1472
Relevance-guided Deep Learning for Feature Identification in R2* Maps in Alzheimer’s Disease Classification1Medical University of Graz, Graz, Austria
Synopsis
Using R2* maps we separated Alzheimer's patients (n=119) from healthy controls (n=131) by using a deep neural network and found that the preprocessing steps might introduce unwanted features to be used by the classifier. We systematically investigated the influence of registration and brain extraction on the learned features using a relevance map generator attached to the classification network. The results were compared to our relevance-guided training method. While the resulting classification accuracy on the testset was similar for all training configurations, the relevance-guided method identified anatomical regions, which are known to have higher R2* values.
Introduction
Deep learning techniques are increasingly utilized in medical applications, including image reconstruction, segmentation, and classification.1,2 However, despite the good performance those models are not easily interpretable by humans.3 Especially medical applications require to verify that the high accuracy of those models is not the result of exploiting artifacts in the data. Our experiments on Alzheimer's disease (AD) classification showed that Deep Neural Networks (DNN) might learn from features introduced by the skull stripping algorithm. In this work we have investigated how preprocessing steps including registration and brain extraction determine which features in the R2* maps are relevant for the separation of patients with AD from healthy controls (HC).Methodology
Dataset. We retrospectively selected 252 MRI datasets from 119 patients with probable AD (mean age=72.4±9.0 years) from our outpatient clinic and 133 MRIs from 131 age-matched healthy controls (mean age=70.3±9.1 years) from an ongoing community dwelling study. Patients and controls were scanned using a consistent MRI protocol at 3 Tesla (Siemens TimTrio) including a T1-weighted MPRAGE sequence (1mm isotropic resolution) and a spoiled FLASH sequence (0.9x0.9x2mm³, TR/TE=35/4.92ms, 6 echoes, 4.92ms echo spacing, 64 slices). The AD data was split up into 178 training, 37 validation and 37 test scans and the HC data was split up into 95 training, 19 validation and 19 test scans.Preprocessing. Brain masks from each subject were obtained using SIENAX from FSL. R2* maps were voxelwise calculated using a monoexponential model and affinely registered to the MPRAGE sequence using FSL flirt. The R2* maps have been registered to the MNI152 template nonlinearly using FSL fnirt. To speed up the training process all data was downsampled to 2mm isotropic resolution.4
Standard classification network. We utilize a classification network, which uses the combination of a single convolutional layer followed by a down-convolutional layer as the main building block. The overall network stacks three of those main building blocks before passing the data through two fully connected layers. Each layer is followed by a Rectified Linear Unit (ReLU) nonlinearity, except for the output layer where a Softmax activation is applied.
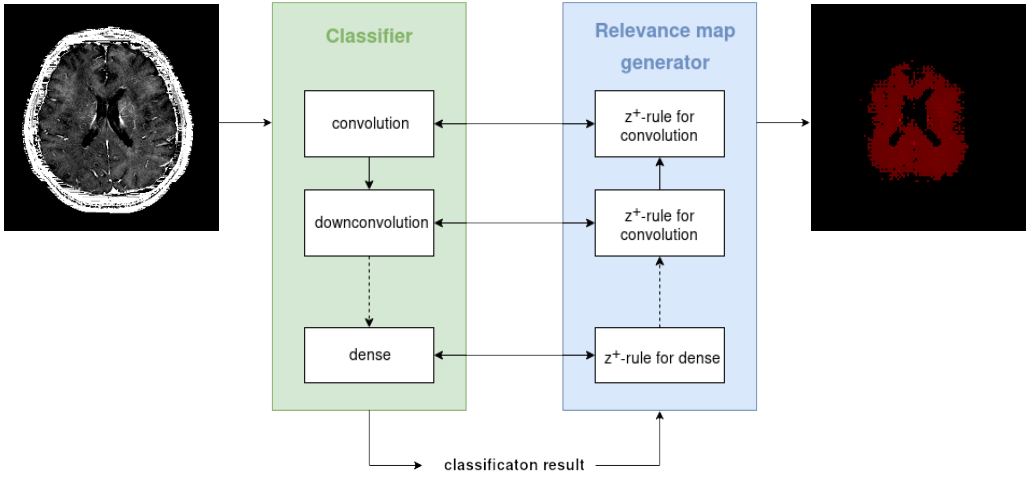
Relevance-guided classification network. To focus the network on relevant features, we proposed a relevance-guided network architecture, that extends the given classification network with a relevance map generator (cf. Figure 1 for details). To this end we implemented the deep Taylor decomposition (z+-rule) to generate the relevance maps of each input image depending on the classifier's current parameters.5
