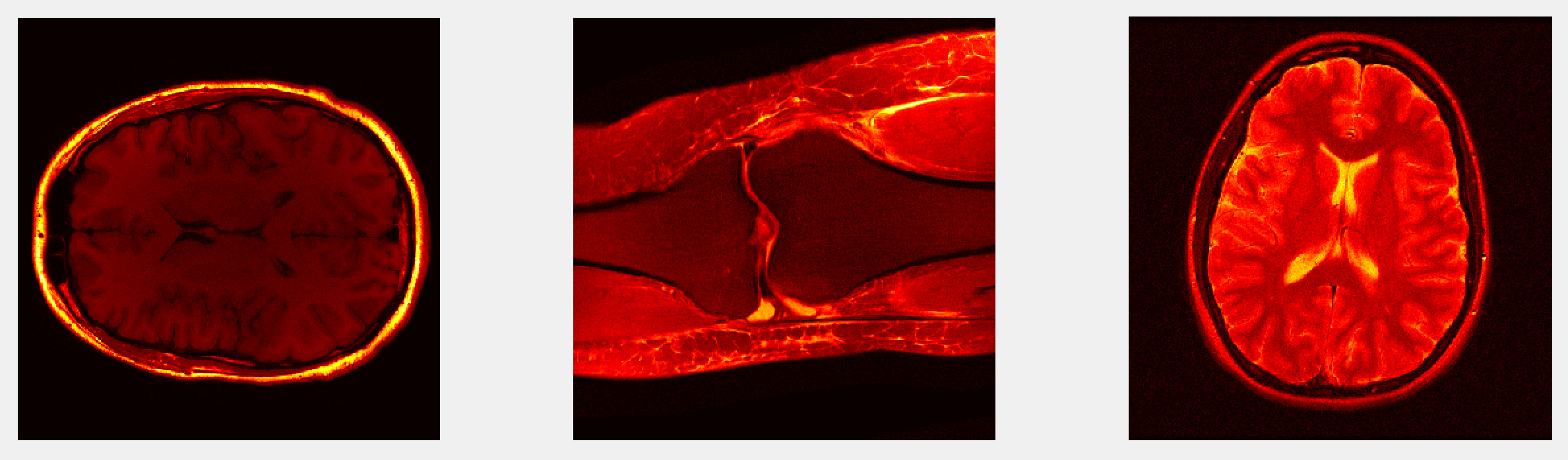
We use overlapping patches from three fully-sampled complex images depicted in Fig 2 as our training data. The updates in $$$P1$$$ and $$$P2$$$ are done in a highly efficient block-coordinate descent fashion similar to [3]. We test our methods for reconstructing two T1-weighted complex brain images and two knee images[4] (simulated single-coil) retrospectively undersampled at 4x and 5x acceleration factors using variable density masks (brain) and phase-encode lines (knee). We compared our method to the recent state-of-the-art SOUP-DIL[3] algorithm, which uses blind dictionary learning and has been shown to provide competitive performance in CS-MR image reconstruction.
For our experiments, we used$$$~n$$$=36,$$$J_1$$$=50, and $$$J_2$$$=144. We set$$$~\lambda_1=\lambda_2=\lambda_3=\lambda$$$, and $$$\lambda_0=\lambda/2$$$ in each outer iteration, and $$$\lambda$$$ decreased in log-space between 0.35-0.04[3] across 75 outer iterations. 5 inner iterations for dictionary learning and sparse coding was used in$$$~P1~$$$and$$$~P2$$$. For fairness, SOUP-DIL also used the same number of inner and outer iterations, and 144 unsupervised atoms. Both algorithms were initialized with a zero-filled reconstruction and overcomplete inverse DCT dictionaries.
