3354
Motion Correction for a Multi-Contrast Brain MRI using a Multi-Input Neural Network1Korea Advanced Institute of Science and Technology, Daejeon, Republic of Korea
Synopsis
Numerous motion correction methods have been developed to reduce motion artifacts and improve image quality in MRI. Conventional techniques utilizing motion measurement required a prolonged scan time or intensive computational costs. Deep learning methods have opened up a new way for motion correction without motion information. A proposed method using a multi-input neural network with the structural similarity loss takes an advantage of a common clinical setting of multi-contrast acquisition to clearly correct motion artifacts in brain imaging. Motion artifacts can be fully retrospectively and greatly reduced without any motion measurement by the proposed method.
Introduction
Motion of a subject during MRI scan causes a serious motion artifact. To tackle this problem, many motion correction methods have been introduced, but most of them prolonged a scan time because they required motion tracking or estimation of motion during a scan.1 Some of the retrospective motion correction techniques did not rely on motion measurement but demanded intensive computational costs.2Deep learning algorithms have recently received much attention from the MR motion correction field. These data-driven techniques have enabled a completely retrospective motion correction since they do not require motion measurement. A generative adversarial network (GAN) was a common network to reconstruct motion-free images from motion-corrupted inputs.3 However, the GAN-based methods had limitations that they were risky to generate a fake structure.
