2783
Do We Need CT for Producing a Fully-Automatic 3D Scapular Model? MRI meets Deep Learning for Scapular Bone Extraction1University of California, San Francisco, San Francisco, CA, United States
Synopsis
We present a fully-automatic, 2D deep learning based strategy for extracting scapular shape from a high-resolution MRI scan and we quantify network’s segmentation uncertainty. Our method has the potential to greatly improve the diagnostic process for patients with shoulder instability, rotator cuff tears, and osteoarthritis by decreasing the need for multiple imaging scans and ionizing radiation while still providing clinically-useful information to clinicians.
Introduction
Bone morphology influences treatment outcomes for multiple shoulder conditions, including shoulder instability, rotator cuff tears and osteoarthritis. The current gold standard for evaluating scapular bony morphology is with reconstructions from three-dimensional computed tomography (CT). CT scans, however, are limited in evaluating soft tissue conditions, so magnetic resonance imaging (MRI) and CT scans may both be obtained for thorough clinical evaluation. Furthermore, CT scans use ionizing radiation. All information necessary for a sufficient preoperative plan should ideally be available with one biomedical image for both patient convenience and safety. The purpose of this study is to formulate a deep learning (DL) approach to automatically segment the scapular bone from MR images, and investigate whether network’s predictive uncertainty could support physicians’ diagnoses.Methods
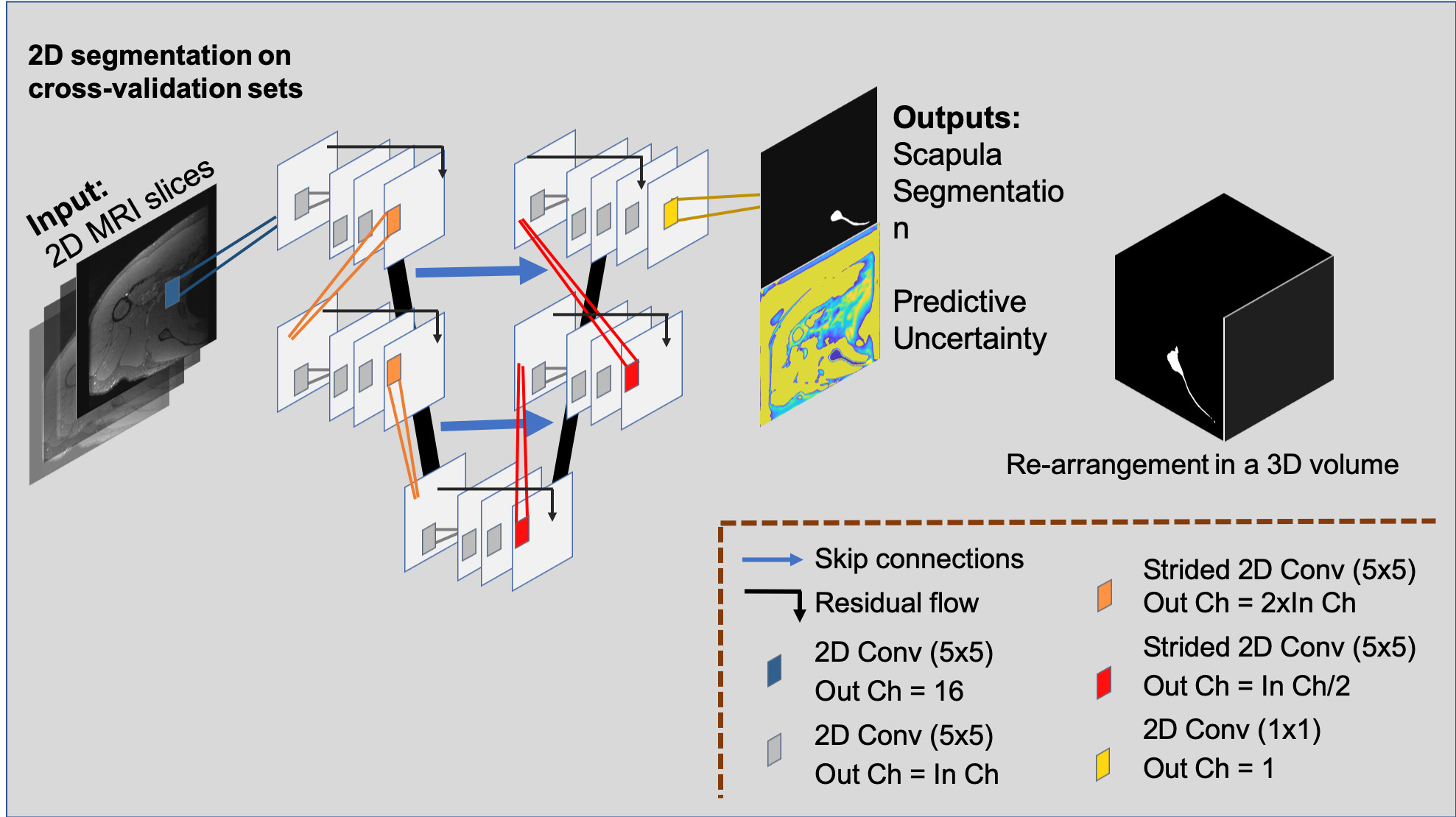
27 high resolution shoulder MRI scans from 27 patients (ages: 52.35±15.07, genders: 10 females/17 males, date range: 08/2018-06/2019) who had a fat-saturated, T2-weighted axial MRI sequence (1 mm slice thickness, 0.375x0.375 mm in-plane resolution, 21.9 echo time, 1352 ms repetition time) were identified through our Picture Archiving