2390
Augmented ensemble learning is effective strategy for imbalanced small dataset: improve differentiation of low from high grade prostate cancer1Philips Japan, Tokyo, Japan, 2Department of Radiology, Kobe University Graduate School of Medicine, Hyogo, Japan, 3Asia Pacific, Philips Healthcare, Tokyo, Japan
Synopsis
Machine learning (ML) techniques have gained more attention to distinguish low from high grade prostate cancer. However, obtaining big training data is difficult. Moreover, ML models created by imbalanced dataset have a high accuracy for majority, but a low accuracy for minority. For this problem, data augmentation is widely studied. Recently, ensemble learning, which merges different classifiers, has shown great potential. Combinations of data augmentation and ensemble learning were investigated, using multi-parametric MR. We demonstrated that synthetic-minority-over-sampling-technique (SMOTE) with ensemble learning showed increased F1 (0.831) and AUC (0.762) and is effective strategy to improve diagnosis performance for imbalanced small dataset.
INTRODUCTION
It is clinically important to distinguish low grade (Gleason score (GS) ≦ 3+4) from high grade (GS ≧ 4+3) prostate cancer (PCa) because its prognosis greatly differs.1 For differentiation of low from high grade PCa, multi-parametric magnetic resonance imaging (mp-MRI) which combines diffusion-weighted image (DWI) and dynamic contrast-enhanced MRI (DCE-MRI) has been studied.2 However, because studies differ in scan protocols and analysis, no consensus about diagnostic criteria has been made.Recently, machine learning (ML) techniques have gained more attention.3 However, obtaining big training dataset is difficult in medical industry.4 Moreover, because occurrence of diseases/low grade tumor is much less than healthy cases/high grade tumor, imbalanced data frequently appears.5 ML models created by imbalanced dataset will result in a high prediction accuracy for the majority, but a very low accuracy for the minority. To deal with the imbalance class problem, synthetic-minority-over-sampling-technique (SMOTE)6 and random-over-sampling-examples (ROSE)7 are widely used data augmentation methods applied to numerical data.8