Training. We trained models for three differently preprocessed types of R2*:
- input images in native subject R2* space
- input images linearly registered to individual subject’s T1 space
- input images nonlinearly registered to MNI152 space
Results
The resulting classification accuracy between control subjects and AD shows similar performance on the testset for the compared models:- relevance-guided/skull stripped on R2* maps: 82%/80%
- relevance-guided/skull stripped on affinely registered R2* maps: 86%/82%
- relevance-guided/skull stripped on nonlinearly registered R2* maps: 82%/82%
Discussion and Conclusion
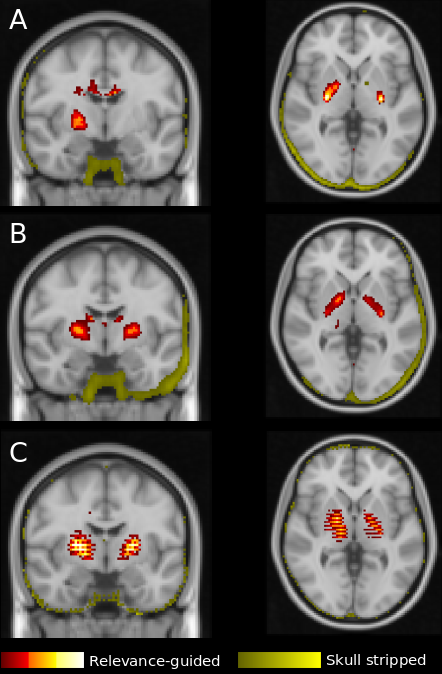
The results of this explorative study demonstrates that the preprocessing of MR images is crucial for the feature identification by DNNs. Previous work has shown that skull stripping is necessary to avoid identification of features outside the brain. However, this may introduce new features at the edge of the brain mask, which are subsequently used by the DNN for classification. The source of the newly introduced features remains unclear, however it was demonstrated that brain extraction algorithms can be biased by the patient cohort.7In contrast, when using the proposed relevance-guided approach and independently of preprocessing, the regions of highest relevance were found in the basal ganglia and the dentate nucleus. R2* is considered as a measure of iron content and histological and in-vivo studies have shown that brain iron strongly accumulates in these regions, in particular in AD patients when compared to healthy controls.8
In conclusion, our results are in good agreement with findings from iron mapping studies and strongly support the hypothesis that the relevance-guided approach is minimizing the impact of preprocessing steps such as skull stripping and registration. Additionally, relevance-guiding forces the feature identification to focus on the parenchyma only and therefore provides more plausible results.
Acknowledgements
This research was supported by NVIDIA GPU hardware grants.References
1. Zhou T, Thung K-H, Zhu X, Shen D. Effective feature learning and fusion of multimodality data using stage-wise deep neural network for dementia diagnosis. Hum Brain Mapp. 2018.
2. Liu S, Liu S, Cai W, Pujol S, Kikinis R, Feng D. Early diagnosis of Alzheimer’s disease with deep learning. 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI). IEEE. 2014; 1015–1018.
3. Samek W, Binder A, Montavon G, Lapuschkin S, Muller K-R. Evaluating the Visualization of What a Deep Neural Network Has Learned. IEEE Trans Neural Netw Learning Syst. 2017;28: 2660–2673.
4. Smith SM, Zhang Y, Jenkinson M, Chen J, Matthews PM, Federico A, et al. Accurate, Robust, and Automated Longitudinal and Cross Sectional Brain Change Analysis. Neuroimage. 2002;17: 479–489.
5. Montavon G, Lapuschkin S, Binder A, Samek W, Müller K-R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognit. 2017;65: 211–222.
6. Kingma DP, Ba J. Adam: A Method for Stochastic Optimization. CoRR,vol. abs/1412.6980, 2014.
7. Fennema-Notestine C, Ozyurt IB, et al. Quantitative Evaluation of Automated Skull-Stripping Methods Applied to Contemporary and Legacy Images: Effects of Diagnosis, Bias Correction, and Slice Location. Human Brain Mapp. 2006;27: 99-113.
8. Ropele S, Langkammer C. Iron Quantification with Susceptibility. NMR in Biomedicine. 2016.
Figures