3226
Semi-Supervised Image Domain Transfer for Dixon Water and Fat Separation1Imaging Physics Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 2Diagnostic Radiology Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 3Department of Diagnostic Radiology, The University of Texas Southwestern Medical Center, Dallas, TX, United States, 4Cancer Systems Imaging Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States
Synopsis
Deep learning neural-networks for Dixon imaging require a large number of “paired” input and output images for network training. Moreover, the previous methods require Dixon images as their network input, thus they could not be used to reconstruct water images from regular T1 or T2-weighted images. In this work, we propose an image domain transfer based deep-learning network which can reconstruct water images from either T1 or T2-weighted MR images. Using semi-supervised learning, two separate groups of “unpaired and unordered” input and output images were used to translate either T1 or T2-weighted images to their corresponding water-only images.
INTRODUCTION
Deep learning using convolutional neural networks (CNN) have been shown for Dixon water and fat separation using images from a single-echo or multi-echo Dixon acquisition.1-3 However, most of the previously proposed methods require a large number of "paired" input and output images for network training. Without these input and output images, the applicability of these trained networks is limited. Further, the previous methods1-3 require Dixon images as their network input, thus they could not be used to reconstruct water images from T1 or T2-weighted images.In this work, we propose an image domain transfer based deep-learning network which can reconstruct water images from either T1 or T2-weighted MR images. Using semi-supervised learning, two separate groups of “unpaired and unordered” input and output images were used to translate either T1 or T2-weighted images to their corresponding water-only images.
METHODS
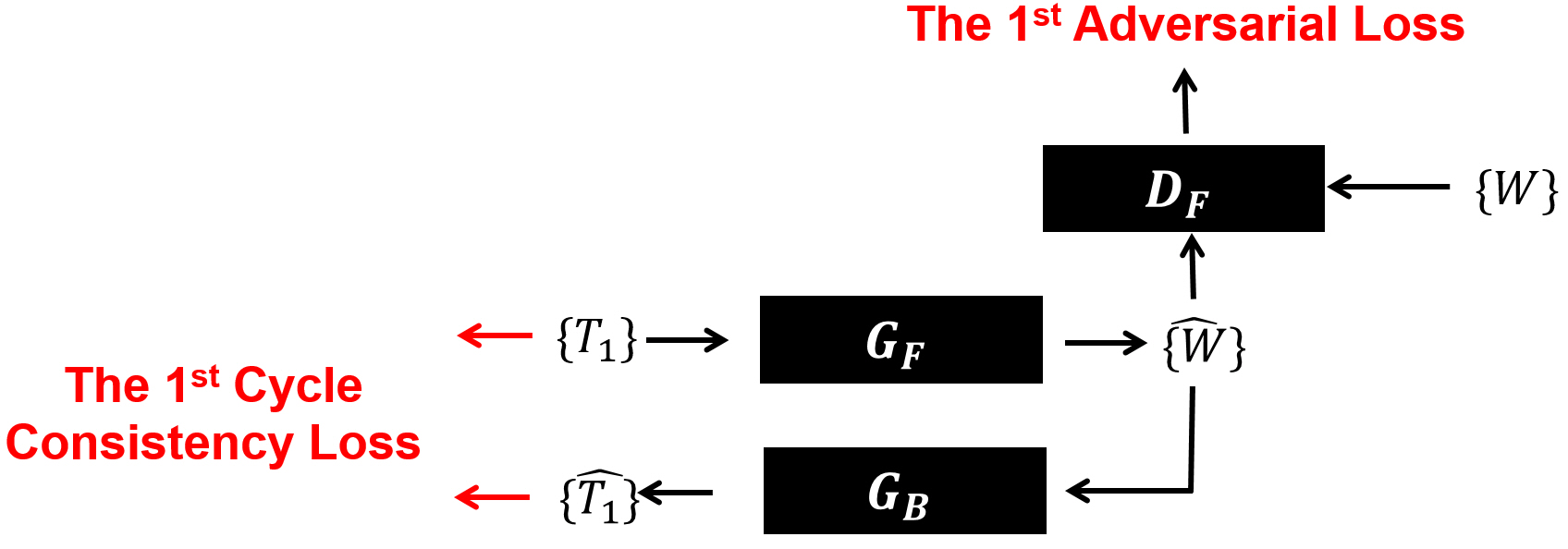
In the proposed method, we assume both forward (from $$$T_{1}$$$ to $$$W$$$) and backward (from $$$W$$$ to $$$T_{1}$$$) image domain transfer functions exist between two unpaired image groups. We then found bi-directional forward and backward “domain-to-domain” or “group-to-group” mapping functions between two unpaired and unordered separate groups ($$$\left\{T_{1}\right\}$$$ and $$$\left\{W\right\}$$$). For this work, a cycle-consistent adversarial network4 originally developed to change photo styles was modified for our application.In the first round of training (Fig. 1), a set of T1-weighted images $$$\left\{T_{1}\right\}$$$ was trained with a series of two image generators ($$$G_{F}\rightarrow G_{B}$$$) to find a self-mapping function ($$$T_{1}\rightarrow\hat{W}\rightarrow\hat{T_{1}}$$$), while trying to reduce errors between input and output image pairs $$$\left\{T_{1},\hat{T_{1}}\right\}$$$. Then, another deep-learning network working as a discriminator ($$$D_{F}$$$) evaluated the created water images $$$\left\{\hat{W}\right\}$$$ from the first generator ($$$G_{F}$$$) by comparing them to the ground-truth water image group $$$\left\{W\right\}$$$.