To overcome this imperfection, we propose a convolutional neural network (CNN) to correct motion-corrupted images using motion-free images of other contrasts. In real clinical practices, it is common to acquire multi-contrast MR images to clearly characterize soft tissues and lesions. Especially in brain imaging, T1-weighted (T1w), T2-weighted (T2w), and T2-weighted FLuid-Attenuated Inversion Recovery (T2-FLAIR) pulse sequences are usually applied for MR scanning.4 Our proposed method utilizes this clinical setting by referring given motion-free images to correct a certain motion-corrupted image through the CNN. This research aims a reliable motion correction without generating an artificial structure in a target image.
Methods
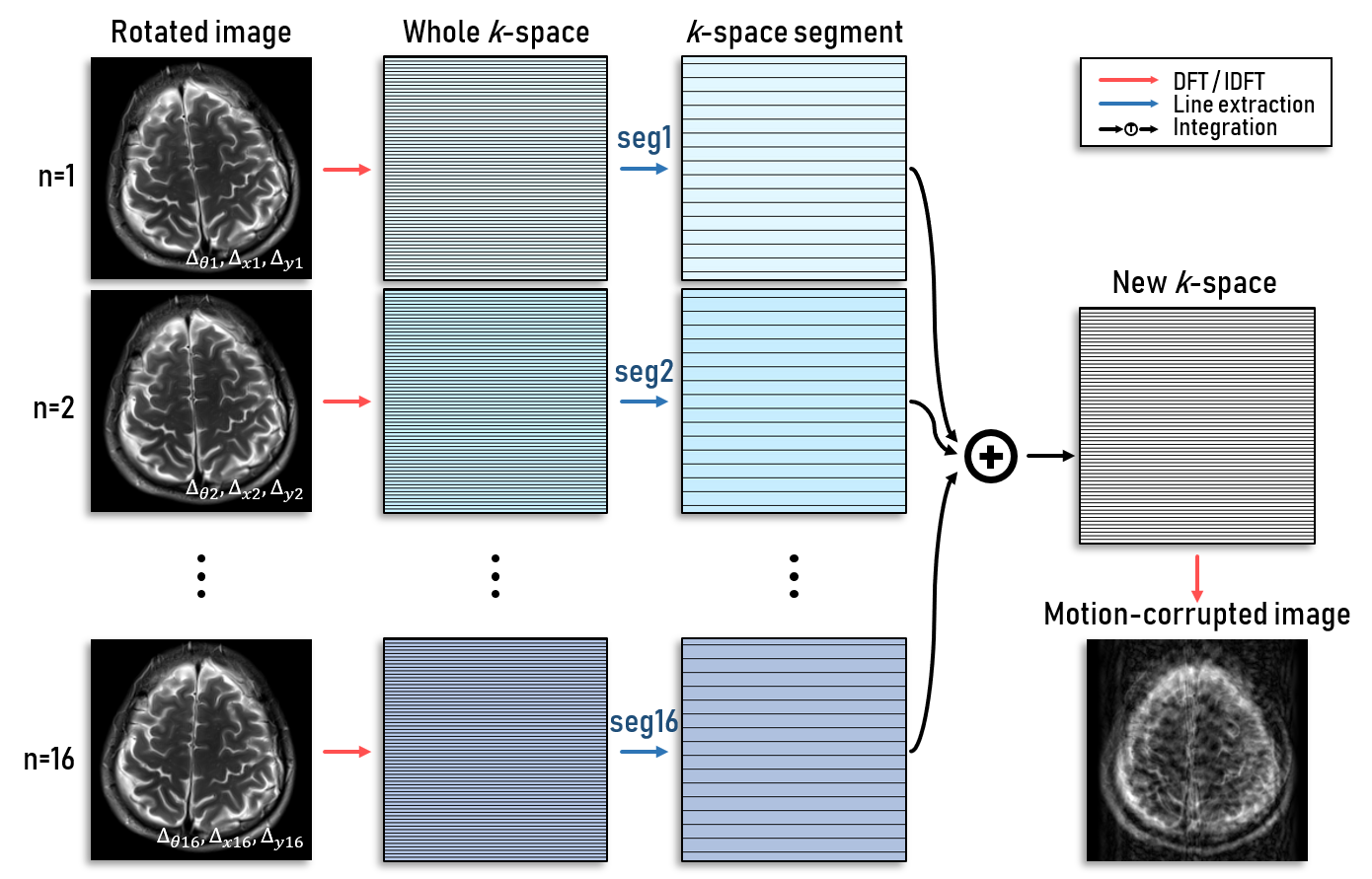
At 3T scanner (Verio, Siemens), MR brain images are acquired with three pulse sequences: T1w spin echo, T2w turbo spin echo, and T2-FLAIR turbo spin echo. Pulse sequence parameters are determined referring to the clinical research.4 Motion-free images are acquired to generate a dataset as the ground truth. Motion is artificially simulated and applied to the motion-free images to create motion-corrupted images. The motion-corrupted images are generated using MR physics including k-space line orders, resulting in different artifact patterns (Figure 1). The artifact patterns depend on the frequency of motions, rotation angles, and translation parameters. Training data are 193 slices of 33 subjects, validation data are 33 slices of 4 subjects, and test data are 34 slices of 4 subjects.In our proposed scheme, multi-modal registration (MMR) among different contrast images is performed to adjust misalignment created by motions. Whereas intra-modal registration can be executed using pixel intensity information, multi-modal registration usually utilizes joint probability between different contrast images. Maximization of mutual information (MI) is one of the most widely used multi-modal registration methods, and MI value is defined as follows:
