1005
Attention-Gated Convolutional Neural Networks for Off-Resonance Correction of Spiral Real-Time Magnetic Resonance Imaging1University of Southern California, Los Angeles, CA, United States
Synopsis
Spiral acquisitions are preferred in real-time MRI because of their efficiency, which has made it possible to capture vocal tract dynamics during natural speech. A fundamental limitation of spirals is blurring and signal loss due to off-resonance, which degrades image quality at air-tissue boundaries. Here, we present a new CNN-based off-resonance correction method that incorporates an attention-gate mechanism. This leverages spatial and channel relationships of filtered outputs and improves the expressiveness of the networks. We demonstrate improved performance with the attention-gate, on 1.5T spiral speech RT-MRI, compared to existing off-resonance correction methods.
Introduction
Blurring and signal loss due to off-resonance are the primary limitations of spiral MRI1–3. In the context of speech real-time MRI (RT-MRI), off-resonance degrades image quality most significantly at air-tissue boundaries4–6, which are the exact locations of interest. Blurring and signal loss is the result of a complex-valued spatially varying convolution. In order to resolve the artifact, conventional methods7–12 reconstruct basis images at demodulation frequencies and apply spatially-varying masks to the basis images to form a desired sharp image.Recently, convolutional neural network (CNN) approaches have shown promise in solving this spiral deblurring task13,14. The conventional methods require field maps7,8 or focus metrics9,11,12 to estimate the spatially-varying mask. One of the advantages of CNN is that once trained, ReLU nonlinearity provides the mask to convolution filters, enabling spatially-varying convolution15. Since ReLU masks out the activation in an element-wise manner, it cannot exploit local spatial or channel (filter) dependency, unlike the conventional methods.
In this work, we present a CNN-based deblurring method that adapts the attention-gate (AG) mechanism (AG-CNN) to exploit spatial and channel relationships of filtered outputs to improve the expressiveness of the networks16–18. We demonstrate improved deblurring performance for 1.5T spiral speech RT-MRI, compared to a recent CNN study14, and several conventional methods.
Methods
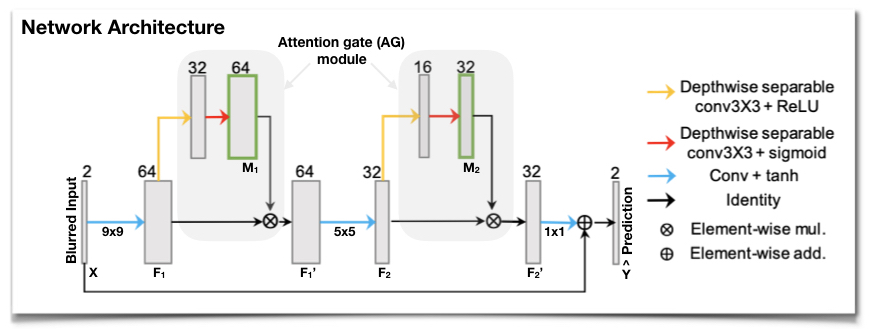
Network ArchitectureWe use a simple 3-layer residual CNN architecture14 and incorporate a proposed AG module at each convolutional layer, as illustrated in Figure 1. The AG takes the output feature maps (F) from a convolution unit as an input and performs two cascaded depth-wise separable convolutions to generate attention maps (M) in the range from 0 to 1. Depth-wise separable convolution19 is used to improve the AG module in both performance and overhead. The attention maps M learn to identify salient image regions and channels adaptively for given feature maps F, and they preserve only the activation relevant to the deblurring task in the following convolution layers. The AG multiplies the attention map by the convolution output (i.e., F’ = M(F)$$$\otimes$$$F) to emphasize important elements in space and across channels.
Training Data
2D RT-MRI data from 33 subjects were acquired at our institution on a 1.5T scanner (Signa Excite, GE Healthcare, Waukesha, WI) using a vocal-tract imaging protocol20. It uses a short readout (2.52ms) spiral spoiled-gradient-echo sequence. Ground truth images were obtained after off-resonance correction6. We augmented field maps estimated in the correction step by scaling $$$\bf{f'} = \alpha\bf{f}+\beta$$$ with $$$\alpha$$$ ranging from 0 to 3.15 and $$$\beta$$$ ranging from -200 to 200 Hz. Distorted images were then synthesized by using the discrete object approximation and simulating off-resonance using the field map $$$\bf{f'}$$$ and spiral trajectories with readout lengths of 2.520, 4.016, 5.320, and 7.936ms. We split data into 23, 5, and 5 subjects for training, validation, and testing.
