1865
Transfer learning with progressive training as a novel approach for classifying clinical forms of multiple sclerosis based on clinical MRI1University of British Columbia, Vancouver, BC, Canada, 2University of Calgary, Calgary, AB, Canada
Synopsis
Transfer learning and greedy layer-wise training are two potential approaches to advance the performance of deep learning, particularly in fields with limited sample size including medical imaging. Taking the advantage of both, we have implemented a novel strategy that allows progressive training with transfer learning using the VGG19 network. Based on clinical MRI of 19 patients only, our approach achieved 88% accuracy in classifying relapsing remitting from secondary progressive multiple sclerosis (MS), 6% greater than training with the traditional approach. This innovative method may help provide new insight into the pathogenesis and progression mechanisms in MS.
Introduction
Secondary progressive multiple sclerosis (SPMS) is a natural conversion from the relapsing remitting clinical form (RRMS) of MS. However, it is difficult to detect the structural changes in vivo associated with the conversion1. Deep learning has shown tremendous potential in image classification in various applications2. In particular, to overcome the limitations of small sample size that is common in medical imaging, two approaches have been proposed in the past. One is named transfer learning3, which uses deep learning models trained to perform a more general task using a large dataset, so the model needs only to be fine-tuned for the target dataset. The other is called greedy layer-wise training4, which adds layers to deep learning models one-by-one, train the parameters of the specified layer, and then freeze it. This will reduce the number of parameters being trained and improve model performance. In this study, we introduce “progressive training” which applies the principal of greedy layer-wise training to models initialized using transfer learning. Our goal was to evaluate how this novel approach compares with traditional training in the classification of standard clinical MRI scans from patients with RRMS and SPMS.Methods