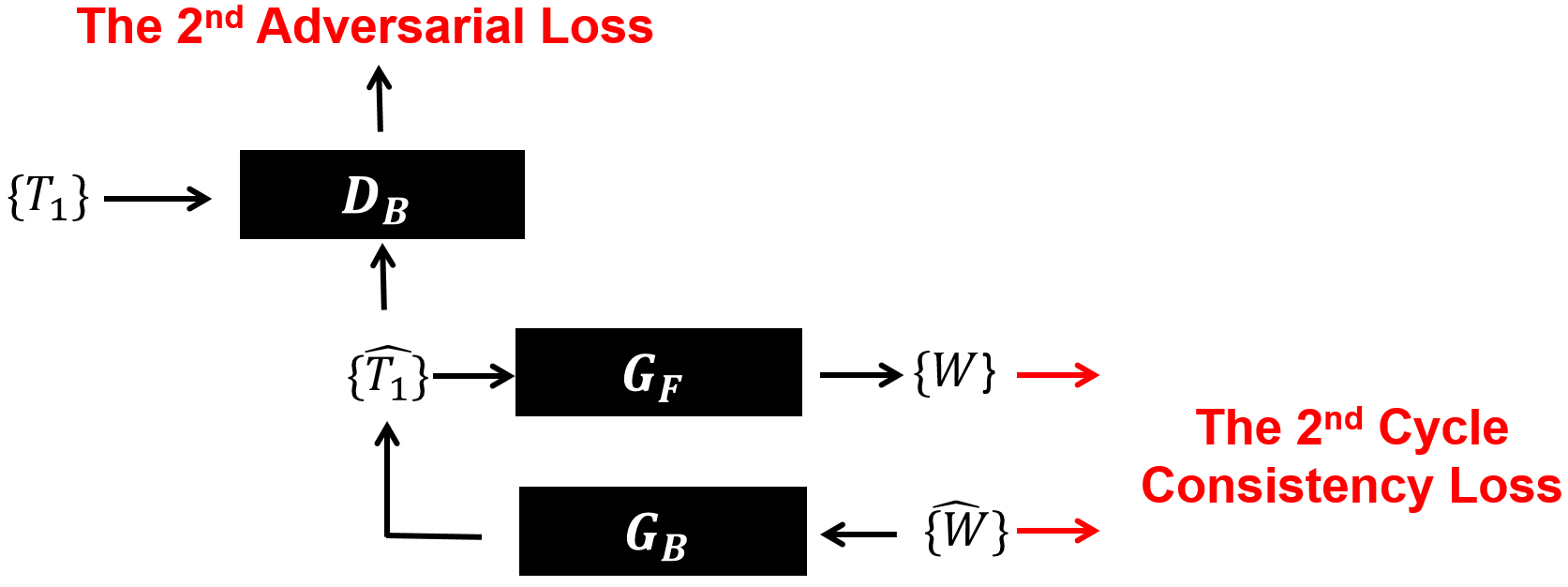
In the second round (Fig. 2), the same generators used for the first round were connected in the reversed order ($$$G_{B}\rightarrow G_{F}$$$), then continued to train for finding another self-mapping function ($$$W\rightarrow\hat{T_{1}}\rightarrow\hat{W}$$$) while trying to minimize errors between another input and output image pairs $$$\left\{W,\hat{W}\right\}$$$. In this step, another discriminator ($$$D_{B}$$$) was used to evaluate output images $$$\left\{\hat{T_{1}}\right\}$$$ from the generator ($$$G_{B}$$$) by comparing them to the ground-truth T1-weighted image group $$$\left\{T_{1}\right\}$$$. The two rounds of training were repeated and alternated until we find both forward and backward mapping functions with the minimized total losses (cycle consistency loss and adversarial loss) measured from both rounds. The entire training work was repeated for the T2-weighted imaging to find other forward and backward image domain transfer functions between $$$\left\{T_{2}\right\}$$$ and $$$\left\{W\right\}$$$.