Results
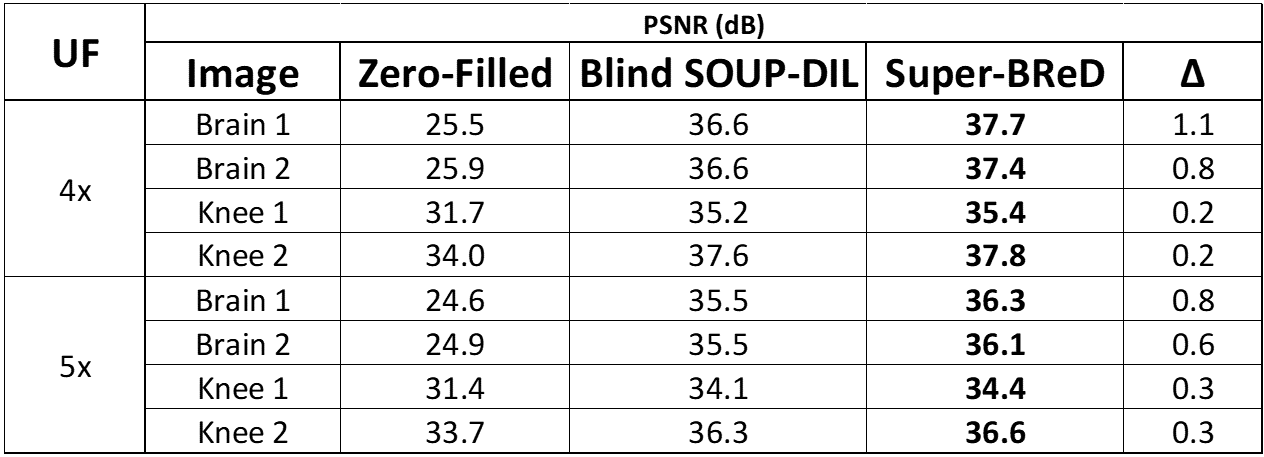
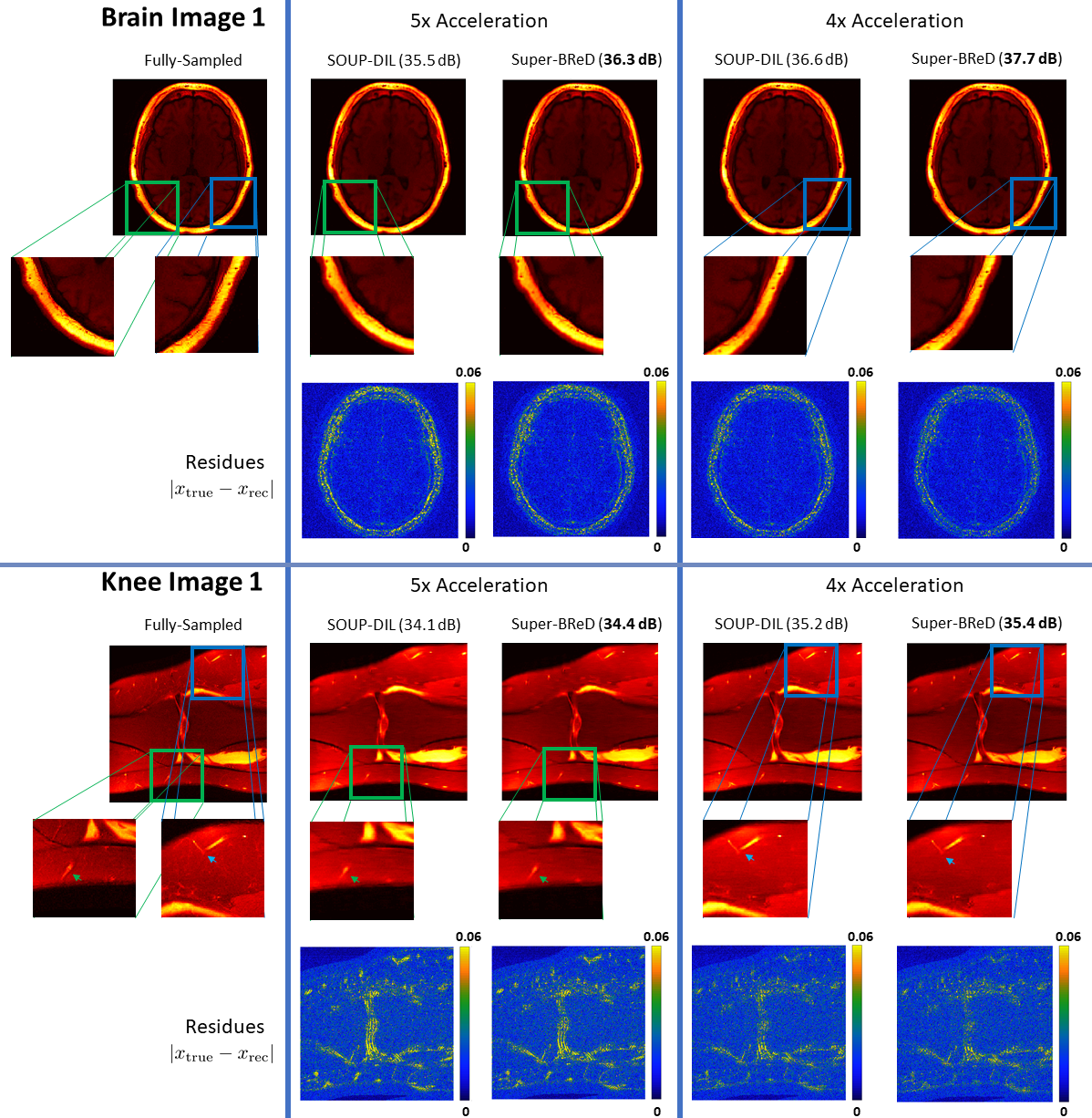
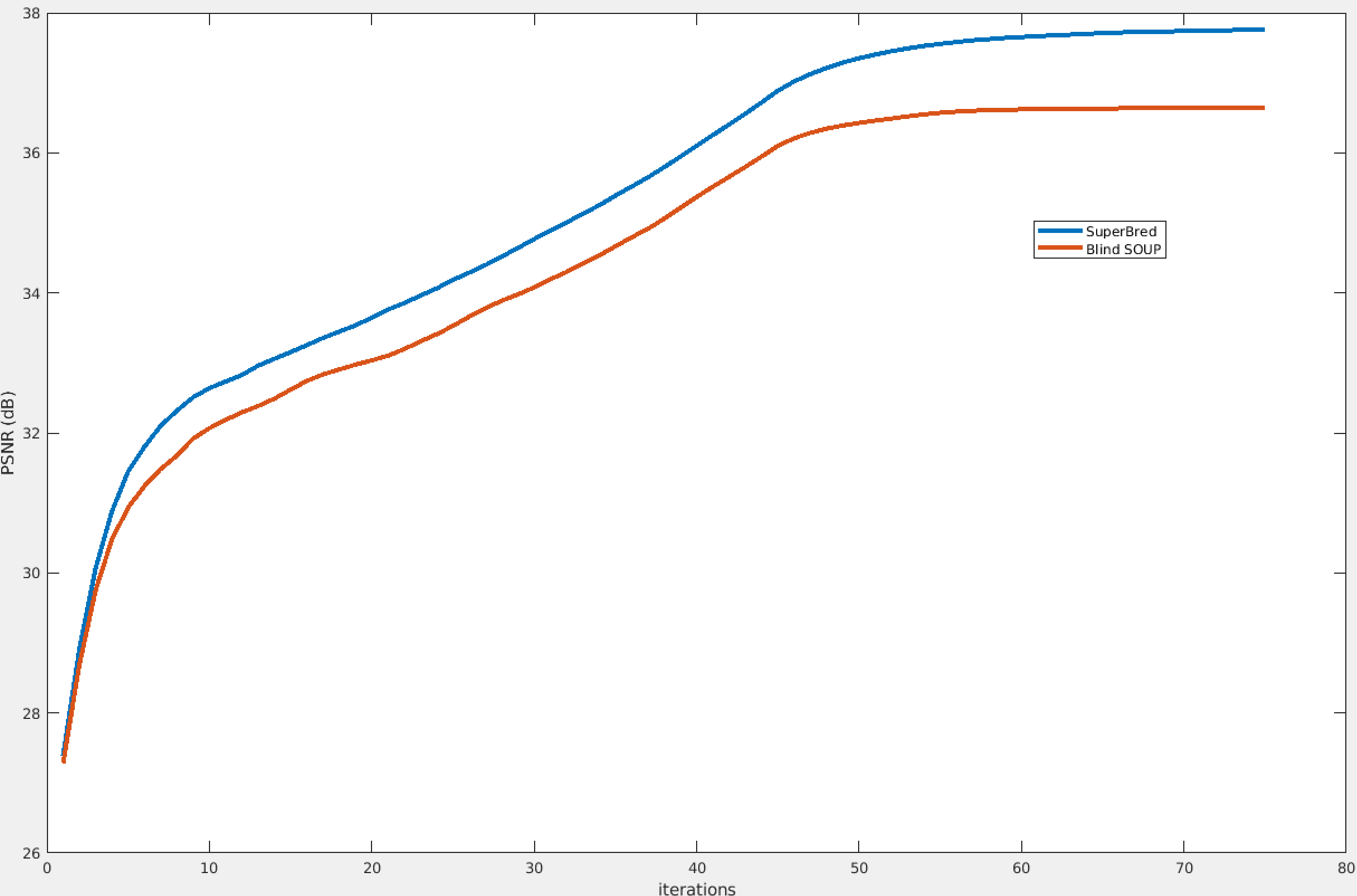
From the table in Fig 3, it is evident that including the supervised dictionary provides significant PSNR gains (0.2-1.1 dB) across most test cases, in both 4x and 5x undersampling. The error maps in Fig 4 show that in the reconstructed brain images, a lot of the improvements were in regions in the skull, which explains the very high PSNR gains from Super-BReD, whereas there are other regions where the details were more clearly preserved for the proposed methods than blind SOUP-DIL. This observation hints at the proposed method's potential for faithful reconstruction of patterns in the data common to both training and test. These improvements can partially be attributed to the supervised block-matching. For the reconstructed knee images as well, we see significant PSNR gains using our method and more fidelity with the ground truth in the finer details, as indicated with arrows. Fig 5 shows that Super-BReD leads to higher gains in PSNR over iterations than blind SOUP-DIL.Conclusion
