1297
A practical application of generative models for MR image synthesis: from post- to pre-contrast imaging1Advanced Clinical Imaging Technology, Siemens Healthcare AG, Lausanne, Switzerland, 2Department of Radiology, Lausanne University Hospital and University of Lausanne, Lausanne, Switzerland, 3LTS5, École Polytechnique Fédérale de Lausanne (EPFL), Lausanne, Switzerland
Synopsis
Multiple sclerosis studies following the widely accepted MAGNIMS protocol guidelines might lack non-contrast-enhanced T1-weighted acquisitions as they are only considered optional. Most existing automated tools to perform morphological brain analyses are, however, tuned to non-contrast T1-weighted images. This work investigates the use of deep learning architectures for the generation of pre-Gadolinium from post-Gadolinium image volumes. Two generative models were tested for this purpose. Both were found to yield similar contrast information as the original non-contrast T1-weighted images. Quantitative comparison using an automated brain segmentation on original and synthesized non-contrast T1-weighted images showed good correlation (r=0.99) and low bias (<0.7 ml).
Introduction
Several international consortiums provide guidelines for MRI acquisition protocols that support the analysis of specific body parts and/or diseases1,2. For instance, the European research network for MR imaging in multiple sclerosis (MAGNIMS) recommends the acquisition of T2 FLAIR and gadolinium (Gd)–enhanced T1-weighted (T1w) images for the clinical diagnosis at baseline, while contrasts as pre-Gd T1w images are only presented as optional1. Even though the former acquisitions are the most relevant for clinical diagnosis, pre-Gd T1w images provide added value for the quantitative assessment of additional neuroimaging biomarkers (e.g. morphometry, automated localization and counting of brain lesions, among others)3,4. Considering that the majority of the tools performing analysis of structural brain MRI have been optimized for non-contrast-enhanced T1w images5–7, this study investigates the application of deep learning generative models8–10 for the synthesis of pre-Gd T1w images from post-Gd data. For the task at hand, two distinct architectures were compared by assessing the differences in the estimation of brain volumes segmented on the original and synthetized pre-Gd T1w images from post-Gd images.Material and Methods
