2228
The Apprentice Surpasses the Master: Training a Neural Network for Cardiac Segmentation Using a Specialized Network and Indirectly Labeled Data
Markus J. Ankenbrand1, David Lohr1, Tobias Wech2, and Laura M. Schreiber1
1Chair of Cellular and Molecular Imaging, Comprehensive Heart Failure Center (CHFC), University Hospital Würzburg, Würzburg, Germany, 2Department of Diagnostic and Interventional Radiology, University Hospital Würzburg, Würzburg, Germany
1Chair of Cellular and Molecular Imaging, Comprehensive Heart Failure Center (CHFC), University Hospital Würzburg, Würzburg, Germany, 2Department of Diagnostic and Interventional Radiology, University Hospital Würzburg, Würzburg, Germany
Synopsis
Training of neural networks for segmentation of CMR images requires large amounts of labeled data and network generalization is biased by training data characteristics. We used a specialized network to label a heterogeneous, publicly available dataset of 1140 cine images with known left-ventricular volumes. We evaluated the performance of this network using true and predicted volumes and trained another neural network on subjects with high prediction accuracy using extensive data augmentation. The resulting network outperforms the original one on the full dataset, even on subgroups where the original network fails, indicating great generalization and thus suitability for transfer learning applications.
Introduction
The use of deep learning methods in medical imaging is increasing over the last years1. These algorithms improve tasks ranging from reconstruction over image quality transfer to classification and segmentation. One area of interest in cardiac magnetic resonance is segmentation of the ventricles and myocardium in cine sequences. Diagnostic values like volumes, mass and ejection fraction are derived from the segmentation. However, large amounts of manually labeled data are required for training. Furthermore, the resulting networks are specialized to the characteristics of this training data (e.g. age, ethnicity, magnetic field strength). As fully labeled public data sets are sparse and published networks are specialized, this study aimed to combine a public dataset containing a large amount of cine images with corresponding volume information for end-systolic (ESV), end-diastolic volume (EDV)2 and a specialized semantic segmentation network trained on the UK Biobank3 to train a more generalized neural network.Methods
The Data Science Bowl Cardiac Challenge Data2 (further DSBCC data) contains short axis cine images of 1140 subjects. It is a diverse selection of cases from different hospitals covering all age groups and including cases with normal and abnormal cardiac function. In addition to the images, ground truth for ESV and EDV of the left ventricle is available. In order to use this data set to train a segmentation algorithm we curated it and converted the DICOMs to a single 4D matrix with proper metadata per subject, removing duplicate slices and other inconsistencies. Subsequently, we performed an initial segmentation of left ventricle and myocardium with a published network3 pre-trained on UK Biobank data (further called UKBB network) to label left-ventricle and myocardium in this data set. All cardiac magnetic resonance data in UK Biobank (UKBB) has been acquired using a standard protocol4.We evaluated the performance of this network and split the data into sub-sets of different fidelity depending on the relative deviation of predicted to true volumes (5%, 10%, and 15%). We then trained neural networks (U-Net5 based on resnet346 pre-trained on ImageNet7 using fastai v18) on the different fidelity sets using extensive data augmentation (different values for rotation, zoom, contrast, brightness, warp) and different image sizes (128px and 256px). Finally, we compared our predictions with those of the UKBB network regarding their deviation from the ground-truth-values.
Results
In total, there are 372,839 DICOM short axis images in the DSBCC data set2 of which 354,795 passed data curation and were segmented with the pre-trained UKBB model. Derived end-systolic and end-diastolic volumes for most subjects is close to the true volume as expected. However, for a notable fraction, the estimated volumes are too low, sometimes even zero indicating complete segmentation failure (Figure 1). Age group and rotation have an influence on relative deviation of the predicted volume by the UKBB network to the true volume (Figure 2). For both factors, the re-trained network with data augmentation learns to better predict the true volumes while the prediction for rotated images remains slightly biased (Figure 3). Comparison of the deviations of prediction to ground truth on the full data set for all six re-trained models (3 confidence sets, 2 image sizes) are similar and better than the UKBB network (Figure 4). The best performance on the full dataset is achieved by the 10% fidelity set at image size 256px (Table 1).Discussion
We demonstrate that the UKBB network can be used to estimate volumes with sufficient accuracy in many cases in the DSBCC data. However, the generalization beyond the training data is not optimal. It is particularly apparent for young ages as UK Biobank only covers ages 40 to 69. This lack of generalizability is neither surprising nor a critique of the UKBB network as the authors in that paper clearly state this as a limitation of their work3. However, the aim of our study was to test whether labels created from the UKBB network in cases where it works can still help to train a more generalized network through data augmentation.Indeed, we demonstrated that our re-trained networks with data augmentation generate segmentations that result in volumes closer to the ground truth than the UKBB network. In this sense, our network surpasses the one that created the labels for training, by showing better generalization. However, to be fair, it is not a direct comparison of segmentation performance and the UKBB network was not intended for good generalization. Another limitation of our study is that the comparison of left-ventricular end-systolic and end-diastolic volume gives only indirect information about segmentation performance of the myocardium and is restricted to two time points within the cardiac cycle. Therefore, the next step is to evaluate both networks on the UK Biobank data (data access application pending). This will help us understand whether the apprentice did indeed surpass the master in their main domain or if it just learned to outperform them in a related task.