$$\text{MI}(X,Y)=\sum_{y\in Y}\sum_{x\in X}{p\left(x,y\right)\log{\frac{p\left(x,y\right)}{p\left(x\right)p\left(y\right)}}}$$
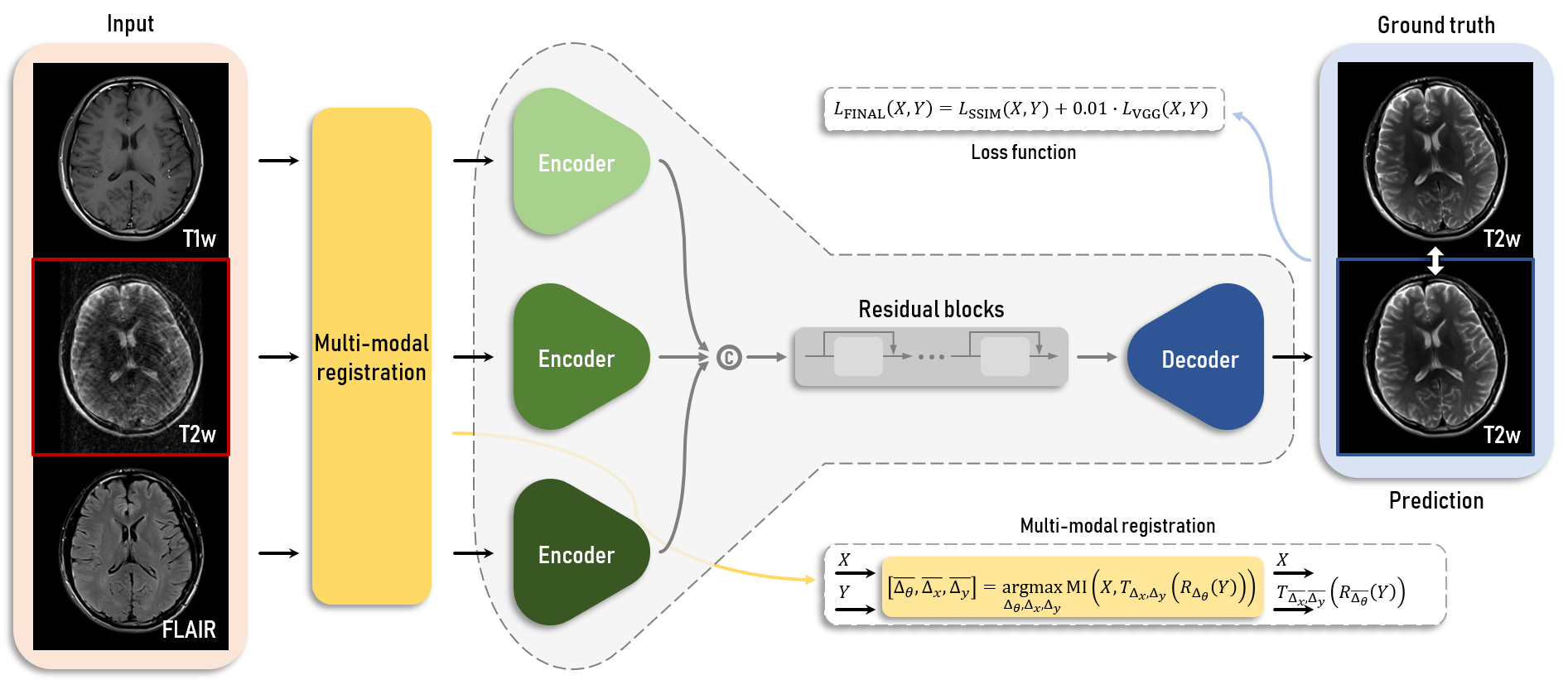
where $$$X$$$ and $$$Y$$$ are images of different contrasts, $$$x$$$ and $$$y$$$ are pixel locations of $$$X$$$ and $$$Y$$$, respectively, and $$$p$$$ is a probability or a joint probability. Orientation using mutual information is performed before a deep network operation in our method to minimize an error followed by mismatched positions among images.
A ResNet generator is used for our proposed scheme. The generator has a number of corresponding to multi-contrast MR images, where three encoders are used for this study. Each encoder consists of three convolutional layers to generate latent variables from inputs. Latent variables from all inputs are concatenated into one vector. The vector is put into a series of nine residual blocks to create an input of a decoder of a target contrast image. At last, the output of the residual blocks enters into the decoder, which predicts a motion-free image (Figure 2). Loss function used for training is based on the structural similarity (SSIM) for data consistency and VGG network for human perception. Each loss term is defined as follows:
$$L_{\text{SSIM}}\left(X,Y\right)=-\log{\frac{\text{SSIM}\left(X,Y\right)+0.2}{1.2}};\ L_{\text{VGG}}\left(X,Y\right)=\left\|\text{VGG}(X)-\text{VGG}(Y)\right\|_2$$
The final loss term is a weighted sum of two terms (1:0.01). Adam optimizer is used for the optimization with the learning rate $$${10^{-4}}$$$. All scenarios were trained in separate models and results of the simulation test set were evaluated based on the SSIM.