and Communication system. Diagnoses of these patients included 4 patients with instability, 14 with rotator cuff tears, 2 with osteoarthritis, and 7 with other conditions. Scans were excluded if there were metal implants, suspected infection, or presence of tumor. The scapula of each MRI was manually segmented with custom, in-house developed Matlab-based software. Two MRIs were manually segmented a second time to account for the intrapersonal variation. In pursuance of a fully automatic MRI-based scapula segmentation framework, we designed a 2D bi-level fully convolutional encoder-decoder framework. This involves 4 consecutive in-level 2D convolutions (kernel size 5), residual connections to facilitate feature and gradient flow at each level1,2,3 and skip-connections between the encoding and decoding paths. The first output block has 16 feature channels, which are doubled at subsequent levels. The available MRI volumes were arranged into 3 cross-validation (CV) training and validation set splits, leveraging age, sex, and diagnoses, and used independently train three deep convolutional neural networks (CNN). Twenty-one of the manually-segmented MRI volumes were selected to populate training sets comprising 16 volumes, and validation sets included the remaining 5 volumes. These were instrumental in evaluating the generalization capability of our machine learning system. The remaining 6 volumes were set aside and utilized to evaluate final model performance. We utilized a 2D CNN approach to maximize available computational resources and maintain contextual information for the learning capability of the network. Processed volumes were flipped to a right-shoulder orientation and dropout was set to a 0.05 drop-probability, reducing the risk of overfitting on the limited data available4. During training, we fed 4 images per batch, and used Adam Optimizer5 (learning rate 10E-4) to minimize the Dice loss function6. The implementation