As a new approach, stacking ensemble learning techniques, ML processes merging different classifiers to improve model generalization capability, have shown great potential.9-10 In this study, we show how a combination of data augmentation and ensemble learning can improve the prediction accuracy to differentiate low from high grade PCa, trained from an imbalanced small dataset.
METHODS
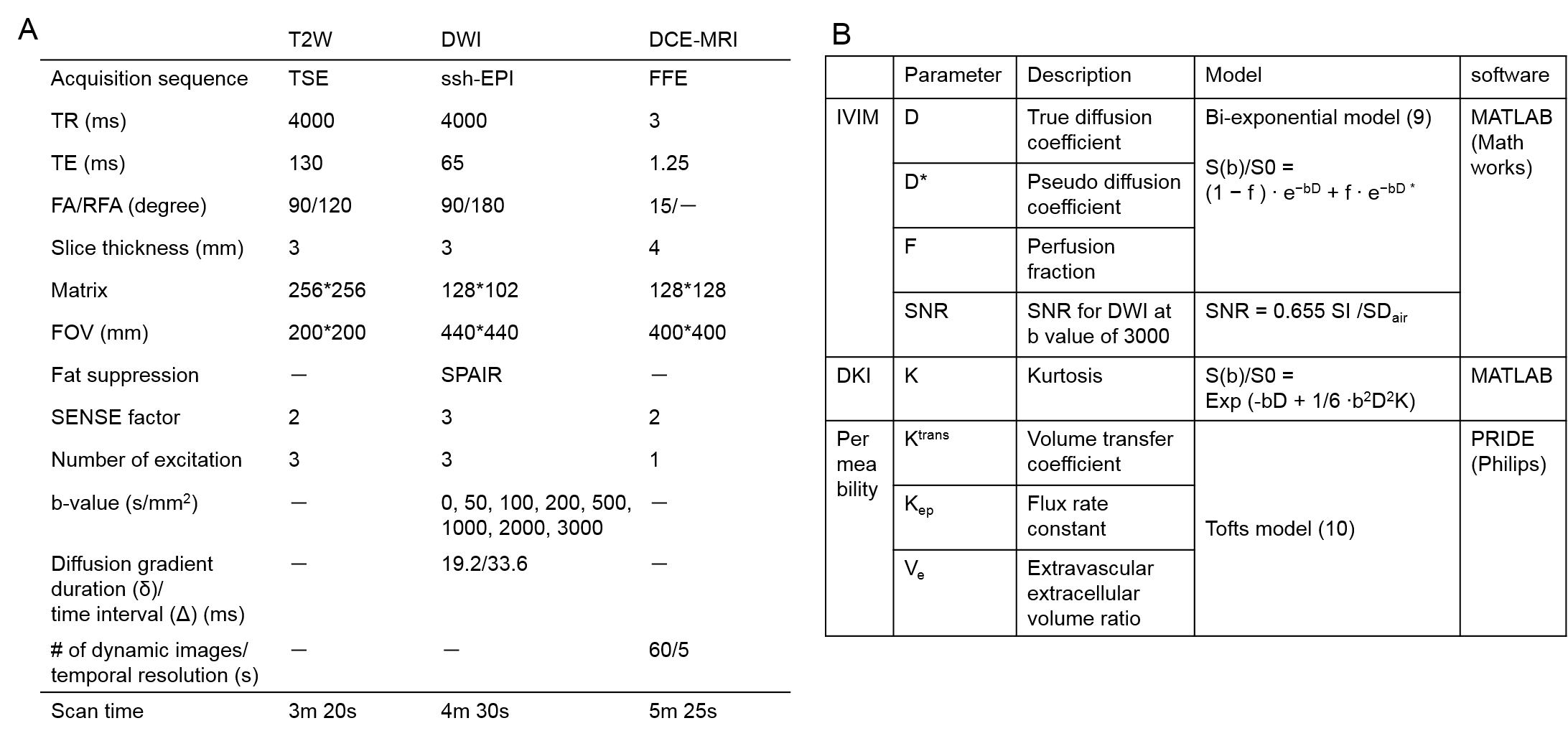
Subject and equipment: The retrospective study was approved by the hospital review board and informed consent was waived. 39 patients underwent preoperative MRI using a 3.0-T MR scanner (Achieva, Philips) between September 2012 and December 2013. Regions-of-interest (ROIs) were placed on 15 low grade and 25 high grade PCa in peripheral zone (PZ), based on histopathology specimen. The ratio of high grade (majority) to low grade PCa (minority) was 1.67. We think the dataset was relatively small and imbalanced.DWI and DCE-MRI: T2W, DWI, and DCE-MRI were obtained.11-12 Sequence parameters are summarized (Table 1A). Intravoxel incoherent motion (IVIM), diffusion kurtosis imaging (DKI), and permeability analyses were conducted. IVIM parameters (D, D*, and F), DKI (K), SNR, and permeability parameters (Ktrans, Kep, and Ve), and respective models are summarized (Table 1B). Mean within ROI was calculated for each parameter.
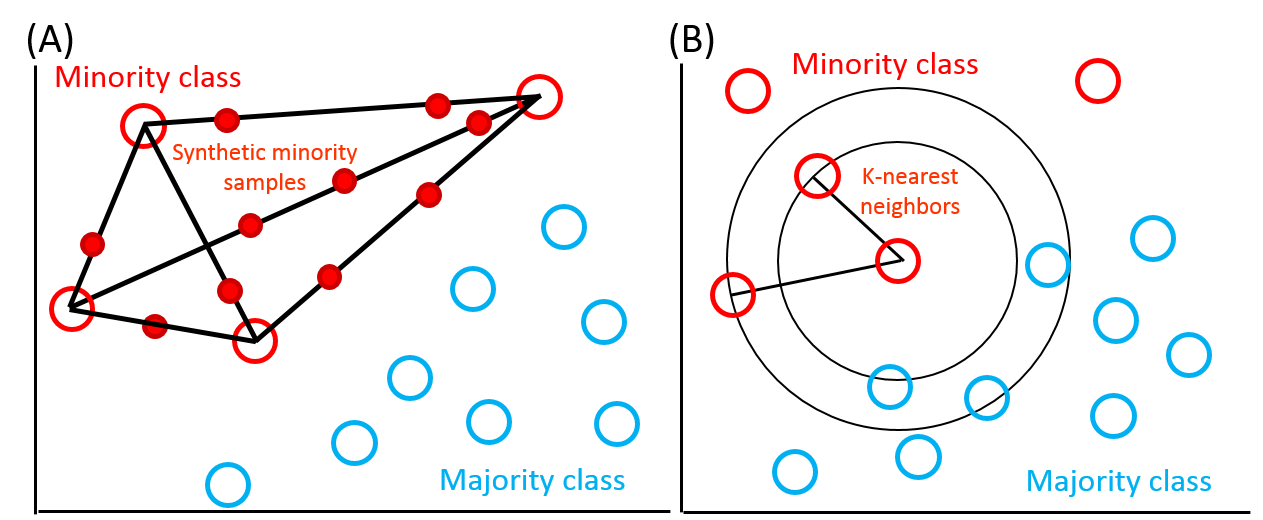
Data augmentation: The SMOTE algorithm generates synthetic examples through a linear interpolation between two existing minority examples (Fig 1A). The synthetic example xnew is generated by Xnew = X + rand (0,1) * (X~ - X) (1) , where rand (0,1) is a random value in (0,1). X~ is a random example of K-nearest minority class (Fig 1B). The number of K-nearest neighbors was set to five.8
ROSE is a smoothed bootstrap-based technique to generate new examples from the minority class in its neighborhood, where neighborhood is determined by the shape of the contour of the kernel and its width is governed by the covariance matrix.7 SMOTE and ROSE can also randomly under sample the majority class to match the number of minority class.