Network Training
Our model was trained in a combination of L1 loss ($$$\mathcal{L}_1$$$) and gradient difference loss ($$$\mathcal{L}_{gdl}$$$)22 between the prediction and ground truth as $$$\mathcal{L} = \mathcal{L}_1+\mathcal{L}_{gdl}$$$. In addition to $$$\mathcal{L}_1$$$, $$$\mathcal{L}_{gdl}$$$ is known to provide a sharp image prediction. We used Adam optimizer23 with a learning rate of 1e-3, a mini-batch size of 64, and 200 epochs. We implemented our network with Keras using Tensorflow backend.
Experiments
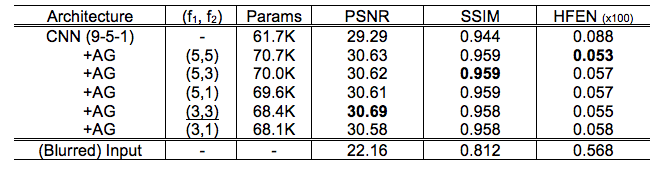
We investigate the effectiveness of the AG module by varying depth-wise separable convolution filter sizes, f1 and f2 of the first and second AG modules. Two cascaded convolutions in an AG module uses the same filter size of either f1 or f2. For comparison, we also deblur images with various existing methods: the previous CNN architecture15, multi-frequency interpolation (MFI)7, and iterative reconstruction (IR)24. Note that field maps are necessary for deblurring in the latter two methods, so we assume ground truth field maps are known for those two, although those would not be available in practice. For all those methods, dynamic images were deblurred frame-by-frame. We report quantitative quality comparison using peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and high-frequency error norm (HFEN).
Results and Discussion
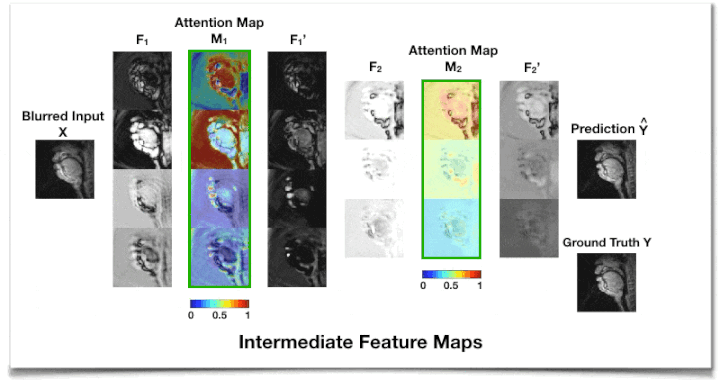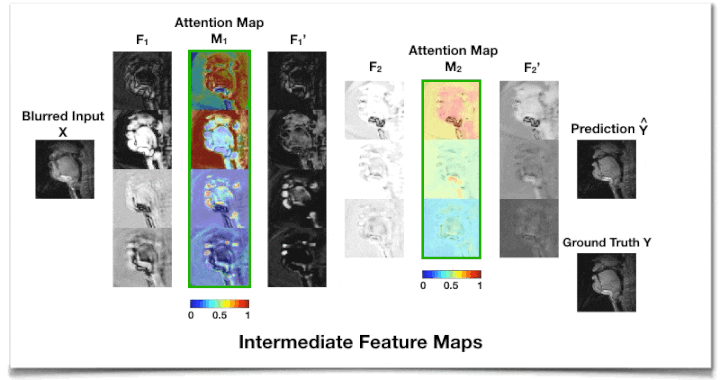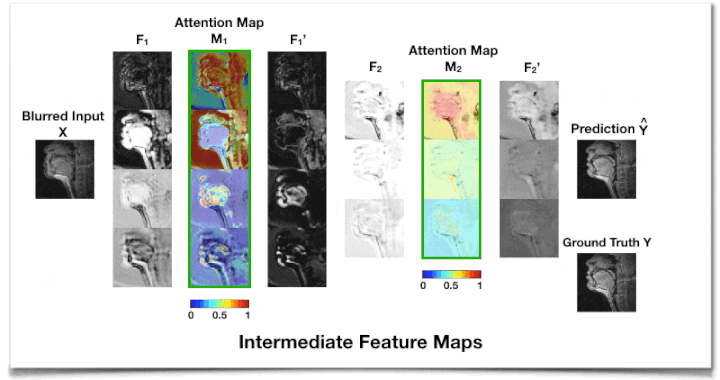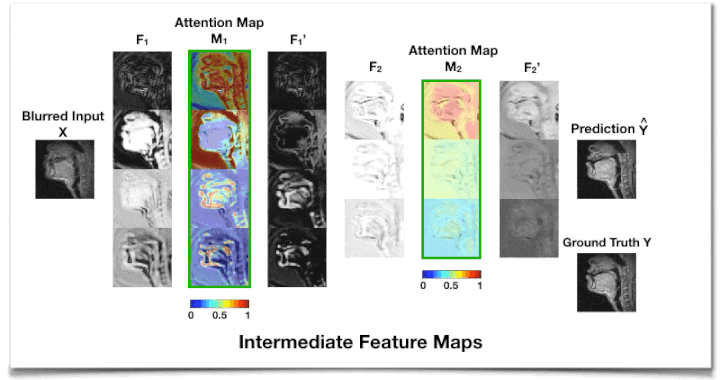
Figure 2 shows the intermediate feature maps. We observe that the attention map M1 from the first AG module tends to focus on low-level structures such as tissue, air, or air-tissue boundaries with a different focus across channels, while M2 from the second AG focuses on a high-level channel dependency.Table 1 shows that adding an AG module on top of CNN layers improves deblurring performance with a slight overhead and less sensitivity to the kernel size. An extensive comparison with existing attention approaches17,18,25 applicable to this task remains as future work.
