2014
Parameters tradeoff for small articulator features in dynamic vocal tract RT-MRI1IADI Université de Lorraine, INSERM U1254, Nancy, France, 2LORIA Université de Lorraine, CNRS, Inria, Nancy, France, 3CIC-IT 1433 INSERM, CHRU de Nancy, Nancy, France
Synopsis
Dynamic images acquired with real-time radial Flash sequence and nonlinear reconstruction pipeline are compared for two set of parameters standard protocol and an higher resolution set trading real-time reconstruction constrain for an increase in spatial resolution. The spatial resolution improvement is assessed using sharpness index and quality of automatic edge detection.
Purpose
For RT-MRI speech imager, to give insight for parameter choice when higher spatial resolution is needed without real-time reconstruction constrain.Introduction
Vocal tract is the cavity where the sound produced at the larynx is filtered. It is a part of the upper airway consisting of several soft-tissue structures and muscles that are intricately coordinated to perform functions such as speech, swallowing, and breathing. Magnetic resonance imaging (MRI) of the vocal tract offers a noninvasive way to visualize the morphological and functional aspects of this structure. It has several compelling advantages over competing modalities such as x-ray and ultrasound. Real-time MRI (RT-MRI) involves the continuous acquisition of MRI images of a dynamically evolving process. This has emerged as a powerful tool to visualize the complex spatiotemporal coordination of upper airway structures during physiological functions such as speech production. It is a powerful tool in speech research, which has the potential to address several open questions in the areas of phonetics, phonology, language acquisition, and language disorders. In several research and clinical studies, RT-MRI has presented a challenging trade-off between spatial resolution, temporal resolution, signal-to-noise ratio (SNR), and artifact suppression. Several of these factors can be traded differently based on the upper airway task of interest. For speech production, the requirements of spatial and temporal resolution in RT-MRI vary form few seconds for sustained sounds production to few milliseconds for consonant production [1]. High time resolutions of below 70ms are required to study very fast articulatory movements such as those during