Conclusion
It is possible to train an artificial neural network on labels generated by another network while improving generalization through data augmentation.Acknowledgements
Financial support: German Ministry of Education and Research (BMBF, grant: 01EO1504).References
- Mazurowski MA, Buda M, Saha A, Bashir MR. Deep learning in radiology: An overview of the concepts and a survey of the state of the art with focus on MRI. Journal of Magnetic Resonance Imaging. 2019;49(4):939-954
- Data Science Bowl Cardiac Challenge Data, Available: https://kaggle.com/c/second-annual-data-science-bowl/data. 2016
- Bai W, Sinclair M, Tarroni G, et al. Automated cardiovascular magnetic resonance image analysis with fully convolutional networks. J Cardio Magnetic Resonance. 2018;20(1):65
- Petersen SE, Matthews PM, Francis JM, et al. UK Biobank’s cardiovascular magnetic resonance protocol. J Cardio Magnetic Resonance. 2016;18(1):8
- Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Lecture Notes in Computer Science. 2015:234-241
- He K, Zhang X, Ren S, Sun J. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition; 2016:770-778
- Russakovsky O, Deng J, Su H, et al. ImageNet Large Scale Visual Recognition Challenge. Int J Comput Vis. 2015;115(3):211-252
- Howard J, et al. Fastai. GitHub; https://github.com/fastai/fastai. 2018
Figures