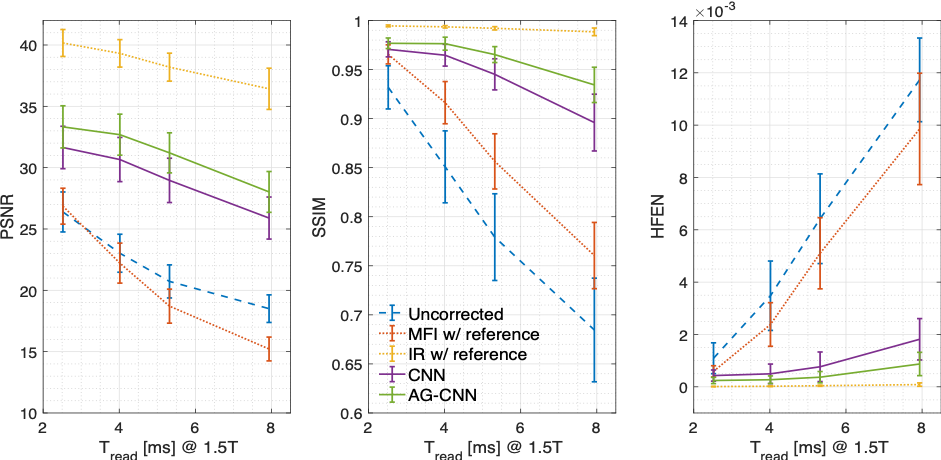
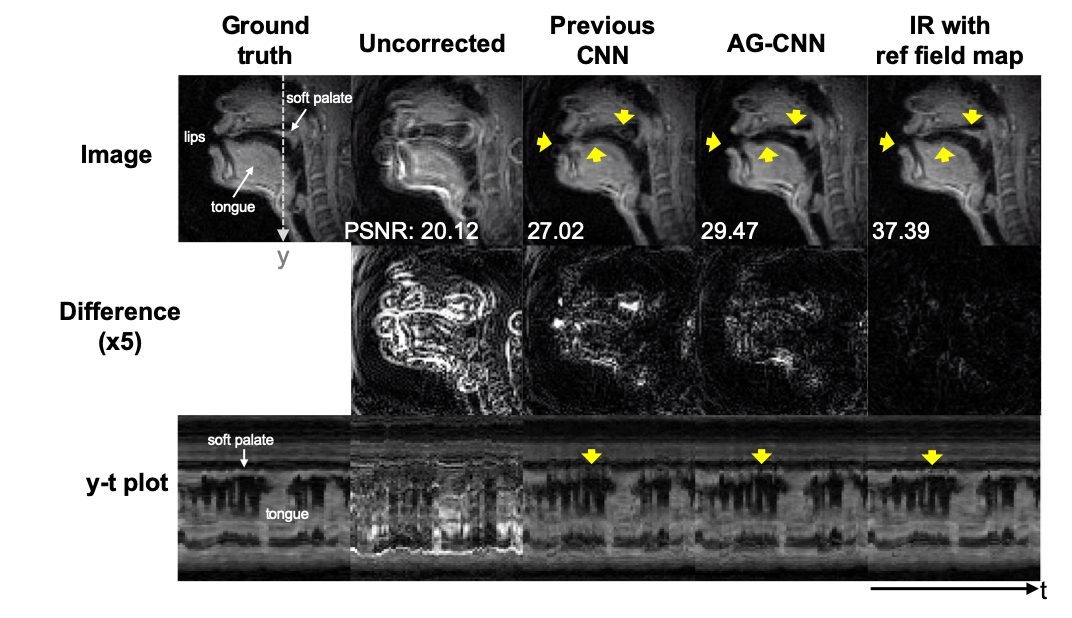
Figure 3 shows that AG-CNN outperforms the previous CNN and MFI using a reference field map in multiple readout duration lengths. Figure 4 contains representative image frames. Blurring of the lips and soft palate are not perfectly resolved with the previous CNN method. AG-CNN provides substantially improved depiction of these and other air-tissue boundaries.