consonant constrictions and coarticulation events. Developments in RT-MRI radial acquisition provide a view into the oropharyngeal dynamics of speech. Advances in hardware, acquisition, and reconstruction methods have enabled spatial resolutions capable of distinguishing contact of the velum and temporal resolutions capable of seeing tongue tip movements at a temporal resolution of 20ms [2]. But the new RT-MRI speech imager is faced with many choices. In this work, for the same sequence and reconstruction pipeline we compare the standard protocol proposed in [2] with another set of parameters trading real-time reconstruction constrain for an increase in spatial resolution. The spatial resolution increase with the proposed parameters is assessed using sharpness index and edge detection quality.Materials and Methods
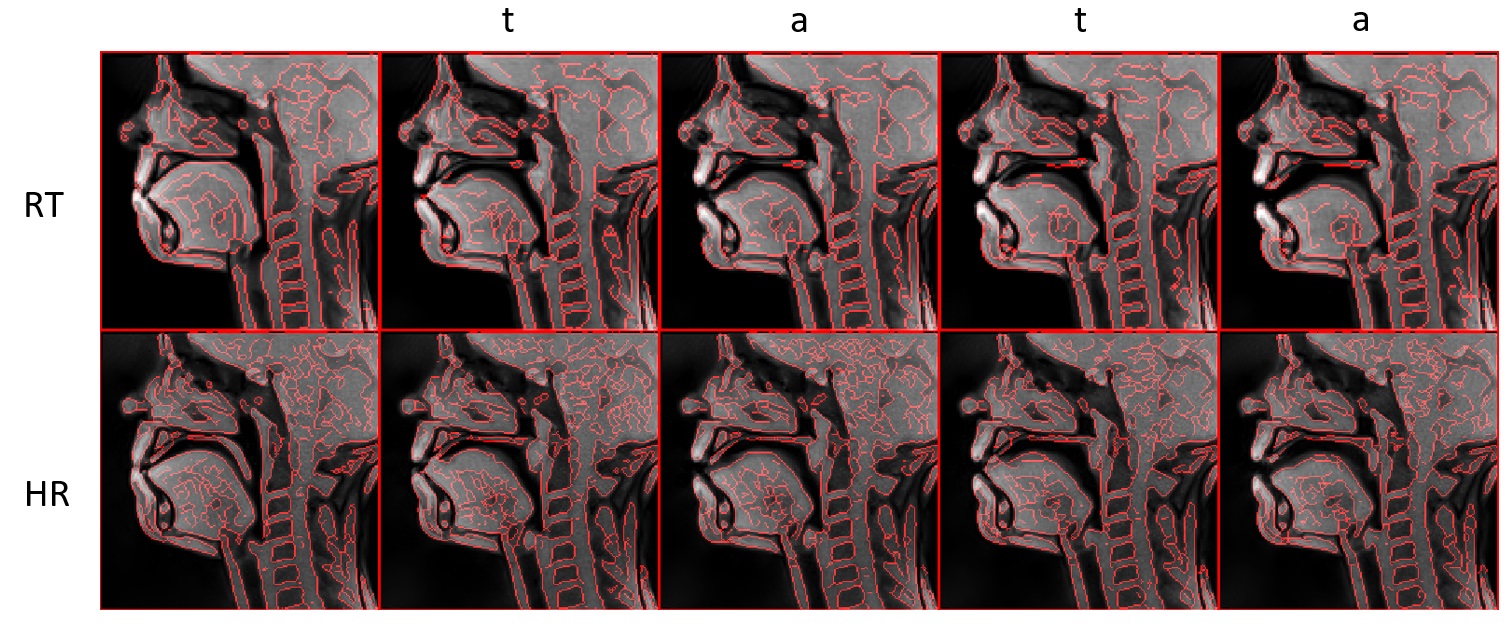
A female subject was asked to repeat /tata/ several times during MRI acquisition. The choice of this utterance is motivated by the presence of consonant-vowel-consonant transition with low variability of the tongue position for the consonant /t/ and the vowel /a/ forces the subject to open the mouth and increases magnitude of the tongue motion and speed. The data were acquired on a Siemens Prisma 3T scanner (Siemens, Erlangen, Germany) in CHRU of Nancy under the approved ethics protocol (ClinicalTrials.gov NCT02887053). The used sequence is real-time MRI Flash sequence [2]. Audio was recorded simultaneously with imaging at a sampling frequency of 16 kHz by using an optoacoustics fibre-optic microphone (FOMRI-III, Optoacoustics, Israel). To remove acoustic noise of the MRI machine, we used the denoising algorithm [3]. The slice was placed in mid-sagittal orientation. The parameters for the real-time dynamic image series (RT) were: TR 2.22ms, TE 1.47ms, radial spokes 9, slice thickness 8mm, filp angle 5°, FOV 192x192mm, matrix 136x136, pixel BW 1670 Hz, time resolution per image 19.98ms, pixel spacing 1.41x1.41mm dynamic 1000 images. The parameter for the second higher resolution dynamic image series (HR) were: TR 2.29ms, TE 1.4ms, radial spokes 9, slice thickness 5mm, filp-angle 5°, FOV 191x191mm, matrix 200x200, pixel BW 1085Hz, time resolution per image 20.61ms, pixel spacing 0.96x0.96mm dynamic 1000 images. To assess the sharpness increase of high resolution images, the