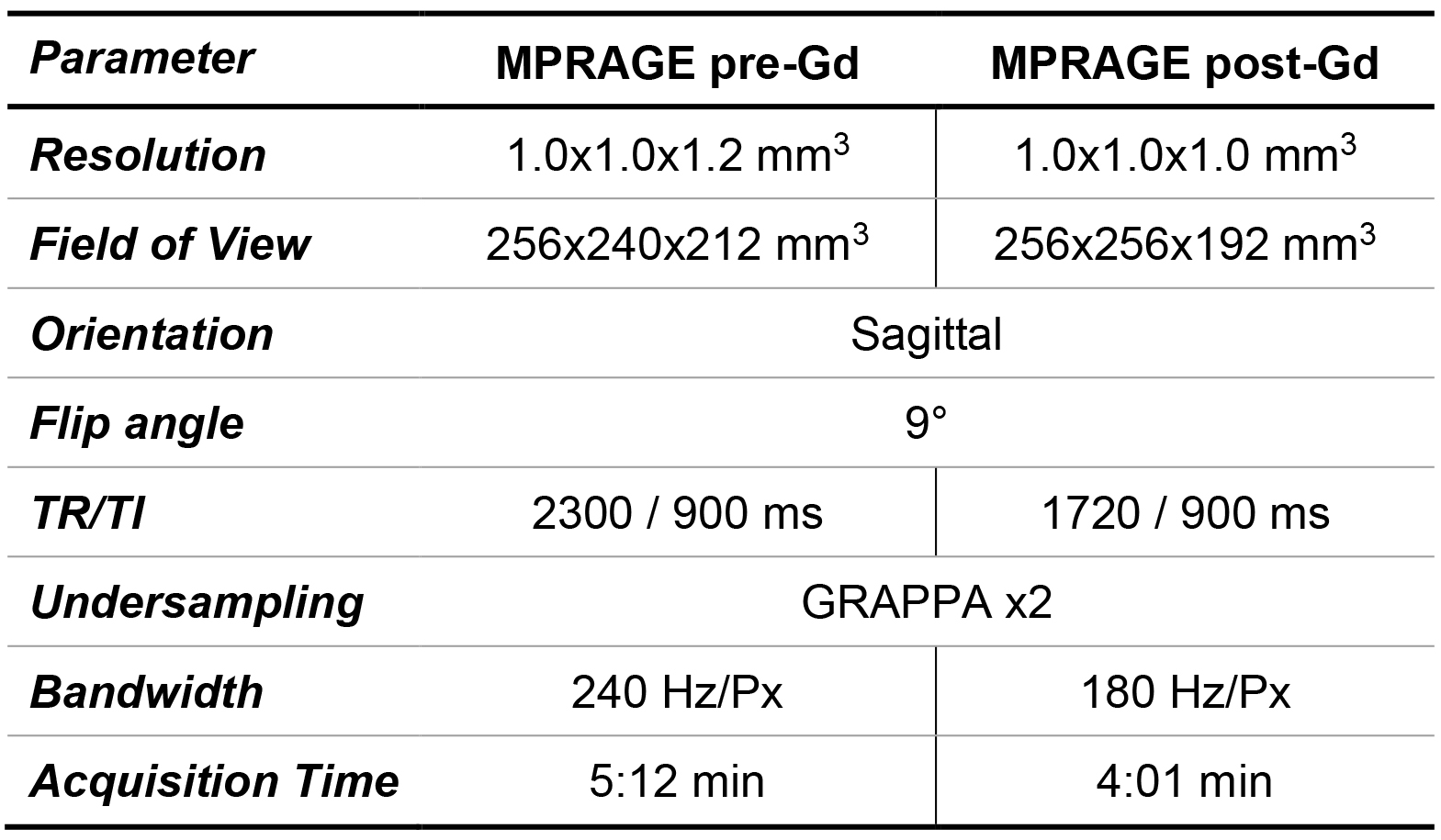
Study population and MR acquisition: Whole-brain T1w images pre- and post-Gd enhancement were collected from 42 patients (34 female, median age = 40 years, range = [23, 66] years) with multiple sclerosis scanned at 3T (MAGNETOM Prisma (48%) and MAGNETOM Skyra (52%), both Siemens Healthcare, Erlangen, Germany). T1w images were obtained with the MP-RAGE sequence11 (sequence parameters in Table 1).Image synthesis: Two deep learning networks were investigated in the synthesis of pre-Gd T1w volumes from post-Gd images: a conditional generative adversarial network (cGAN)8 and a cycleGAN9. In the cGAN, a single generator (Gy) is trained to map the transformation between the input (x) and target (y) image while a discriminator (Dy) network tries to discern real from synthetized images. Conversely, the cycleGAN architecture involves a pair of generators (Gx, Gy) that are simultaneously trained to obtain images similar to the original y and x that can fool a corresponding pair of discriminators (Dy, Dx).
Training of the cGAN was performed including a voxel-wise loss between the target and the synthetic image in the adversarial loss function:$$J_{cGAN}(G_y,D_y)=\mathrm{arg}\min_{G_y}\max_{D_y}\mathbb{E}_{x,y}\{log[D_y(x,y)]\}+\mathbb{E}_{x}\{log[1-D_y(x,G_y(x))]\}+λ\mathbb{E}_{x,y}\{|y-G_y(x)|\}$$with $$$\mathrm{\lambda}$$$ being the weighting term of the voxel-wise loss. Two cycle-consistency terms were instead incorporated in the adversarial loss of the cycleGAN:$$J_{cycleGAN}(G_x,D_x,G_y,D_y)=\mathrm{arg}\min_{G_x}\max_{D_x}\min_{G_y} \max_{D_y}\mathbb{E}_{x,y}\{log[D_y(x,y)]\}+\mathbb{E}_x\{log[1-D_y(x,G_y(x))]\}+\\\mathbb{E}_{x,y}\{log[D_x(x,y)]\}+\mathbb{E}_y\{log[1-D_x(y,G_x(y))]\}+λ_x\mathbb{E}_x\{|x-G_x[G_y(x)]|\}+λ_y\mathbb{E}_y\{|y-G_y[G_x(y)]|\}$$with $$$\lambda_x$$$ and $$$\lambda_y$$$ being the weighting terms of the cycle-consistency losses. The architecture for the generator and discriminator networks were chosen as in the work by Isola et al.8, with the generator following the shape of a U-Net with skip connections12. Networks were trained over 100 epochs (Adam optimizer, learning rate of 0.0002, $$$\beta_1$$$=0.5, $$$\beta_2$$$=0.999) using sagittal slices from 32 randomly selected patients after performing an affine registration of pre-Gd images onto post-Gd images13.