Conclusion
We demonstrate AG-CNN deblurring for 1.5T spiral speech RT-MRI. Adding an AG module on top of CNN layer improves deblurring performance by >1dB PSNR, >0.014 SSIM, and >0.029 HFEN compared to the previous CNN architecture and provides results visually comparable to reference IR method with ~10 times faster computation, and without the need for a field map.Acknowledgements
This work was supported by NIH Grant R01DC007124 and NSF Grant 1514544.References
1. Meyer CH, Hu BS, Nishimura DG, Macovski A. Fast spiral coronary artery imaging. Magn Reson Med. 1992;28:202–213.
2. Schenck JF. The role of magnetic susceptibility in magnetic resonance imaging: MRI magnetic compatibility of the first and second kinds. Med Phys. 1996;23:815–850.
3. Block KT, Frahm J. Spiral imaging: A critical appraisal. J Magn Reson Imag. 2005;21:657–668.
4. Sutton BP, Noll DC, Fessler JA. Dynamic field map estimation using a spiral-in/spiral-out acquisition. Magn Reson Med. 2004;51:1194–1204.
5. Feng X, Blemker SS, Inouye J, Pelland CM, Zhao L, Meyer CH. Assessment of velopharyngeal function with dual-planar high-resolution real-time spiral dynamic MRI. Magn Reson Med. 2018;80:1467–1474.
6. Lim Y, Lingala SG, Narayanan SS, Nayak KS. Dynamic off-resonance correction for spiral real-time MRI of speech. Magn Reson Med. 2019;81:234–246.
7. Man LC, Pauly JM, Macovski A. Multifrequency interpolation for fast off-resonance correction. Magn Reson Med. 1997;37:785–792.
8. Nayak KS, Tsai CM, Meyer CH, Nishimura DG. Efficient off-resonance correction for spiral imaging. Magn Reson Med. 2001;45:521–524.
9. Noll DC, Pauly JM, Meyer CH, Nishimura DG, Macovskj A. Deblurring for non‐2D fourier transform magnetic resonance imaging. Magn Reson Med. 1992;25:319–333.
10. Chen W, Meyer CH. Semiautomatic off-resonance correction in spiral imaging. Magn Reson Med. 2008;59:1212–1219.
11. Lim Y, Lingala SG, Narayanan S, Nayak KS. Improved Depiction of Tissue Boundaries in Vocal Tract Real-time MRI using Automatic Off-resonance Correction. In Proc of INTERSPEECH, San Francisco, USA, Sep 2016. pp. 1765–1769.
12. Man LC, Pauly JM, Macovski A. Improved automatic off-resonance correction without a field map in spiral imaging. Magn Reson Med. 1997;37:906–913.
13. Zeng DY, Shaikh J, Holmes S, Brunsing RL, Pauly JM, Nishimura DG, Vasanawala SS, Cheng JY. Deep residual network for off-resonance artifact correction with application to pediatric body MRA with 3D cones. Magn Reson Med. 2019;82:1398–1411.
14. Lim Y, Narayanan S, Nayak KS. Calibrationless deblurring of spiral RT-MRI of speech production using convolutional neural networks. In Proc of ISMRM 27th Scientific Session, Montreal, Canada, May 2019. p. 673.
15. Ye JC, Sung WK. Understanding Geometry of Encoder-Decoder CNNs. In Proc of the 36th ICML, Long Beach, California, PMLR 97, 2019.
16. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In Proc of IEEE/CVF Conf on CVPR, Salt Lake City, UT, 2018, pp. 7132–7141.
17. Woo S, Park J, Lee J, Kweon IS. CBAM: Convolutional block attention module. In Proc of ECCV, 2018.
18. Schlemper J, Oktay O, Schaap M, Heinrich M, Kainz B, Glocker B, Rueckert D. Attention gated networks: Learning to leverage salient regions in medical images. Med Image Anal. 2019;53:197–207.
19. Chollet F. Xception: Deep learning with depthwise separable convolutions. In Proc of IEEE/CVF Conf on CVPR, 2017.
20. Lingala SG, Zhu Y, Kim Y-C, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn Reson Med. 2017;77:112–125.
21. Mathieu M, Couprie C, LeCun Y. Deep multi-scale video prediction beyond mean square error. In Proc of ICLR. 2015.
22. Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv:1412.6980. 2014.
23. Sutton BP, Noll DC, Fessler JA. Fast, iterative image reconstruction for MRI in the presence of field inhomogeneities. IEEE Trans Med Imaging. 2003;22:178–188.
Figures