sharpness index [4] has been computed for each images. The standard RT images were interpolated to a 200x200 matrix with Lanczos-3 kernel before sharpness index computation. The significance of the mean sharpness index difference for the two dynamic series is tested with two sample t-test. For the edge detection we used Canny edge detector after subtraction of the background intensity with best parameters for both sets.Results
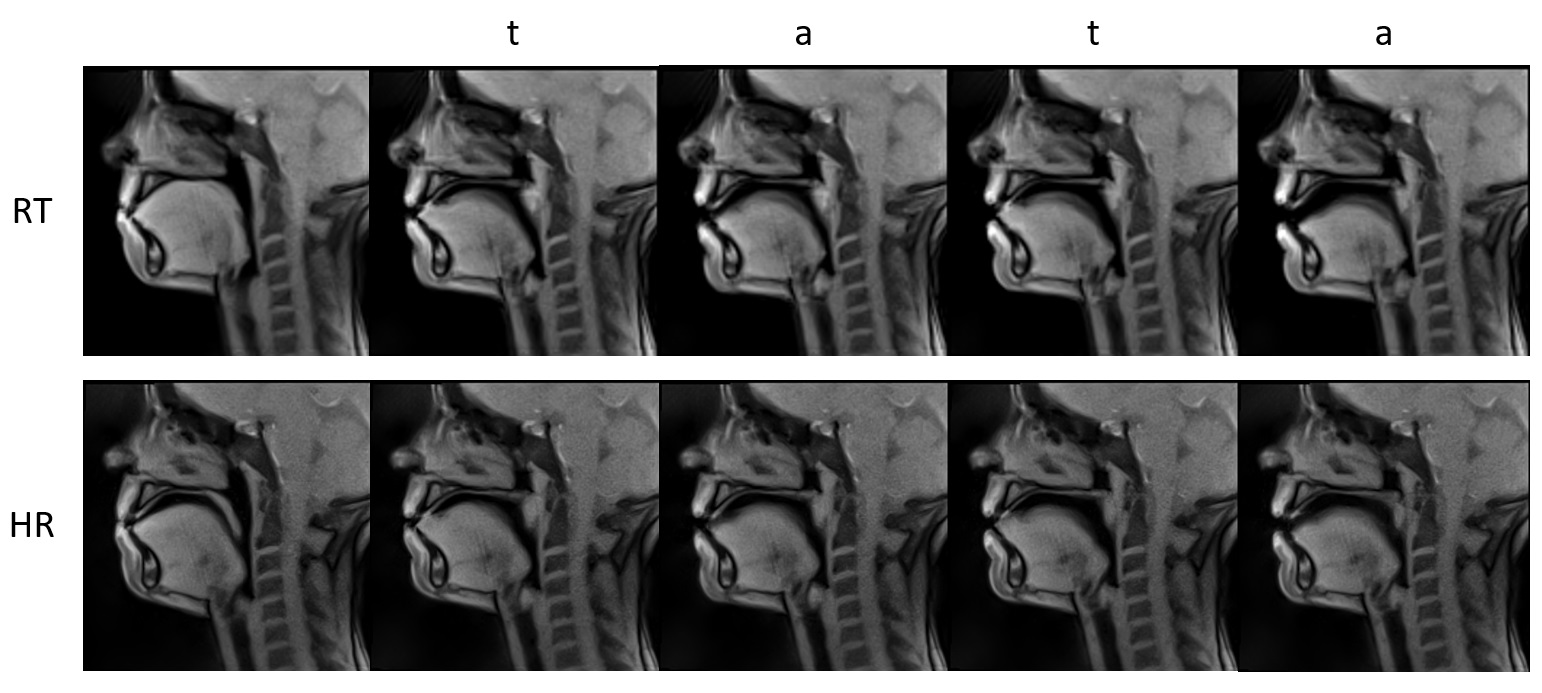
The RT and HR series have been recorded. Chosen images at rest and while pronouncing /tata/ are displayed Figure 1. Even during velopharyngeal closure the limit of the velum in contact with the pharyngeal wall is more clearly depicted in the HR images. The thin soft tissue underneath the hard plate has a tendency to disappear for example in the second /t/ in the RT images of Figure 1. The mean sharpness index for RT images is 90.2 (SD 5.1) and for HR images 100.7 (SD 6.3). The means are significantly different (p = 1.76 10^-267). Edge detection result is displayed in Figure 2.Discussion
Since the slice thickness of the HR images is smaller one can observe a slightly lower SNR around the spine than the RT images. Higher spatial resolutions are required for better definition of the border of the tongue and other articulator like epiglottis, which is important for automated image segmentation and delineation tasks for subsequent quantitative analysis. The reconstruction pipeline still uses 5-image median temporal filter to remove some radial artifacts, some post processing filter with better temporal fidelity could be used to further improve the image quality.Acknowledgements
Research supported by the project ArtSpeech of ANR (Agence Nationale de la Recherche), France, CPER ”IM2MP”, ”LCHN” and FEDER.References
1. Lingala SG, Sutton BP, Miquel ME and Nayak KS. J Magn Reson Imaging. 2016 Jan;43(1):28-44. doi: 10.1002/jmri.24997.
2. Uecker M, Zhang S, Voit D, Karaus A, Merboldt KD, Frahm J. NMR Biomed. 2010 Oct;23(8):986-94. doi: 10.1002/nbm.1585.
3. Ozerov A, Vincent E and Bimbot F. IEEE Transactions on Audio, Speech, and Language Processing, 2012 May; 20(4):1118-1133. doi: 10.1109/TASL.2011.2172425
4. Leclaire A, and Moisan L. J Math Imaging Vis (2015) 52: 145. https://doi.org/10.1007/s10851-015-0560-5 and http://helios.mi.parisdescartes.fr/~moisan/sharpness/
Figures