Results
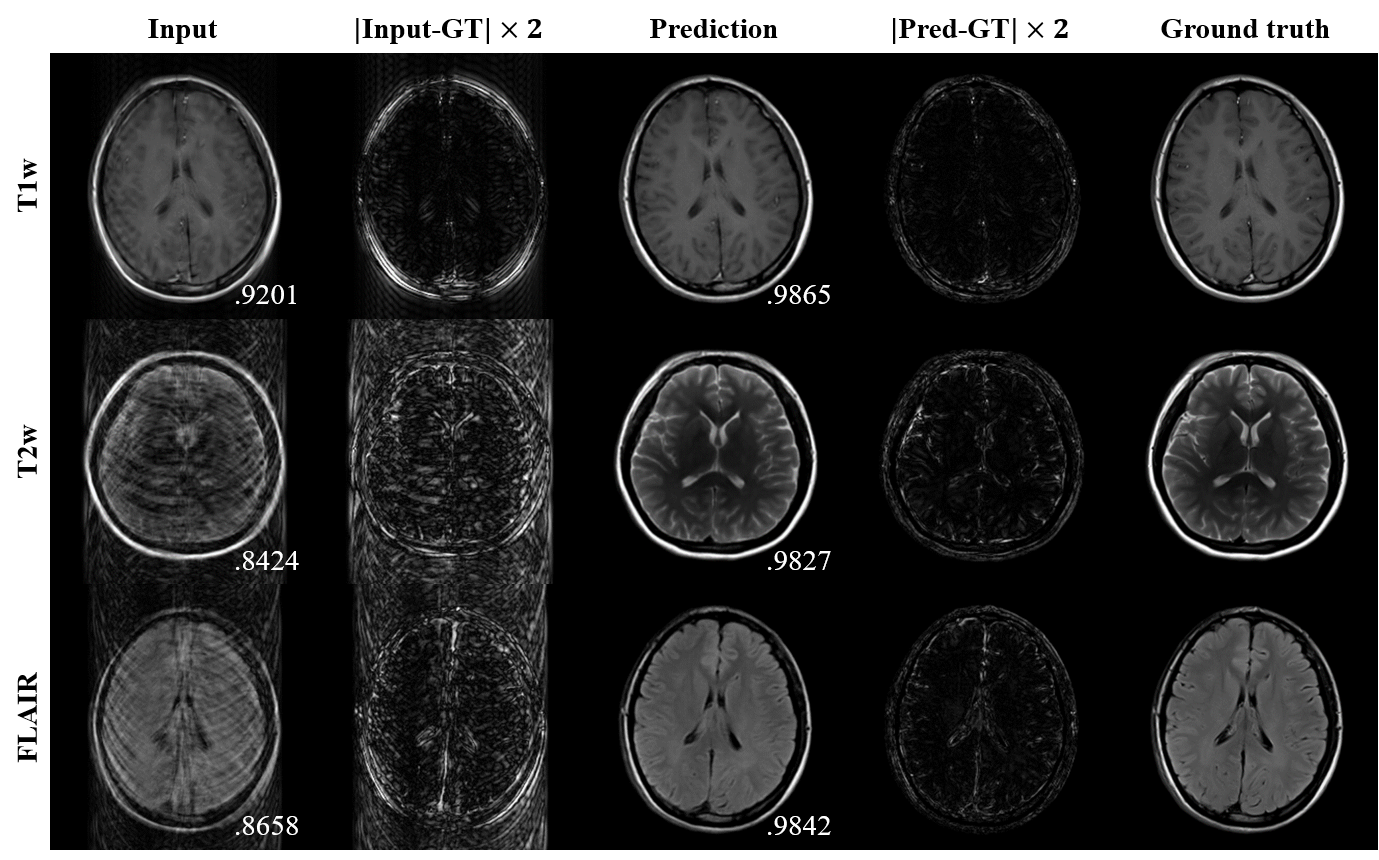
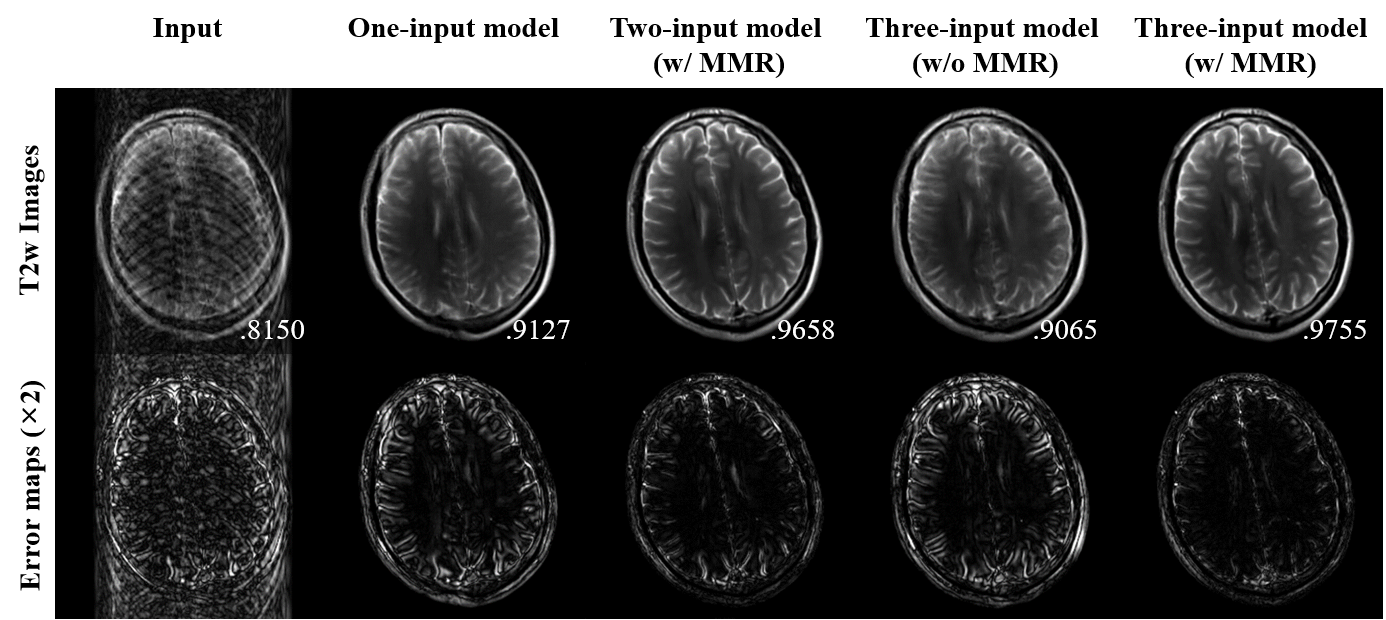
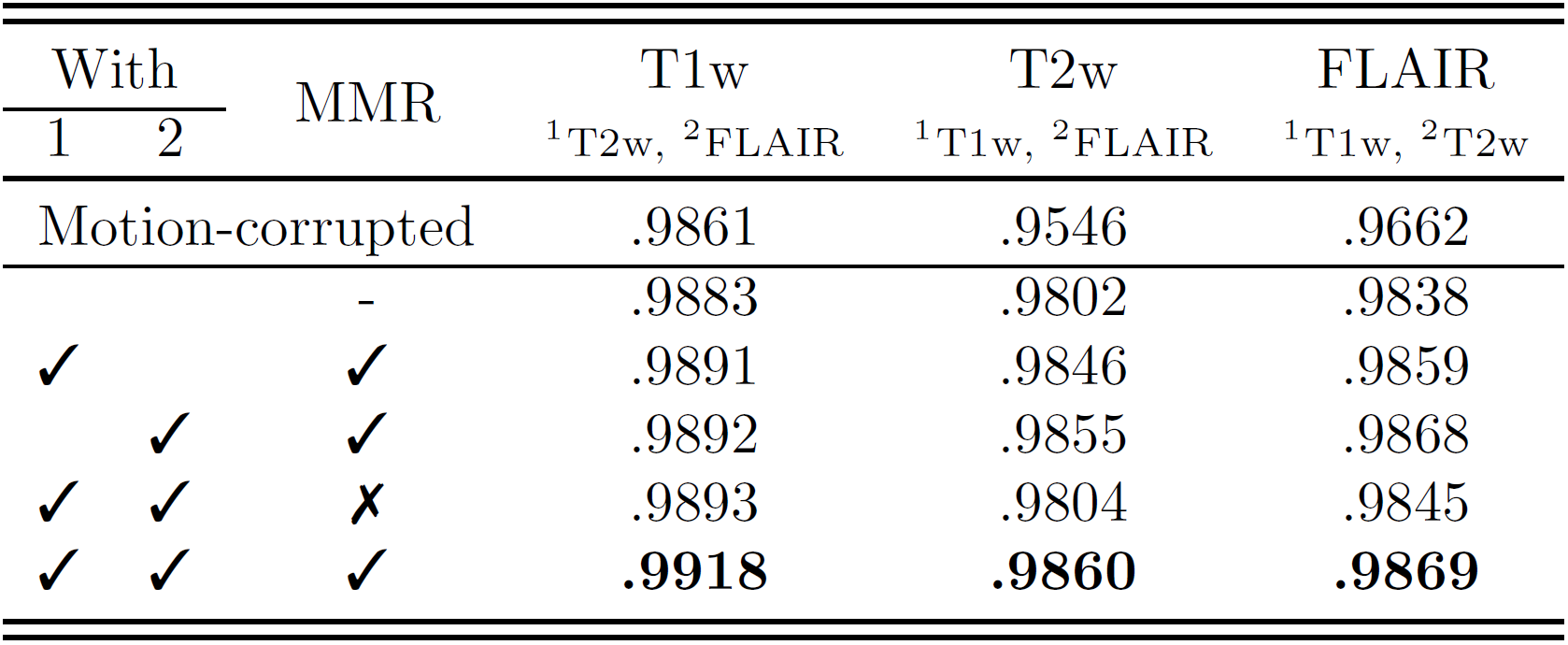
For three-input model cases of multi-contrast images, it is shown that the proposed scheme greatly improved image qualities from motion-corrupted images (Figure 3). Their quantitative scores also highly increased compared to input image qualities.Multi-input models without registration and one-input model were also trained and evaluated for comparison as shown in Table 1. Quantitative results show that the motion correction method dramatically improved its performance when it used other contrast images of corresponding slices. In addition, when input images were co-registered, output images show much better results. Figure 4 clearly visualize how well the multi-input model with multi-modal registration outperforms other models using a single input or only intra-modal registration.