We investigated combining supervised and blind dictionary learning for CS-MRI. Our preliminary results indicate that, even without careful tuning of hyperparameters, Super-BReD learning provides better image quality than blind dictionary learning. Our proposed method allows for tailoring of supervised learning with blind learning via a block matching step, and presents a novel approach for incorporating supervision in model-based image reconstruction in the presence of limited training data.Our future work will involve comparison to other machine learning methods, and application to multi-coil MR image reconstruction as well as dynamic MRI, where high-quality training data is typically unavailable. Given the direct connection between deep-learning and dictionary learning[6], we also plan to explore incorporating the proposed ideas in such generalized dictionary learning.
Acknowledgements
Supported in part by Precision Health at the University of Michigan
and by NIH R01 EB023618.
References
[1] S. Ravishankar and Y. Bresler, “MR image reconstruction from highly undersampled k-space data by dictionary learning,” IEEE TMI, 2011.
[2] S. Rambhatla and J. Haupt, "Semi-blind source separation via sparse representations and online dictionary learning," IEEE ACSSC, 2013.
[3] S. Ravishankar, R. R. Nadakuditi and J. A. Fessler, "Efficient Sum of Outer Products Dictionary Learning (SOUP-DIL) and Its Application to Inverse Problems," IEEE TCI, 2017.
[4] Jure Zbontar and Florian Knoll and Anuroop Sriram and Matthew J. Muckley and Mary Bruno and Aaron Defazio and Marc Parente and Krzysztof J. Geras and Joe Katsnelson and Hersh Chandarana and Zizhao Zhang and Michal Drozdzal and Adriana Romero and Michael Rabbat and Pascal Vincent and James Pinkerton and Duo Wang and Nafissa Yakubova and Erich Owens and C. Lawrence Zitnick and Michael P. Recht and Daniel K. Sodickson and Yvonne W. Lui, "fastMRI: An Open Dataset and Benchmarks for Accelerated MRI", arXiv:1811.08839.
[5] Z. Zhan, J. F. Cai, D. Guo, Y. Liu, Z. Chen, and X. Qu, “Fast multiclass dictionaries learning with geometrical directions in mri reconstruction,” IEEE TBE, Sept 2016.
[6] S. Ravishankar, J. C. Ye and J. A. Fessler, "Image Reconstruction: From Sparsity to Data-Adaptive Methods and Machine Learning," in Proceedings of the IEEE.
Figures