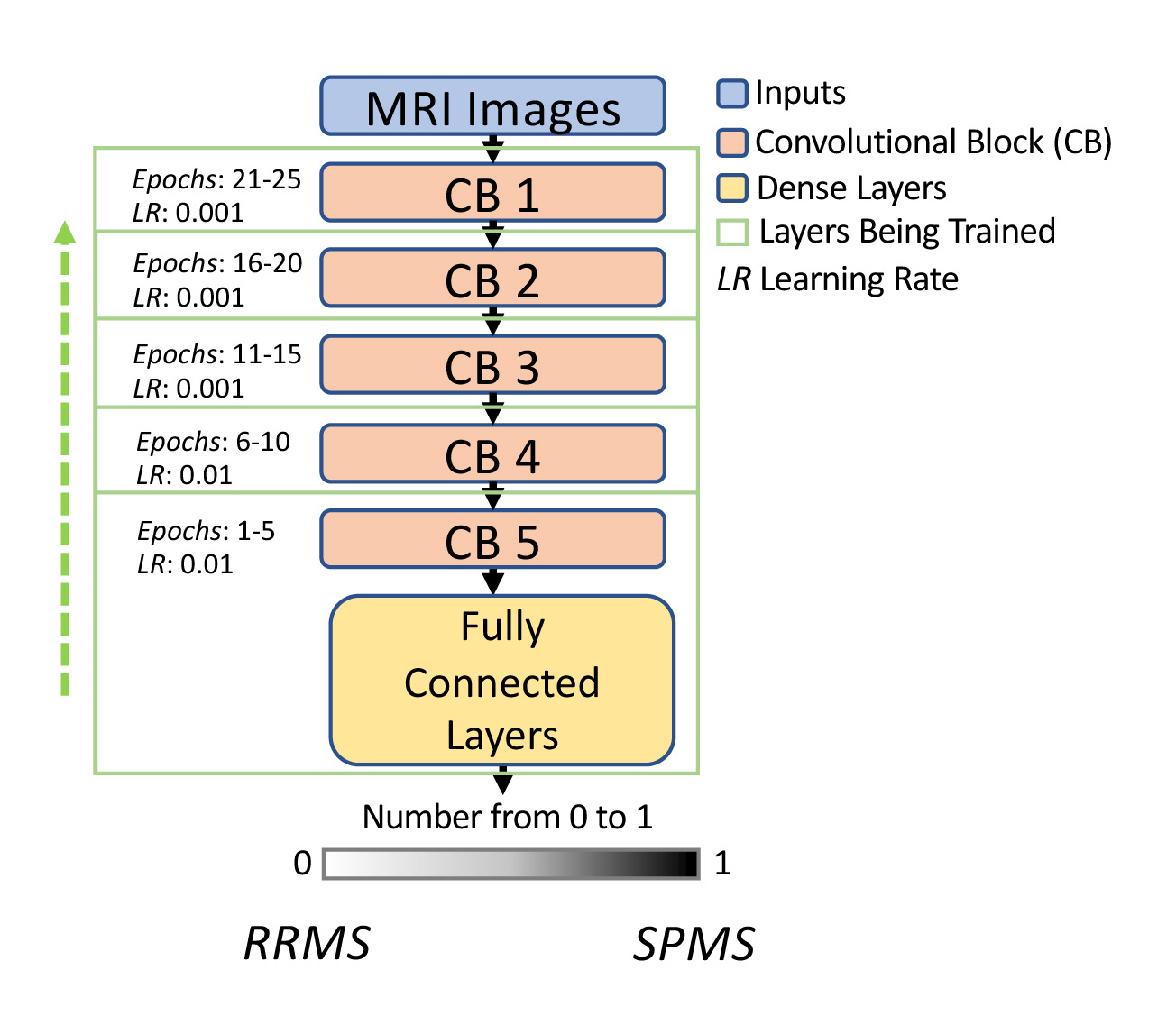
Model setting: Our transfer learning used a well-recognized deep convolutional neural network (CNN) named VGG195, which was initialized with ImageNet weights6. The VGG19 contained 5 convolutional blocks. Our training started with the last block prior to the output layer, and the rest were kept frozen. After every five epochs, an earlier convolutional block was unfrozen and the training continued. This was repeated until every convolutional block was retrained (Fig. 1). The learning rate for the last 2 blocks was 0.01, and reduced to 0.001 at shallow blocks, as the last block contained the most high-level features but was the least optimized from the transfer learning process. For the traditional approach, we froze the first 3 convolutional blocks and trained the rest all at once as done in many deep learning applications.Dataset: Clinical brain MRI scans including T1, T2, and FLAIR images are studied from 19 patients (10 RRMS; 9 SPMS). The images were first preprocessed to enhance quality that included: skull stripping, normalization, histogram equalization, and intra-subject image registration using T1 MRI as a reference. This was followed by data augmentation to increase sample size withthe following steps: horizontal flip, rotation, and scaling (Fig. 2). After co-registration, image slices that did not contain significant brain areas were removed, leading to 135 slices per MRI sequence. The total dataset was divided into 3 portions: 75% for training, 10% for validation, and 15% for testing.
