2374
Breast Lesion Segmentation in MR Images through Knowledge Distillation-based Modality Speculation1Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 2Department of Radiology, Guangdong General Hospital, Guangdong Academy of Medical Sciences, Guangzhou, China, 3Department of Electronic Information Engineering, Nanchang University, Nanchang, China
Synopsis
Multi-modal MR images are widely utilized to overcome the shortcomings of single modalities and pursue accurate image-based diagnoses. However, multi-modal MR imaging takes a longer time. For automated diagnosis, misalignment between modalities brings extra problems. To address these issues, we propose a new strategy to speculate the modality information by distillation-based knowledge transfer. Experiments on breast lesion segmentation confirm the feasibility of the proposed method. Networks trained with our method and single-modal MR image inputs can partially recover the breast lesion segmentation performance of models trained using two-modal MR images.
Introduction
Breast cancer is one of the most prevalent cancer types in females worldwide. Diagnosis in the early stages is vital for the long-term survival rates of patients 1. Magnetic resonance imaging (MRI) has already become a routine screening technique for breast cancer in the clinic. Contrast-enhanced MRI is the primary modality utilized thanks to its high sensitivity, whereas the relatively low specificity leads easily to false positive predictions 2,3. Multi-modal MR image-based diagnosis can effectively solve this issue.In our previous work, we have confirmed that by combining contrast-enhanced T1-weighted (T1C) MR images with T2-weighted (T2W) MR images, higher breast lesion segmentation accuracy can be obtained. However, multi-modal MR image acquisition takes a longer time. For breast lesions, physiological movements, such as breathing, can cause misalignment between the different modal images, which