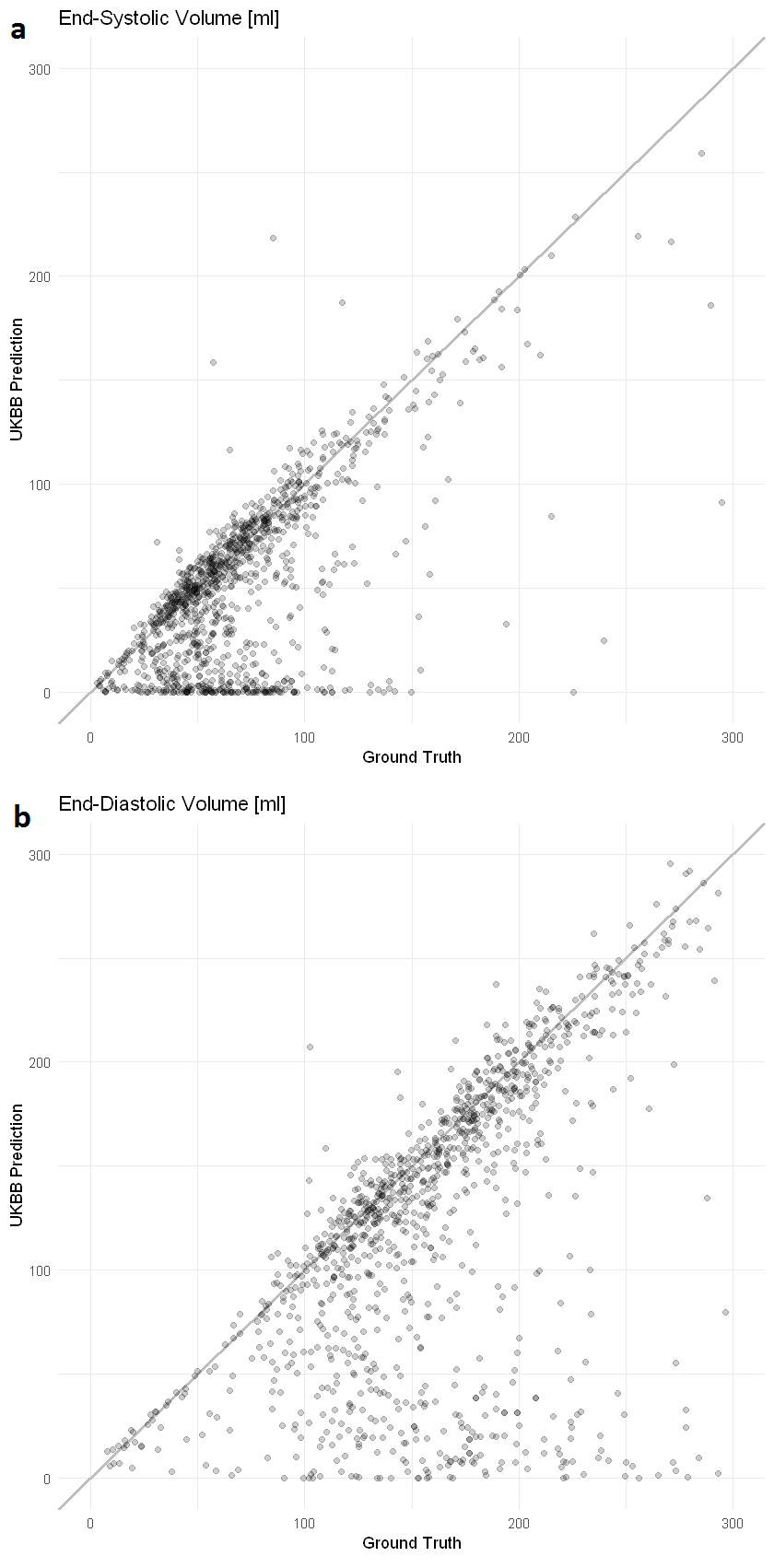
Figure 1: Comparison of prediction by the specialized
neural network to the ground truth. Each dot represents one subject. The grey
line indicates a perfect prediction (prediction=ground truth) (a) End-systolic volume in ml. (b) End-diastolic volume
in ml
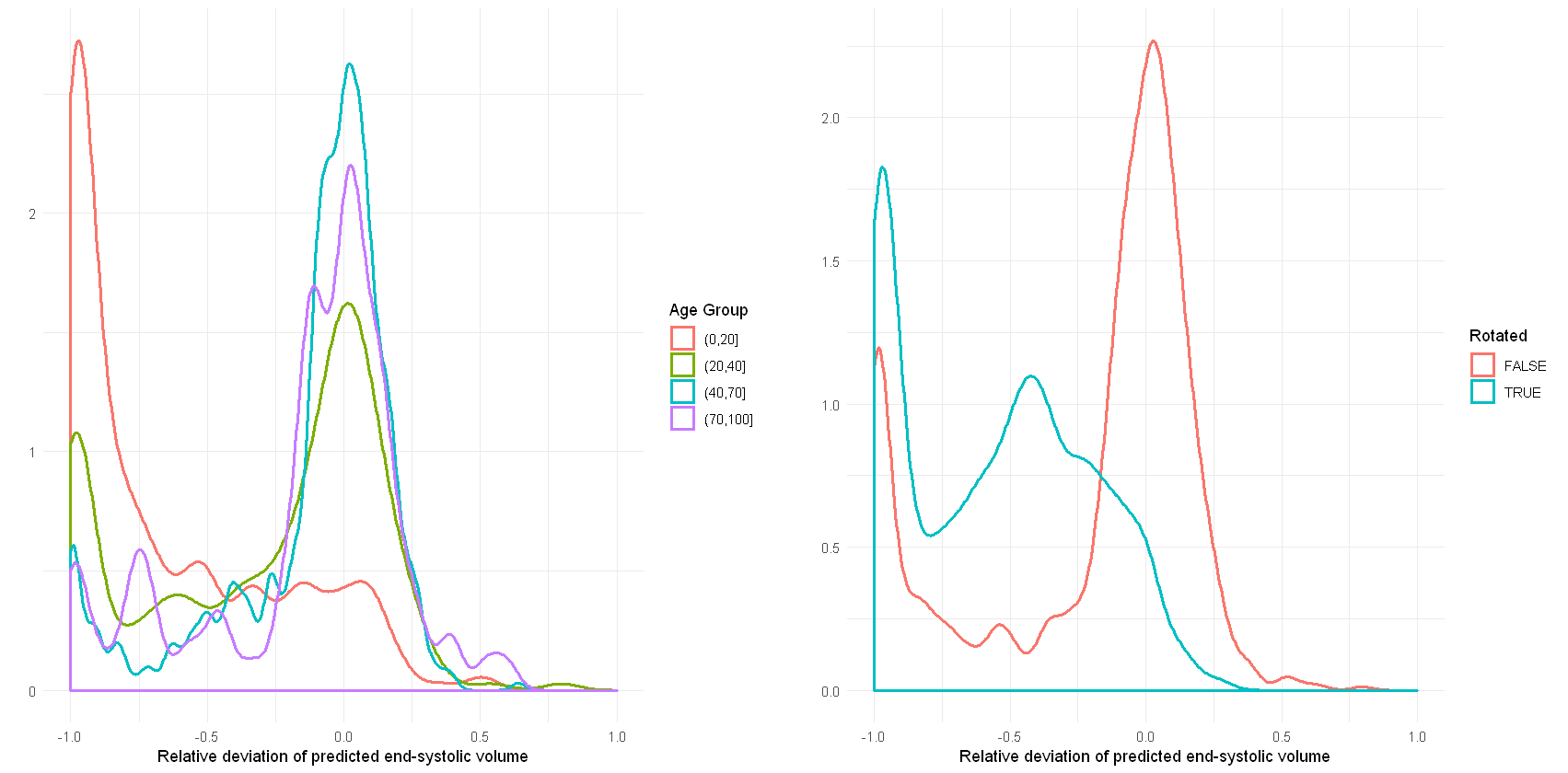
Figure 2: Density plots of the relative deviation of
the end-systolic volume predicted by the published network trained on UK
Biobank data compared to the ground truth for (a) different age groups and (b)
images rotated by 90 degrees.
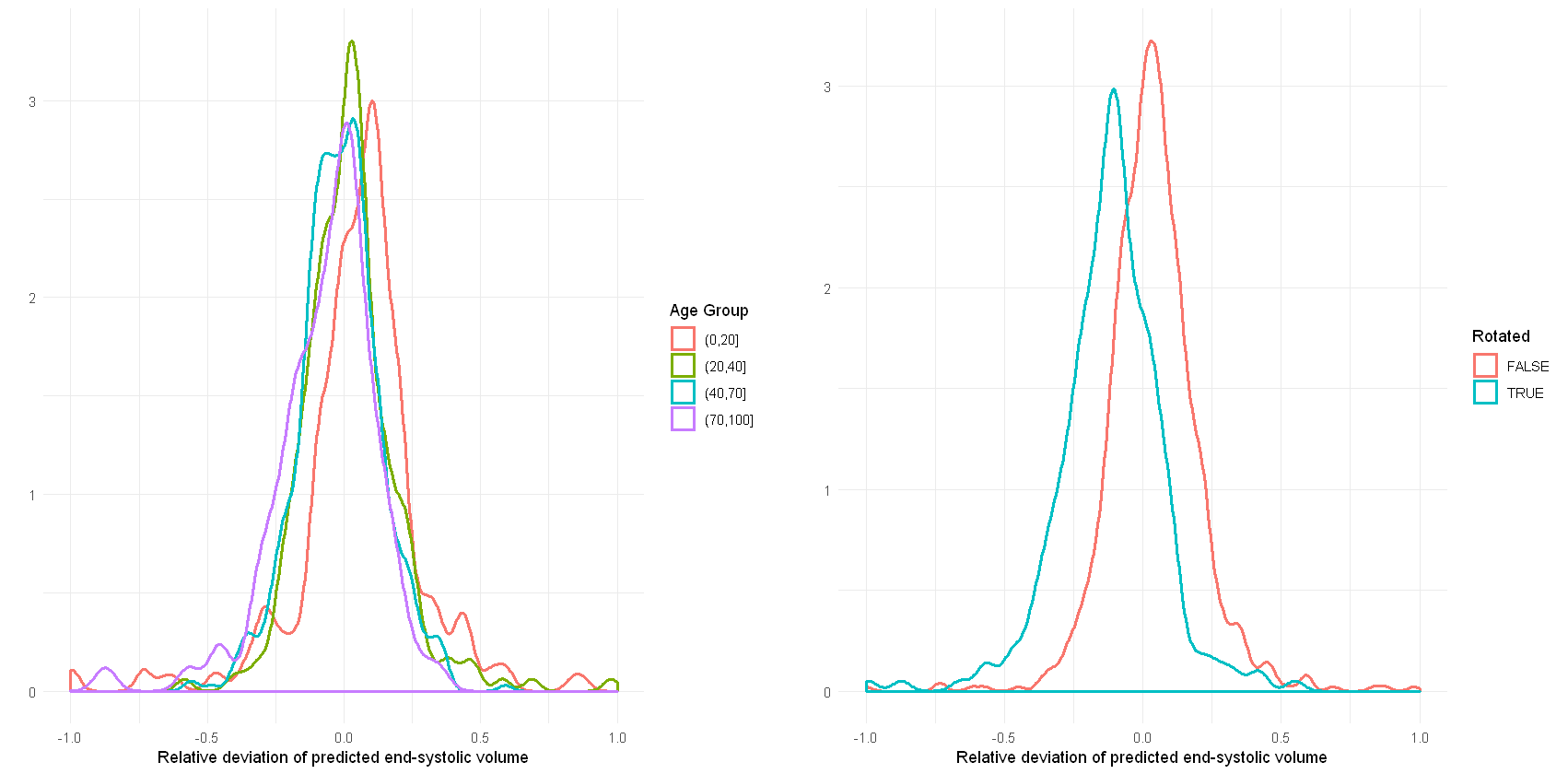
Figure 3: Density plots of
the relative deviation of the end-systolic volume predicted by our re-trained network