Validation: After training, synthetic pre-Gd T1w volumes were computed in the remaining ten test patients. An in-house prototype software7 was employed to automatically segment brain regions from the original pre-Gd T1w and the synthetic images. Significant differences between regional volumes were investigated with paired Wilcoxon tests, and overall agreement with correlation and Bland-Altman analysis.
Results
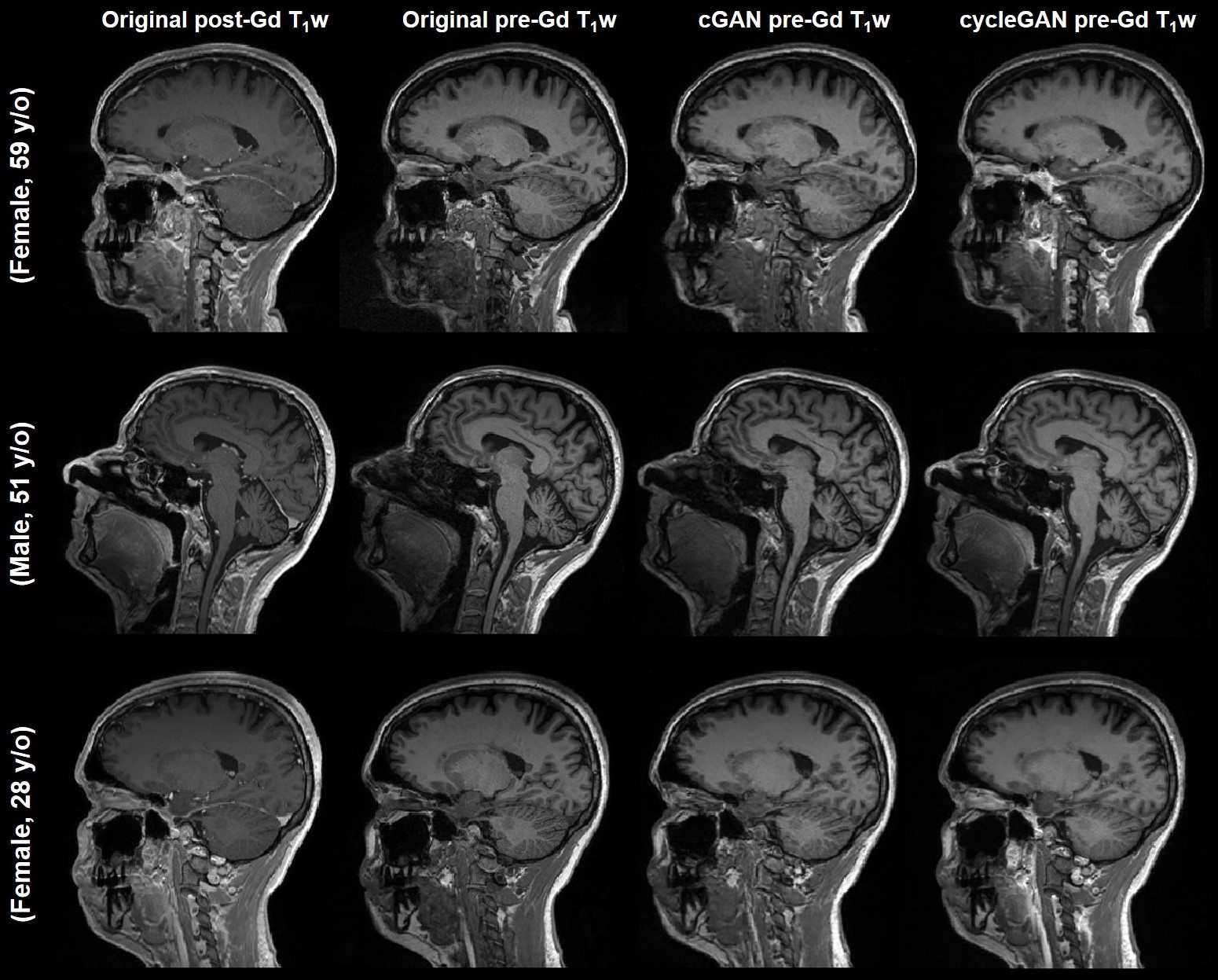
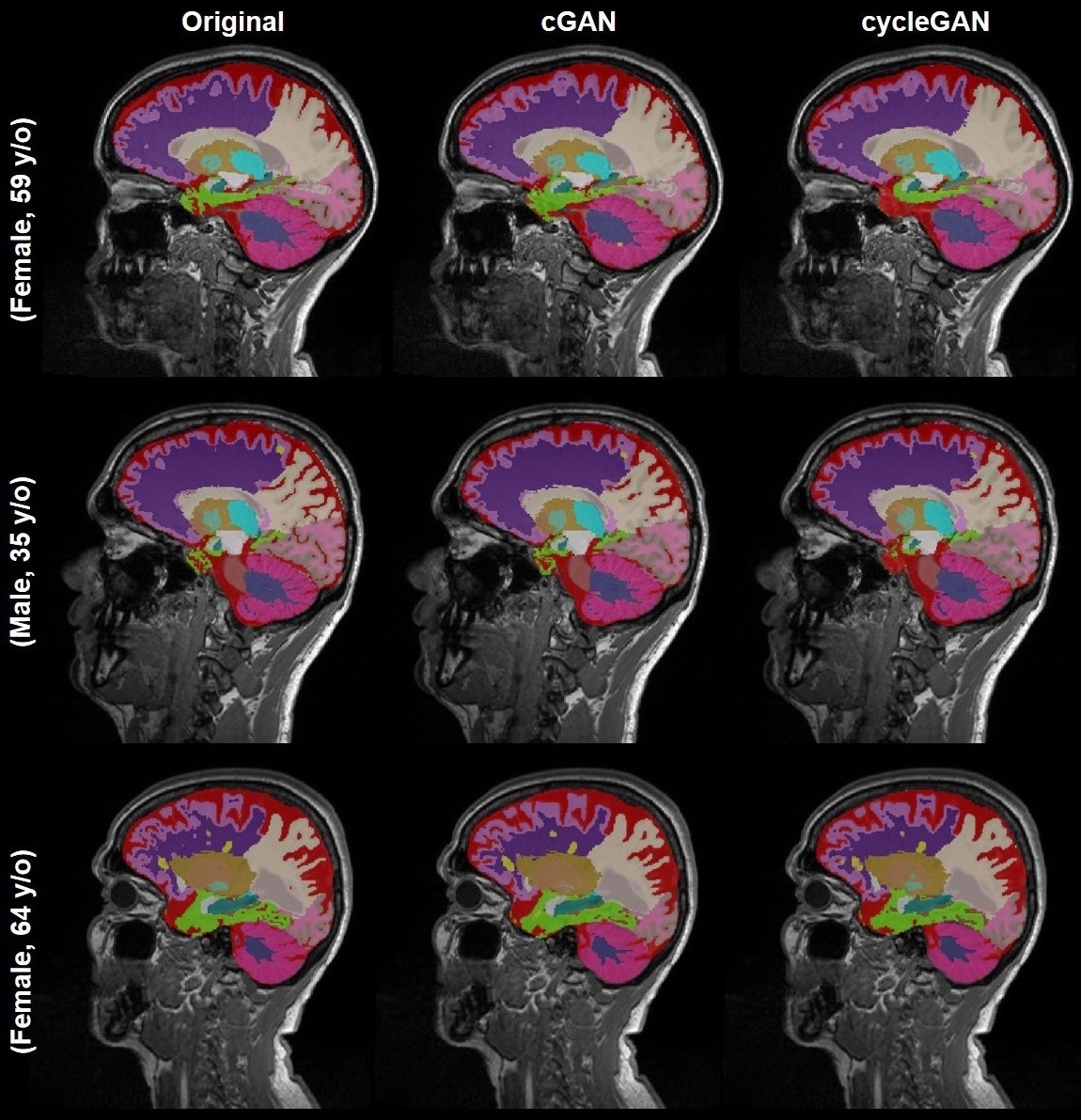
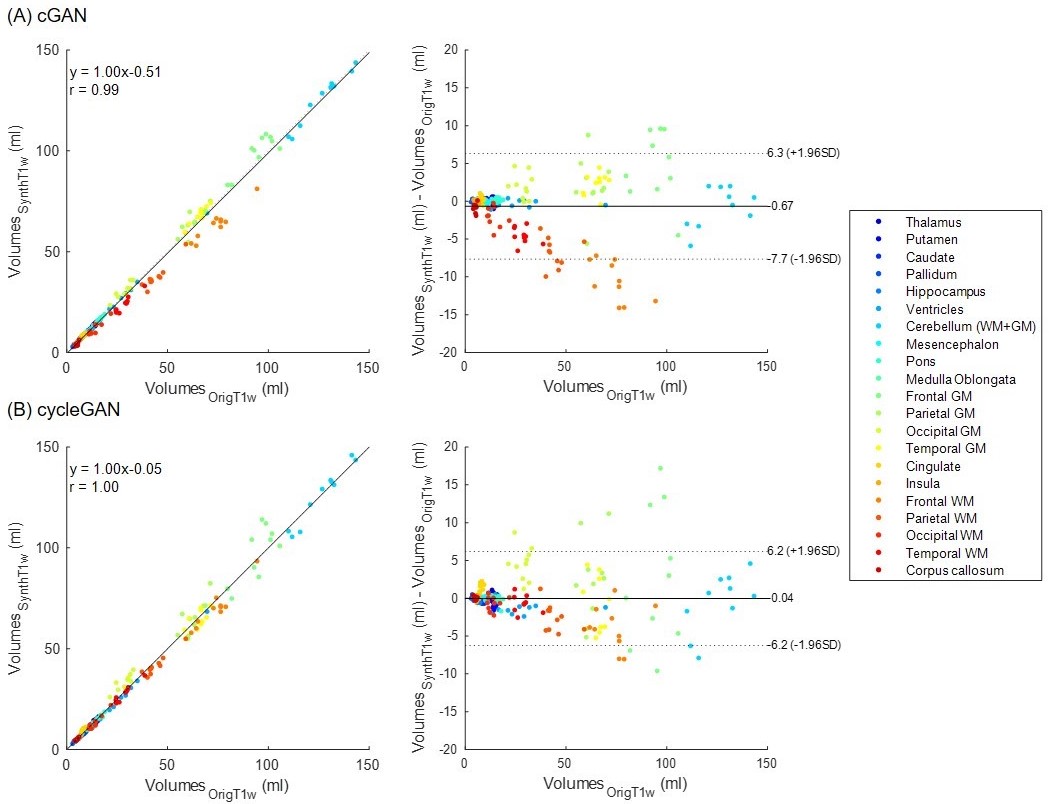
Acquired pre-Gd and post-Gd T1w images are shown in Figure 1 for three example patients along with the synthetized images. Under visual inspection, synthetic T1w pre-Gd images appear generally to retain comparable contrast between gray and white matter to the original images, although being slightly more blurred in certain structures, such as the cerebellum. Representative segmentation brain masks obtained in the original and synthetic pre-Gd images are reported in Figure 2, visually demonstrating the capability of achieving high quality segmentation from the synthetic images. Quantitatively, estimated regional volumes from synthetic images were found to not significantly differ from those derived from original T1w images (Table 2). Good correlation (r>0.99, p<0.001) and an average bias of -0.67 ml (limits of agreement at 95% of confidence: [-7.7; 6.3] ml) was observed between volumes computed in original and cGAN-generated images, whereas a smaller bias of -0.04 ml (limits of agreement at 95% of confidence: [-6.2; 6.2] ml) was found when comparing to cycleGAN-generated images (Figure 3).Discussion and Conclusion
This study proposes the use of image-to-image translation models for the generation of pre-Gd T1w contrasts from post-Gd acquisitions to be able to automatically extract valuable biomarkers when pre-Gd T1 images are missing. Although the investigated deep learning architectures both delivered images with comparable contrast to the original T1w, a smaller bias in the estimation of brain volumes was observed in the images derived from the cycleGAN. These results might be explained by the simultaneous learning of both mapping transformations from pre-Gd to post-Gd images and vice versa, which in turn improves the overall training procedure. The remaining biases found in the volumetric estimation might be due to the increased blurriness observed in the synthetic images. In this direction, future work is planned to compare different architectures for the generators and discriminators and increase the training samples.In conclusion, the proposed modelling strategy can have a direct practical utility in clinical studies that lack non-contrast-enhanced T1w images as, for example, a substantial amount of multiple sclerosis studies; this enables also these protocols to benefit from the automated analysis of anatomical brain scans.
Acknowledgements
No acknowledgement found.References
1. Rovira À, Wattjes MP, Tintoré M, et al. Evidence-based guidelines: MAGNIMS consensus guidelines on the use of MRI in multiple sclerosis—clinical implementation in the diagnostic process. Nat Rev Neurol. 2015;11(8):471-482.
2. Vågberg M, Axelsson M, Birgander R, et al. Guidelines for the use of magnetic resonance imaging in diagnosing and monitoring the treatment of multiple sclerosis: recommendations of the Swedish Multiple Sclerosis Association and the Swedish Neuroradiological Society. Acta Neurol Scand. 2017;135(1):17-24.
3. García-Lorenzo D, Francis S, Narayanan S, Arnold DL, Collins DL. Review of automatic segmentation methods of multiple sclerosis white matter lesions on conventional magnetic resonance imaging. Med Image Anal. 2013;17(1):1-18.
4. Fartaria MJ, Todea A, Kober T, et al. Partial volume-aware assessment of multiple sclerosis lesions. NeuroImage Clin. 2018;18:245-253.