Model testing and evaluation: Model input was at slice basis, 3 images per slice from the corresponding MRI sequences. Following image classification, we used a majority vote rule to determine patient type, which was decided by the type of most of the MRI slices of the patient. Based on this outcome, wecalculated model accuracy by patient, and identified the most critical image slices contributing to the classification. All experiments were repeated 5 times.
Results
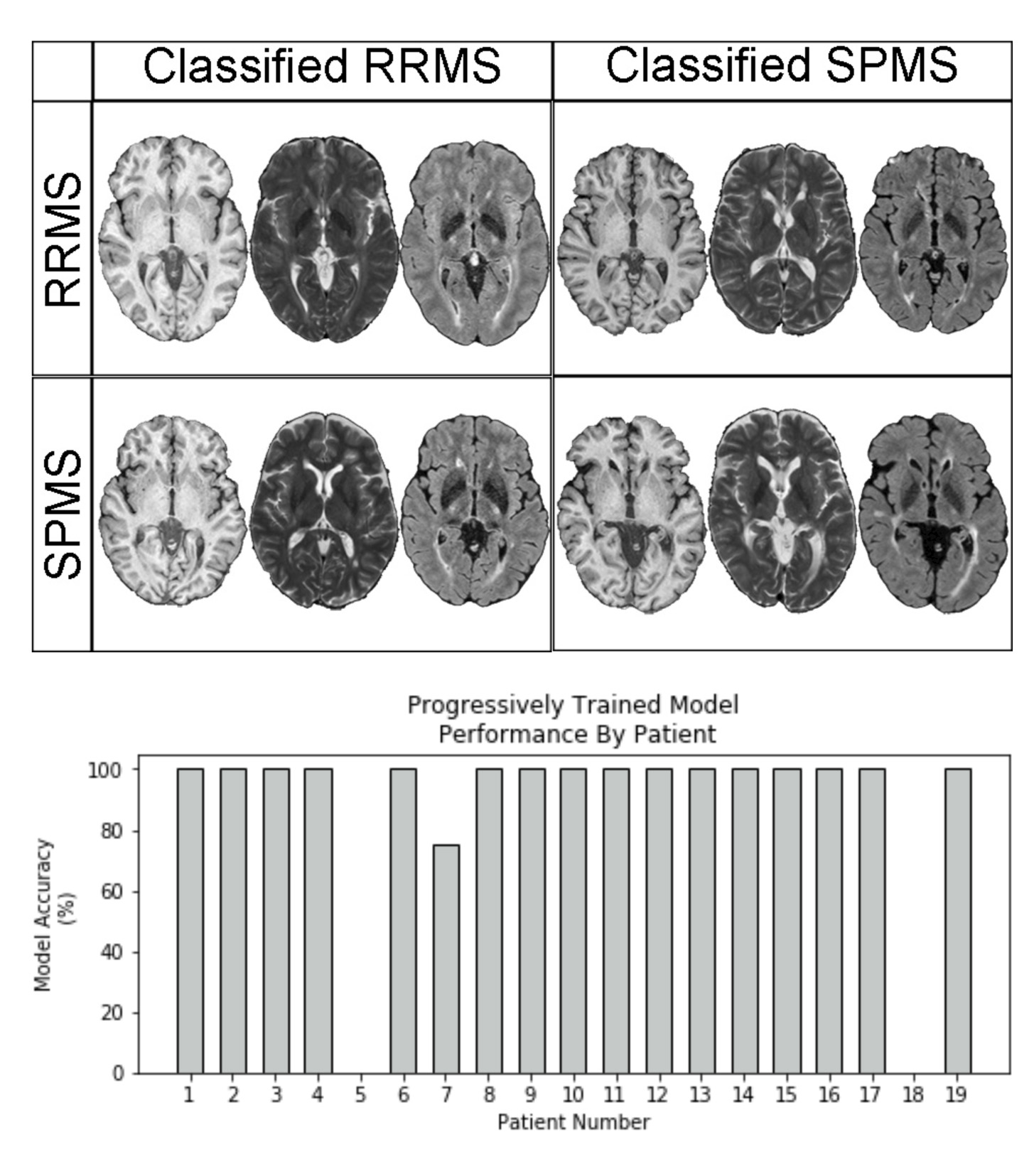
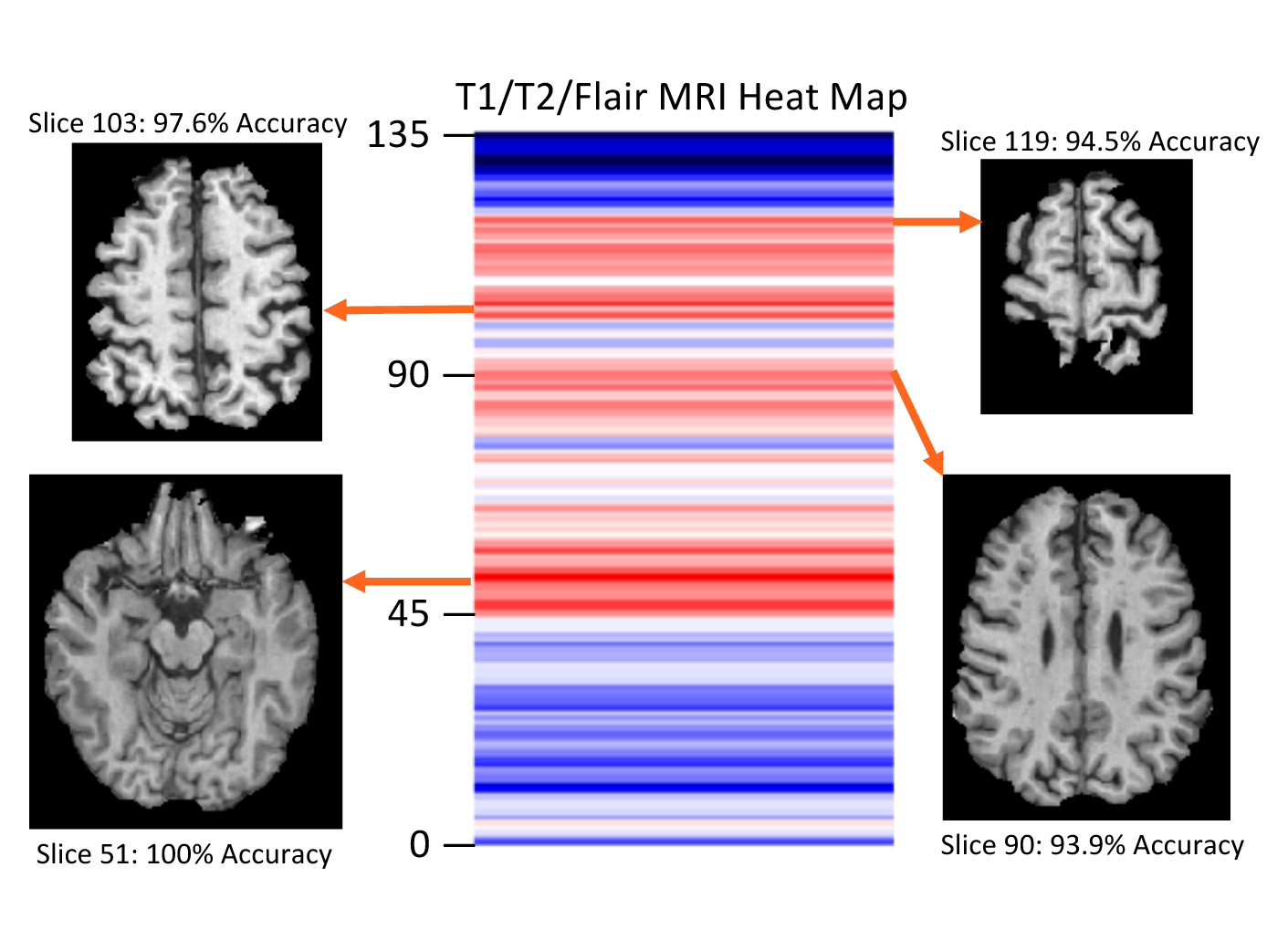
All VGG 19 models tested achieved greater than 80% classification accuracy. The model trained with progressive strategy had the best classification accuracy, which was 88.2%. Using traditional training, the accuracy was 82 %. In particular, 16/19 patients were classified with a 100% success rate across 5 independent trials (Fig. 3). The training time was approximately 30 minutes using GPU accelerated learning with progressive training, versus ~10 minutes with traditional training. The MRI slices located at brain stem and cerebellum areas achieved the highest accuracy in both approaches (Fig. 4).Discussion
The conversion from RRMS to SPMS is insidious and can only be identified in retrospect clinically. The availability of a reliable imaging method would be critical for precise understanding of the pathological changes, which may facilitate early intervention or prevention. This study evaluated the possibility of combining the benefits of both transfer learning and greedy layer-wise training. Progressive training is a novel approach for improving model performance. However, models based on greedy layer-wise training lack the flexibility of generalization7. Training only layers at the last block at the start helped reduce the number of model parameters and likely increased model accuracy. Likewise, adjusting the learning rate based on the depth of convolutional blocks in progressive training may be more effective than traditional training. Applying a higher learning rate is appropriate at the start of training to the deeper convolutional blocks that require