compared to the ground truth for (a) different age groups and (b) images
rotated by 90 degrees.
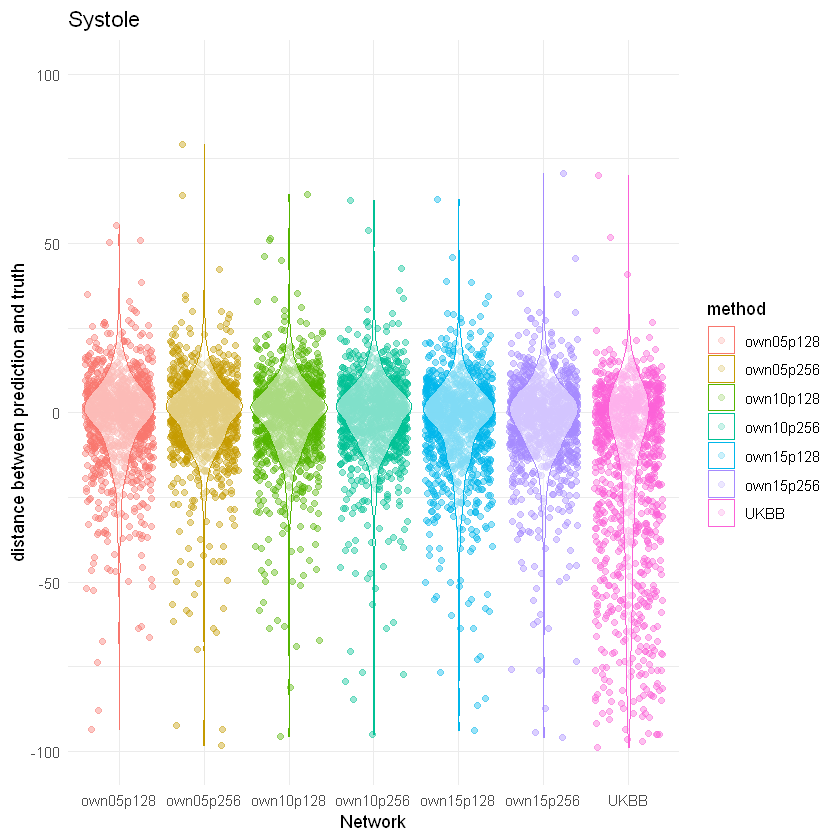
Figure 4: Prediction
performance of neural networks trained on different fidelity sets and different
image sizes compared to the published network trained on UK Biobank data.
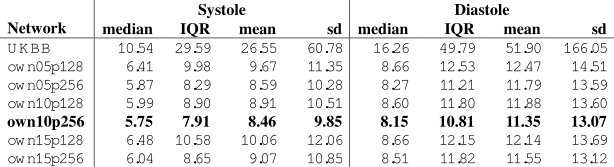
Table 1: Deviation of
end-systolic and end-diastolic volume of predictions by the different networks
compared to the ground truth in the DSBCC data set. Lowest mean and median
deviation as well as lowest inter quartile range (IQR) and standard deviation (sd)
are highlighted in bold