brings new issues to the segmentation task. In this study, inspired by knowledge distillation 4, we propose a new strategy to automatically speculate the multi-modal image information with only one modality inputs. Utilizing the proposed optimization strategy, models with only T1C inputs can partially recover the performance of multi-modal models.
Methodology
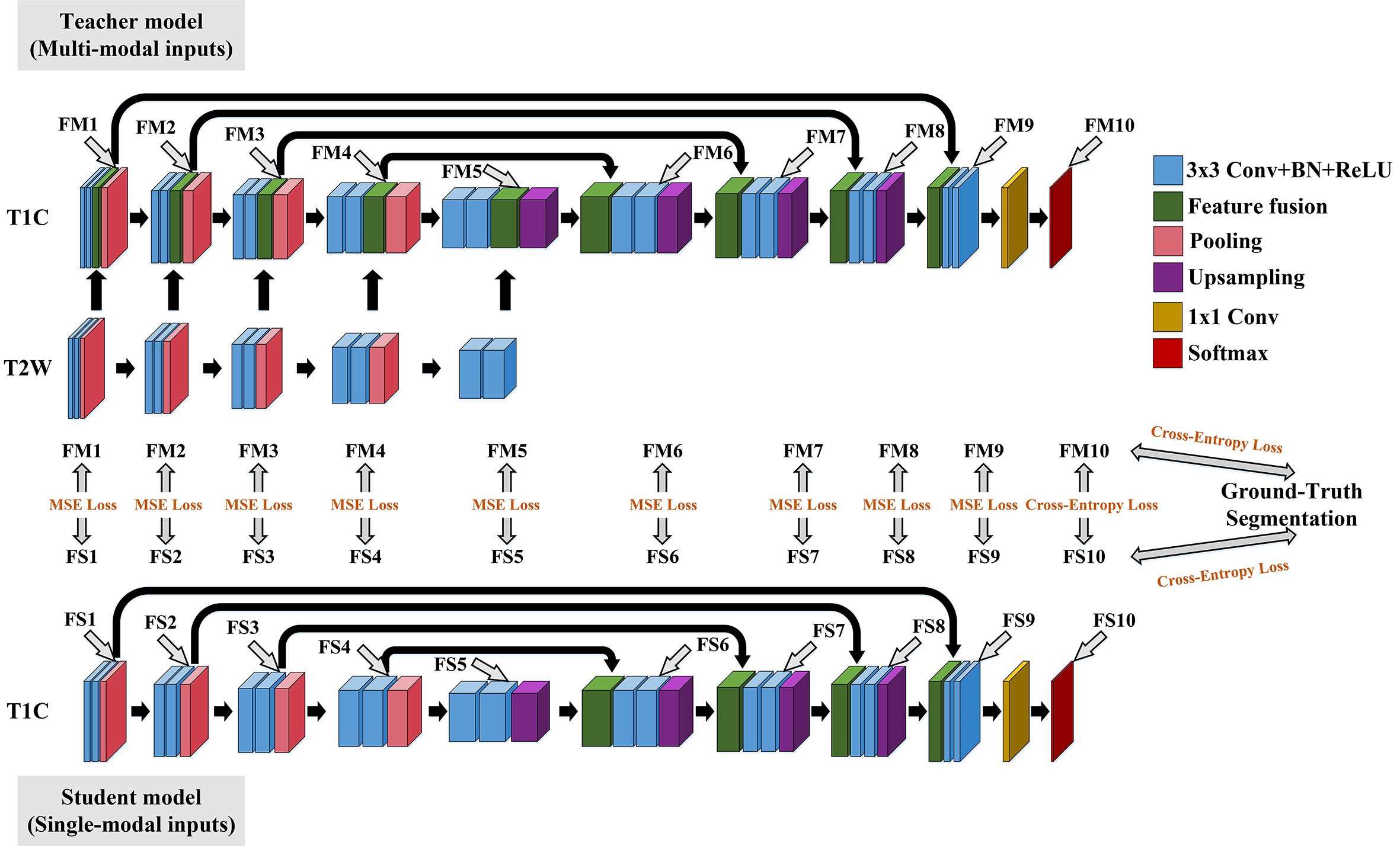
The overall framework of our proposed method is shown in Figure 1. We have a teacher model to extract important knowledge from multi-modal inputs. The details of the teacher model are shown in Figure 1. The feature fusion is conducted through attention-guided channel-wise concatenation. We have a student model that receives the knowledge from the teacher model, which is a plain UNet in this study 5. For the network training, we first train the teacher model with the segmentation loss (Dice loss and cross-entropy loss) between the network outputs and the ground-truth segmentations. With the optimized teacher model, we train the student model with supervision from both the teacher model and the ground-truth segmentations.Different knowledge transfer strategies between the teacher model and the student model have been investigated. We have tested transfer only the last layer (between FM10 and FS10 in Figure 1, named as Proposed_M1), transfer the first five and the last layers (Proposed_M2), transfer the last six layers (Proposed_M3), transfer all the ten layers (Proposed_M4), and transfer the last nine layers (Proposed_M5). The loss function utilized is composed of segmentation loss and knowledge distillation loss. The segmentation loss is the same as that used for the training of the teacher model. The knowledge distillation loss adopts either mean square error loss or cross-entropy loss as shown in Figure 1. We empirically set a weight of 0.5 to the distillation loss in this study. During testing, the student model is applied, which requires only T1C inputs.