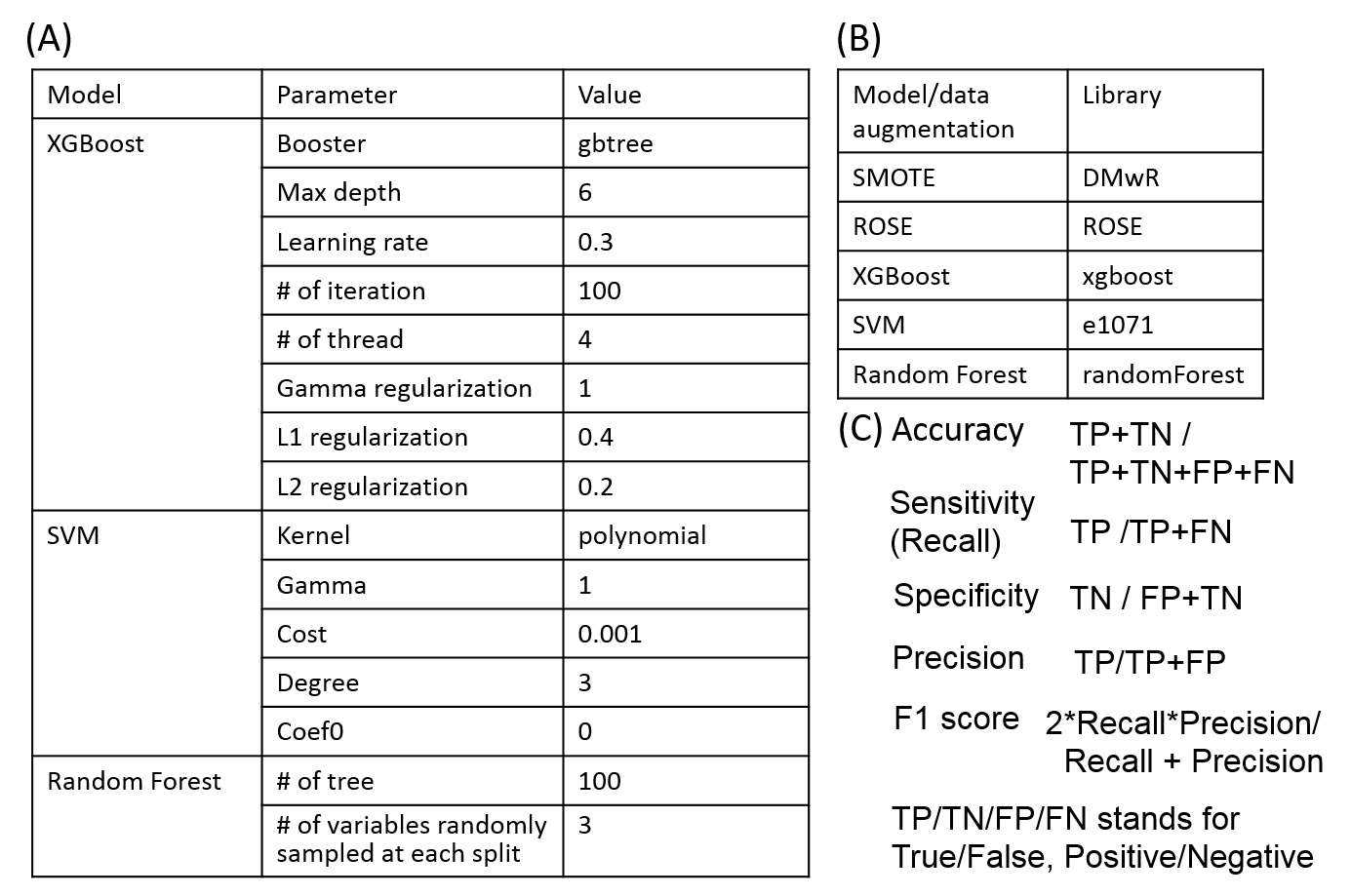
Ensemble learning: The stacking ensemble model can be constructed by merging different models. eXtreme Gradient Boosting (XGBoost)13, support vector machine (SVM)14, and random forest (RF)15 were chosen as base models. Prediction of the ensemble model was decided by simple majority voting from the three models.9 Data augmentation and ML model development were conducted using R software (v3.5.1) and the parameters and libraries are summarized (Table 2A, B). SVM regularization parameters were optimized by a grid search.