larger parameter changes as those blocks are most specific to a target application. Decreasing learning rate is necessary at the earlier blocks as they contain more general features (e.g. edge detection), which are not expected to vary significantly between datasets, and so require only fine-tuning. The significance of MRI slices indicates the brain areas associate highly with the symptoms of MS such as motor dysfunction, deserving further confirmation.Conclusion
Combining transfer learning with progressive training may be a promising approach for classifying disease properties thereby identifying disease progression mechanisms in MS.Acknowledgements
We thank the patient and control volunteers for participating in this study and the funding agencies for supporting the research including the Natural Sciences and Engineering Council of Canada (NSERC), Multiple Sclerosis Society of Canada, Alberta Innovates, Campus Alberta Neuroscience-MS Collaborations, and the HBI Brain and Mental Health MS Team, University of Calgary, Canada.References
1. Lorscheider J, Buzzard K, Jokubaitis V, et al. Defining secondary progressive multiple sclerosis. Brain2016; 139: 2395-2405. 2016/07/13. DOI: 10.1093/brain/aww173.
2. LeCun Y, Bengio Y and Hinton G. Deep learning. Nature2015; 521: 436-444. 2015/05/29.
3. Shin Hc Fau - Roth HR, Roth Hr Fau - Gao M, Gao M, Fau - Lu L, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. Ieee Trans Med Imaging2016.
4. Hinton, G. E., Osindero, S., & Teh, Y. A fast learning algorithm for deep belief nets. Neural Computation, 2006; 18, 1527–1554.
5. Simonyan, K., et al.: Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556v6 (2015)
6. He K, Zhang X, Ren S, et al. Delving deep into rectifiers: surpassing human-level performance on imageNet classification. arXiv: 1502018522015.
7. Singh B, De S, Zhang Y, Goldstein T, & Taylor G. Layer-Specific Adaptive Learning Rates for Deep Networks. arXiv: 1510.04609v1 2015.
Figures