RESULTS
The proposed network was implemented on a NVIDIA DGX-1 system with a 32GB Tesla V100 GPU (NVIDIA, Santa Clara, CA, USA), then trained separately with unpaired 3,899 sets (3,675 sets for training and 224 sets for validation) of T1-weighted and water-only images from 53 patients, and another unpaired 3,357 sets (3,223 sets and 134 sets) of T2-weighted and water-only images from 78 patients. All of the images were from breast cancer patients and were acquired on a 3T MRI scanner (GE Healthcare, Waukesha, WI, USA) using 8-channel breast coils. The T1-weighted and T2-weighted images were acquired with a 3D fast spoiled gradient-echo two-point Dixon pulse sequence5 (TE1/TE2/TR = 2.0/3.7/8.3ms, Nx x Ny x Nz x NDCE = 512 x 512 x 102 x 5, NFE x NPE1 x NPE2 = 480 x 384 x 102, slice-thickness/slice-gap = 2/0mm, FOV = 30x30x20cm, RBW = ±250kHz, flip-angle=10⁰, and scan-time = 8min 7secs) and a flexible fast spin-echo triple-echo Dixon pulse sequence6 (TE1/TE2/ TE3/TR = 101.3/102.8/104.4/6,060.0ms, Nx x Ny x Nslice = 512 x 512 x 51, NFE x NPE = 384 x 224, slice-thickness/slice-gap = 4/0mm, ETL=13, FOV = 30x30x20.4cm, RBW = ±250kHz, and scan-time = 1min 7secs) for each. We trained our model for 100 epochs using a loss model with a cross-entropy objective (Vanilla GAN), and an adaptive moment estimation (ADAM) optimizer (mini-batch for instance normalization = 6, initial learning rate = 0.0002, and momentum = 0.5). Two generators ($$$G_{F},G_{B}$$$) and two discriminators ($$$D_{F},D_{B}$$$) were implemented with residual neural networks (ResNet)7 and Markovian discriminators (PatchGAN)8-11 having the 70 x 70 receptive field for each.Fig. 3 (a) and Fig. 4 (a) show T1-weighted and T2-weighted in-phase images from the same slice location and the resulting water-only images were shown in Fig. 3 (b) and Fig. 4 (b). The ground-truth water-only images5,6 and pixel-by-pixel error-maps are shown and compared in Fig. 3 (c) and Fig. 4 (c). As indicated with red arrows, both image domain transfer networks for T1 and T2 water-only image reconstructions were successful in both cases.
DISCUSSION AND CONCLUSION
The proposed image domain transfer does not require supervised input and output image pairs, thus it can effectively increase the sample size for the deep-learning training. The image-to-image translation between different image styles was originally developed and has been widely demonstrated outside the field of medical imaging including between artistic painting styles like Monet, Van Gogh, Cezanne, and Ukiyo-e, between summer and winter Yosemite scenes, between zebras and horses, between image edges and photorealistic images, and between semantically segmented labels and photorealistic images.4 Our work shows that the same approach can be successfully used to translate either T1 or T2-weighted images to water-only images.Acknowledgements
No acknowledgement found.References
1. Son JB, Scoggins ME, Dogan BE, Hwang KP, and Ma J. Deep neural network for single-point Dixon imaging with flexible echo time. In Proceedings of the 27th Annual Meeting of International Society of Magnetic Resonance in Medicine. 2019:4014.
2. Langner T, Hedstrom A, Morwald K, Weghuber D, Forslund A, Bergsten P, Ahlstrom H, and Kullberg J. Fully convolutional networks for automated segmentation of abdominal adipose tissue depots in multicenter water-fat MRI. Magnetic Resonance in Medicine. 2018;81(4):1-10.
3. Goldfarb JW, Craft J, and Cao JJ. Water-fat separation and parameter mapping in cardiac MRI via deep learning with a convolutional neural network. Journal of Magnetic Resonance Imaging 2019;50:655-665.
4. Zhu JY, Park TS, Isola P, and Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. In IEEE International Conference on Computer Vision. 2017.
5. Ma J, Son JB, and Hazle JD. An improved region growing algorithm for phase correction in MRI. Magn Reson in Med. 2015;76:519-529.
6. Son JB, Hwang KP, Madewell JE, Bayram E, Hazle JD, Low RN, and Ma J. A flexible fast spin echo triple-echo Dixon technique. Magn Reson in Med. 2017;77:1049-1057.
7. He K, Zhang X, Ren S. and Sun J. Deep residual learning for image recognition. In IEEE International Conference on Computer Vision and Pattern Recognition. 2016.
8. Wang TC, Liu MY, Zhu JY, Tao A, Kautz J, and Catanzaro B. High-resolution image synthesis and semantic manipulation with conditional GANs. In IEEE Conference on Computer Vision and Pattern Recognition. 2018.
9. Isola P, Zhu JY, Zhou T, and Efros AA. Image-to-image translation with conditional adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2017.
10. Ghosh A, Kulharia V, Namboodiri V, Torr PH, and Dokania PK. Multi-agent diverse generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2018.
11. Shrivastava A, Pfister T, Tuzel O, Susskind J, Wang W, and Webb R. Learning from simulated and unsupervised images through adversarial training. In IEEE Conference on Computer Vision and Pattern Recognition. 2017.
Figures