Discussion and Conclusion
It has shown that the deep neural network is capable of retrospectively reconstructing motion-free images from motion-corrupted inputs with the help of multi-contrast images of corresponding positions. The one-input model can reduce some motion artifacts but cannot successfully reconstruct motion-free images and generates some artificial structures due to lack of real structural information from other contrast images. In comparison, the multi-input model, which is a clinically realistic setting for brain imaging, resolves the ill-posed problem. Multi-modal registration furthermore fine-tunes misalignment among multiple contrast images that can be generated by motion between scans.Acknowledgements
This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: HI14C1135) and by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government (MSIT) (No.2017-0-01778).References
1. Zaitsev M, Maclaren J, Herbst M. 2015. Motion artifacts in MRI: a complex problem with many partial solutions. Journal of Magnetic Resonance Imaging. 42(4): 887-901.
2. Atkinson D, Hill DL, Stoyle PN, Summers PE, Keevil SF. 1997. Automatic correction of motion artifacts in magnetic resonance images using an entropy focus criterion. IEEE Transactions on Medical imaging. 16(6): 903-10.
3. Küstner T, Armanious K, Yang J, Yang B, Schick F, Gatidis S. 2019. Retrospective correction of motion‐affected MR images using deep learning frameworks. Magnetic Resonance in Medicine.
4. Lu H, Nagae‐Poetscher LM, Golay X, Lin D, Pomper M, Van Zijl PC. 2005. Routine clinical brain MRI sequences for use at 3.0 Tesla. Journal of Magnetic Resonance Imaging. 22(1): 13-22.
Figures