Evaluation metrics: Data augmentation and ensemble learning were evaluated by 5-fold cross validation. Data augmentation was only incorporated to training dataset. ML models were trained from the augmented dataset. Intact test dataset was used to evaluate model performance.
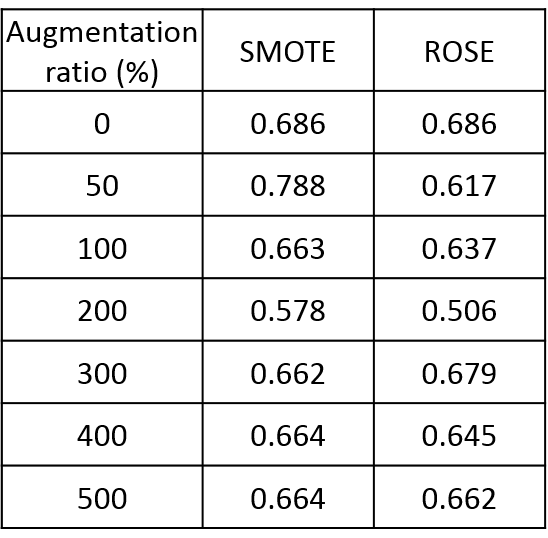
To compare efficacy of SMOTE and ROSE, accuracy of the ensemble model was assessed by changing augmentation (increment) ratio from 0% to 500%. To compare the ensemble model and base models using best augmentation method which was decided by above assessment, accuracy, sensitivity, specificity, F1 score, and area under the curve of receiver operation characteristics (ROC) (AUC) were assessed. The definition of each metrics was summarized (Table 2C). A paired t-test was used and a P- value less than 0.05 was considered significant.
RESULTS
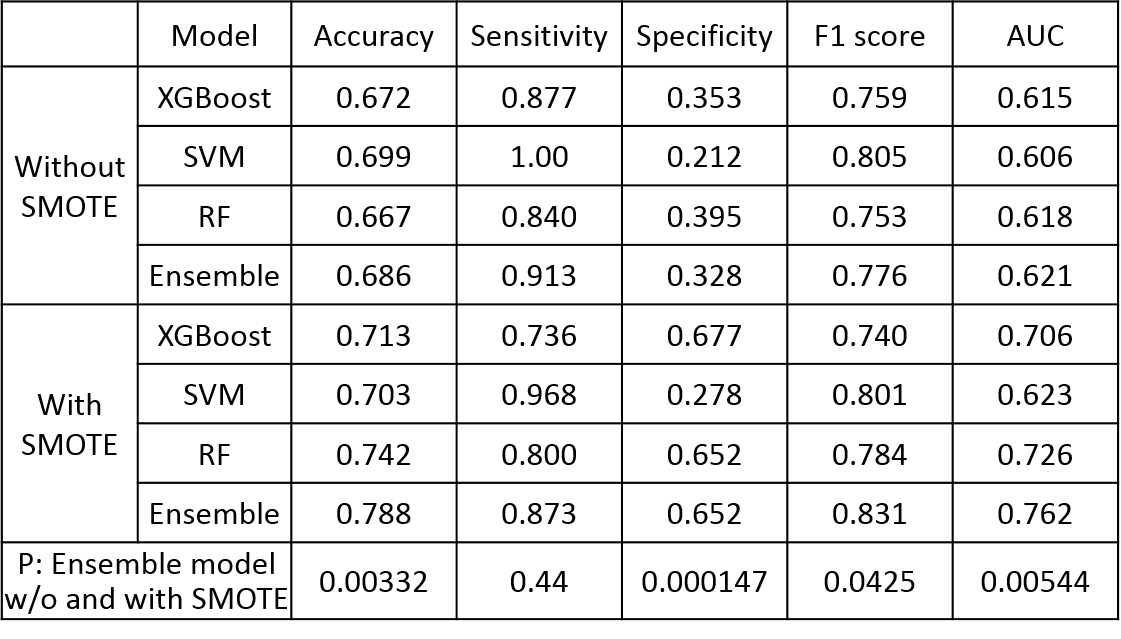
Comparison of SMOTE and ROSE is shown in Table 3. The overall accuracy for SMOTE to differentiate low from high grade PCa in PZ was higher than ROSE. Accuracy for ensemble model using SMOTE was not improved at augmentation ratio more than 100%. Accuracy was not improved by ROSE. The best accuracy of 78.8% using SMOTE was obtained at augmentation ratio of 50%.Evaluation of the ensemble model compared to base models was summarized in Table 4. Without SMOTE, ensemble model showed higher AUC and comparable performance in other evaluation metrics to base models. Using 50% augmentation SMOTE, ensemble model showed overall higher performance than base models, except for sensitivity of SVM and specificity of XGBoost. Accuracy, sensitivity, specificity, F1 score, and AUC for the ensemble model using SMOTE were significantly higher than those without SMOTE (p=0.00332, 0.44, 0.00147, 0.0425, and 0.00544, respectively).
CONCLUSION
We demonstrated the feasibility of SMOTE data augmentation with ensemble learning technique on mp-MRI for differentiating low from high grade PCa. The results indicate that the proposed method is an effective strategy to improve prediction accuracy for an imbalanced small dataset.Acknowledgements
No acknowledgement found.References