5. Ashburner J. Computational anatomy with the SPM software. Magn Reson Imaging. 2009;27(8):1163-1174.
6. Fischl B. FreeSurfer. Neuroimage. 2012;62(2):774-781.
7. Schmitter D, Roche A, Maréchal B, et al. An evaluation of volume-based morphometry for prediction of mild cognitive impairment and Alzheimer’s disease. NeuroImage Clin. 2015;7:7-17.
8. Isola P, Zhu J-Y, Zhou T, Efros AA, Research BA. Image-to-Image Translation with Conditional Adversarial Networks. arXiv Prepr. 2017.
9. Zhu J-Y, Park T, Isola P, Efros AA. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE; 2017:2242-2251.
10. Dar SUH, Yurt M, Karacan L, Erdem A, Erdem E, Çukur T. Image Synthesis in Multi-Contrast MRI with Conditional Generative Adversarial Networks. IEEE Trans Med Imaging. February 2018:1-1.
11. Mugler JP, Brookeman JR. Three-dimensional magnetization-prepared rapid gradient-echo imaging (3D MP RAGE). Magn Reson Med. 1990;15(1):152-157.
12. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Lecture Notes in Computer Science. Vol 9351. ; 2015:234-241.
13. Klein S, Staring M, Murphy K, Viergever MA, Pluim J. elastix: A Toolbox for Intensity-Based Medical Image Registration. IEEE Trans Med Imaging. 2010;29(1):196-205.
Figures