was done using TensorFlow71.12 and computation run on an Intel® Xeon (R) using 1 NVIDIA Titan X GPU. Segmentation evaluation was conducted by means of volumetric Dice Score Coefficient (DSC) and area under the Receiver operating characteristic curve (AUC)8, calculated on the reconstructed volumes predicted with the 3 CV models and their ensemble average. Furthermore, we used Shannon’s entropy equation9 to measure models’ predictive uncertainty, uncertainty that could be explained away with more data10. Figure 1 illustrates the proposed framework.Results and Discussion
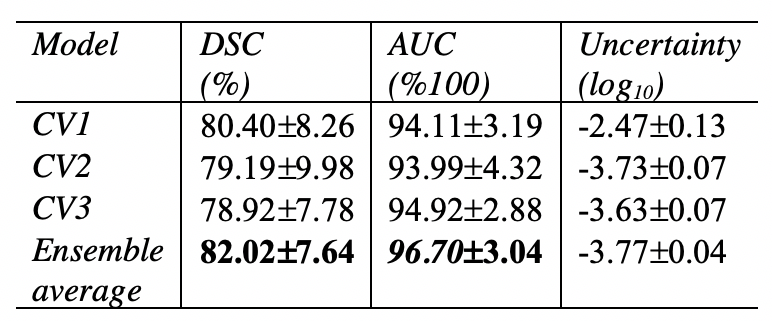
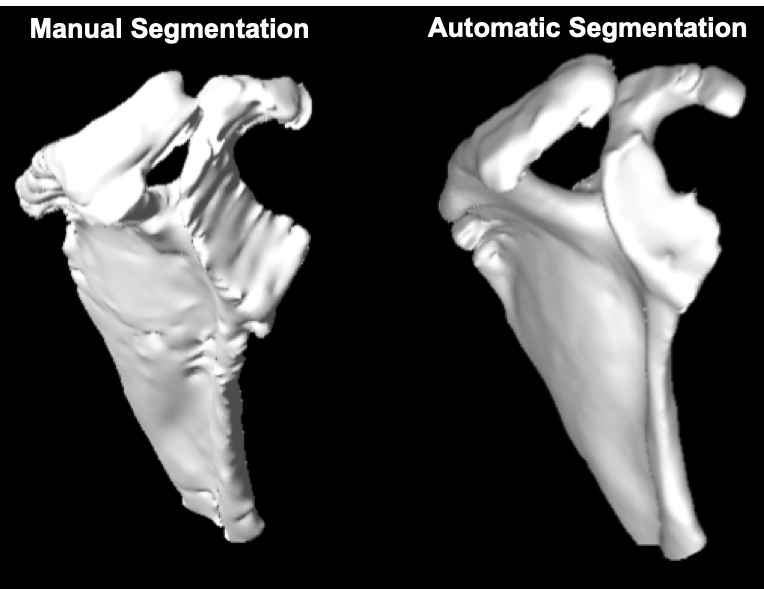
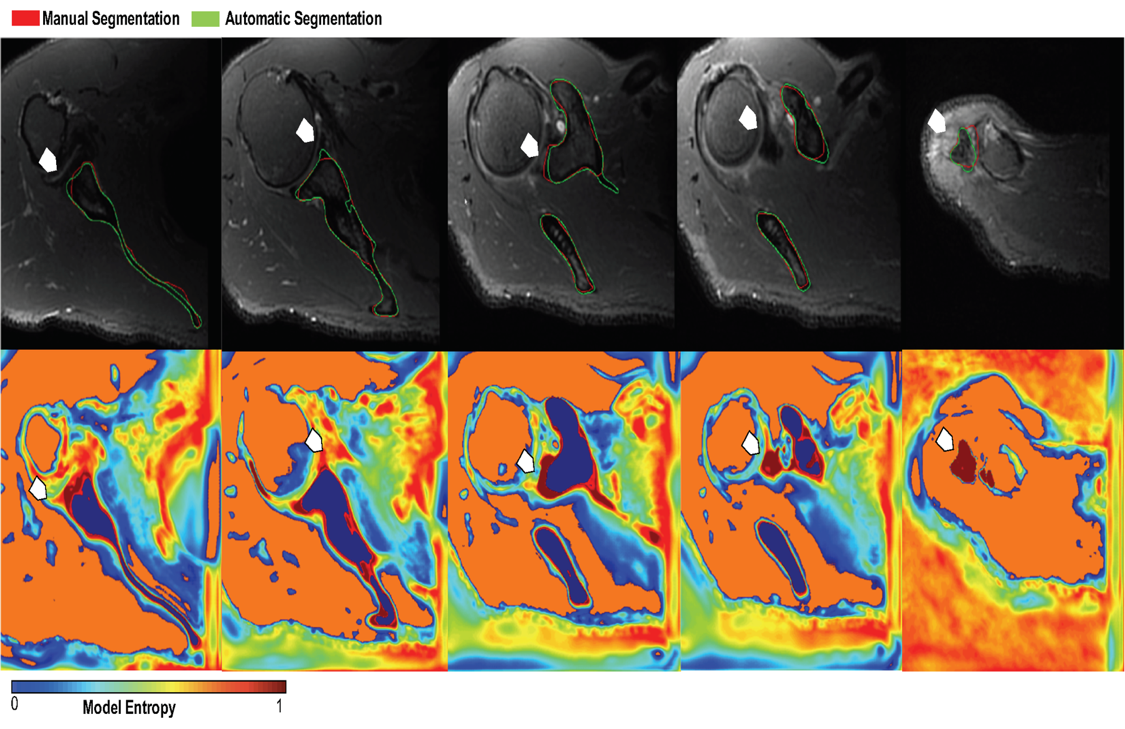
The quantitative models’ performance on the separate test set of 6 MRI scans are reported in Table 1. Results suggest that the best performing model (AUC=96.70±7.64, DSC=82.02±3.04) is an ensemble of the 3 networks each trained on a cross-validation set. The ensemble of the 3 networks also allowed for higher predictive uncertainty, reflecting less of an effect of overall bias introduced by training data. Figure 2 shows that areas of higher uncertainty were located more at the glenoid. Figure 3 depicts a qualitative segmentation result with a manual segmentation displayed adjacent to a fully automatic segmentation extracted without any manual input. As it can be observed the segmentation obtained by using our ensemble network (right) appears smoother than the manual annotation (left). We suggest this is due to an intrinsic property of the network, which despite performing segmentation per slice, it can utilize contextual information coming from other slices, and be more precise/consistent in placing scapular boundaries. Conversely, 2D manual annotators reason only on a per slice basis, which in the presence of diffuse image edges, can result into coarser edges, irrespective of their experience. The DSC for manual re-segmentation on two volumes was 90.64±2.20.Conclusions