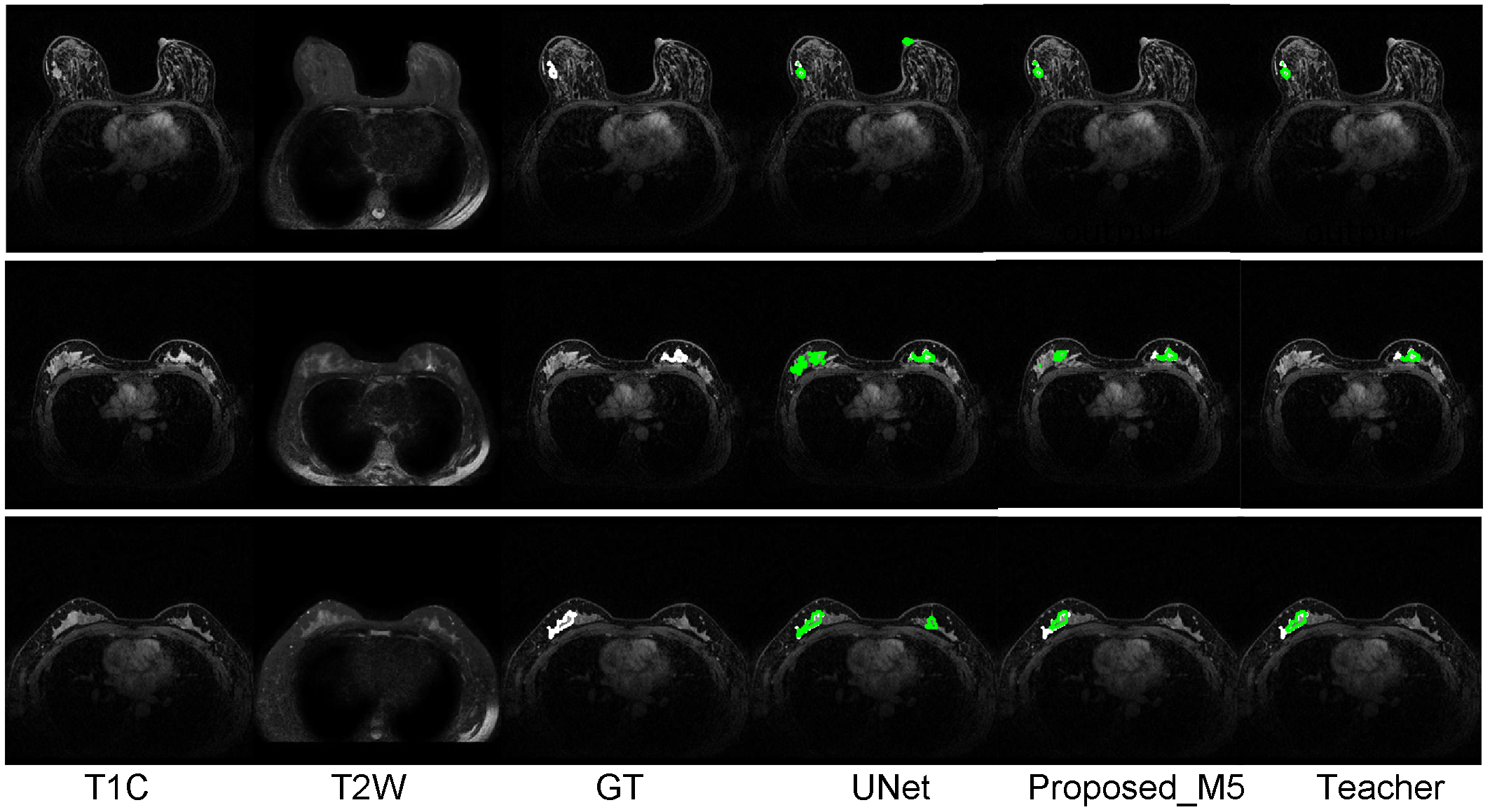
The performances of the different networks or different optimization strategies are evaluated on a clinic dataset with approval from the local ethics committee. The images were collected on a Philips Achieva 1.5T system using a four-channel phased-array breast coil. In total, we obtained two modal MR scans (T2W and T1C) from 313 patients (examples see Figure 2). To avoid the laborious and difficult 3D manual breast lesion segmentation, only the central slices with the largest cross-section areas were utilized in this study. Five-fold cross-validation experiments with three repetitions were conducted. Results are presented as mean ± s.d. Differences between the different models were evaluated by t-test with a significance threshold of p < 0.05.
Results and Discussion
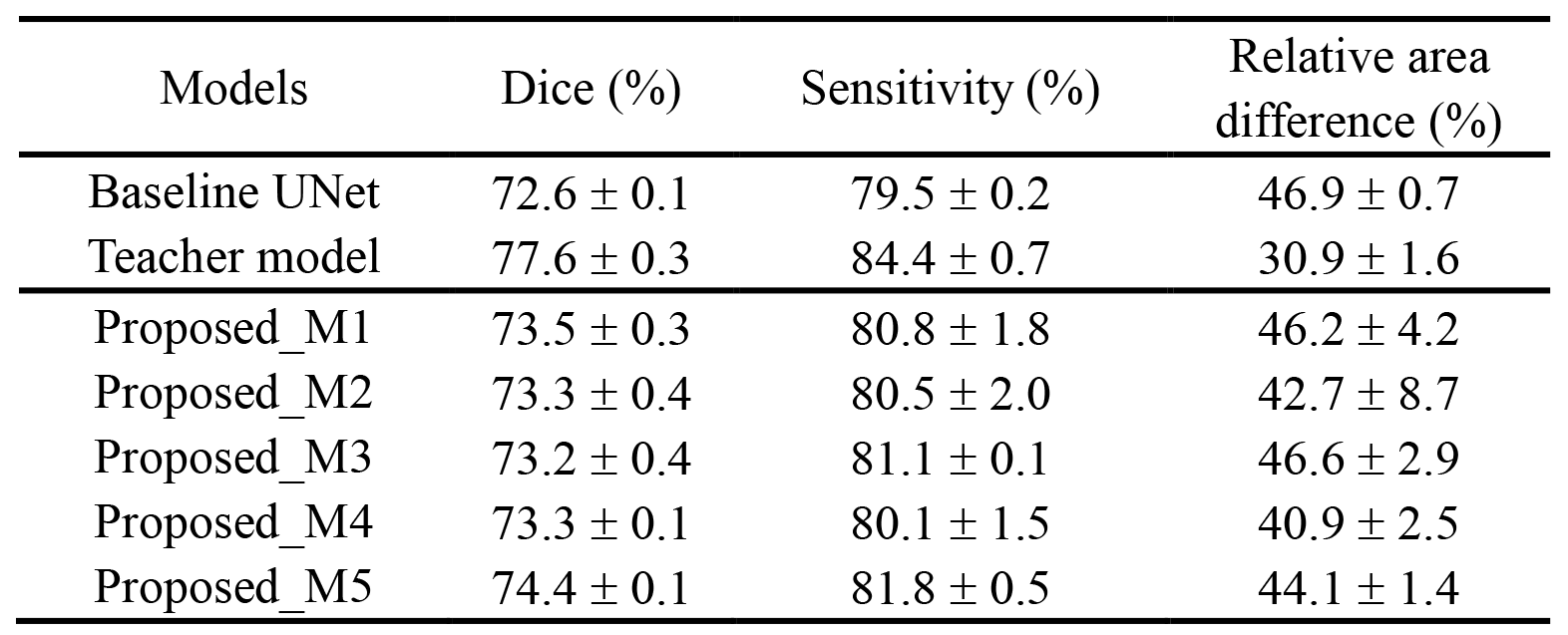
We compare the breast lesion segmentation performance of our proposed method to the UNet model, which is trained with supervision from the ground-truth segmentation, and the teacher model, which requires both T1C and T2W inputs. Three evaluation metrics are calculated, the Dice similarity coefficient, sensitivity, and relative area difference (Table 1). Obviously, the teacher model achieves much better performance than the baseline UNet. With the proposed knowledge transfer strategies, the UNet can partially recover the performance of the teacher model. It is to be noted that all the proposed models have the exact same network structure as the baseline UNet. They are only trained with different supervisions. Model Proposed_M5 achieves the best overall segmentation performance among the five tested transfer strategies (all three metrics are statistically significantly better than those generated by the baseline UNet with p < 0.05 by t-test), which indicates that the knowledge transfer needs to be carefully modulated. Several segmentation