1. Epstein JI et al. The 2014 International Society of Urological Pathology (ISUP) Consensus Conference on Gleason Grading of Prostatic Carcinoma: Definition of Grading Patterns and Proposal for a New Grading System. Am J Surg Pathol. 2016:40:244–252
2. Rooij M et al. Accuracy of multiparametric MRI for prostate cancer detection : A meta-analysis. Am J Roentgenol. 2014;202 :343-351
3. Shah V et al. Decision support system for localizing prostate cancer based on multiparametric magnetic resonance imaging. Med Phys. 2012;39:4093-4103
4. Razzak MI et al. Deep Learning for Medical Image Processing: Overview, Challenges and Future. In Classification in BioApps. Springer. 2018:323–350
5. He H and Garcia E. Learning from imbalanced data. IEEE Trans Knowledge Data Eng. 2009:21: 1263-1284
6. Chawla N et al. SMOTE : Synthetic Minority Over-Sampling Technique. J. Artifcial Intelligence Research. 2012:16:321-357
7. Menardi G and Torelli N. Training and assessing classification rules with imbalanced data. Data Min Knowl Disc. 2014:28:92–122
8. Chaudhury B et al Identifying metastatic breast tumors using textural kinetic features of a contrast based habitat in DCE-MRI. Proc. SPIE. 2015:9414:941415
9. Rokach L. Ensemble-based classifiers. Artificial Intelligence Review. 2010:33:1-2
10. Iftikhar MA and Idris A. An Ensemble Classification Approach for Automated Diagnosis of Alzheimer’s Disease and Mild Cognitive Impairment. In: 2016 international conference on open source systems and technologies (ICOSST), pp 78–83
11. Ueda Y et al. Triexponential function analysis of diffusion-weighted MRI for diagnosing prostate cancer. JMRI. 2016;43:138-146
12. Akamine Y et al. Application of hierarchical clustering to multi-parametric MR in prostate: Differentiation of tumor and normal tissue with high accuracy. In:Proc 27th Annual Meeting of ISMRM, Montreal 2019;1615
13. Chen T and Guestrin C. Xgboost: a scalable tree boosting system. In: Proceedings of the 22Nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016:785–794
14. Vapnik V.N. The Nature of Statistical Learning Theory. New York: Springer-Verlag.1995
15. Liaw A and Wiener M. Classification and Regression by randomForest. R News, 2002, 2/3:18–22
Figures