We proposed a fully automated 2D CNN approach for automatic scapular shape extraction from high-resolution MRI. Our ensemble of three networks produced scapular models that were similar to manually-defined scapulae. There is still some residual difference between the automatically-extracted shape and the manually-defined segmentation, though the MRI-based segmentation may limit the ground truth in this case. Our future research direction will validate these measurements relative to CT scans or potentially cadaveric models to understand the true expected error with MRI-based automatic shape extraction and whether these differences are clinically relevant.Acknowledgements
This project was partially supported by R00AR070902.References
1. He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
2. Goodfellow, Ian, et al.“Deep learning”. MIT press, 2016.
3. Veit, Andreas, et al."Residual networks behave like ensembles of relatively shallow networks." Advances in neural information processing systems. 2016.
4. Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." The journal of machine learning research 15.1 (2014): 1929-1958.
5. DiederikP Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXivpreprint arXiv:1412.6980, 2014.
6. Fausto Milletari, et al. “V-net: Fully convolutional neural networks for volumetric medical image segmentation”. In 2016 Fourth International Conference on 3D Vision (3DV), IEEE, 2016.
7. Martìn Abadi, et al. Tensorflow: A system for large-scale machine learning. In OSDI, 2016.
8. Taha, Abdel Aziz, and Allan Hanbury. "Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool." BMC medical imaging 15.1 (2015): 29.
9. Ghahramani, Zoubin. "Information theory." Encyclopedia of Cognitive Science (2006).
10. Kendall, Alex, and Yarin Gal. "What uncertainties do we need in bayesian deep learning for computer vision?." Advancesin neural information processing systems. 2017.
Figures