results generated by the three models are shown in Figure 2. It can be observed that the proposed model can achieve better performance than the baseline UNet, especially in reducing false-positive predictions. Nevertheless, the teacher model is always the best in this breast lesion segmentation task.Conclusion
In this study, a knowledge distillation-based modality speculation method was proposed. Training with the proposed method, models requiring only one modal MR image inputs can partially recover the segmentation performance of networks developed based on multi-modal images. The current method can be further optimized since the loss functions and the transferring features are empirically determined. After further optimization, the proposed method has the potential to be applied to help speed up the MR image acquisition in the clinic and improve the automatic breast image diagnosis systems.Acknowledgements
This research was partially supported by the National NaturalScience Foundation of China (61601450, 61871371, 81830056), Science and TechnologyPlanning Project of Guangdong Province (2017B020227012, 2018B010109009), the Basic Research Program of Shenzhen (JCYJ20180507182400762), and Youth InnovationPromotion Association Program of Chinese Academy of Sciences (2019351).References
1. Barber MD, Jack W, Dixon JM. Diagnostic delay in breast cancer. Br J Surg. 2004; 91(1):49–53.
2. Heywang-Köbrunner SH, Viehweg P, Heinig A, Küchler C. Contrast-enhanced MRI of the breast: accuracy, value, controversies, solutions. Eur J Radiol. 1997; 24(2):94–108.
3. Westra C, Dialani V, Mehta TS, Eisenberg RL. Using T2-weighted sequences to more accurately characterize breast masses seen on MRI. Am J Roentgenol. 2014; 202(3):183–90.
4. Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. NIPS Deep Learn Represent Learn Work. 2015; p. 1–9.
5. Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: MICCAI. Springer; 2015. p. 234–41.
Figures