1002
DYNAMIC MRI USING DEEP MANIFOLD SELF-LEARNING1University of Iowa, Iowa City, IA, United States
Synopsis
We propose a deep self-learning algorithm to learn the manifold structure of free-breathing and ungated cardiac data and to recover the cardiac CINE MRI from highly undersampled measurements. Our method learns the manifold structure in the dynamic data from navigators using autoencodernetwork. The trained autoencoder is then used as aprior in the image reconstruction framework. We have testedthe proposed method on free-breathing and ungated cardiacCINE data, which is acquired using a navigated golden-anglegradient-echo radial sequence. Results show the ability ofour method to better capture the manifold structure, thus providingus reduced spatial and temporal blurring as comparedto the SToRM reconstruction.
Background
Many patients (e.g pediatric & CoPD patients) are often excluded from current breath-held cardiac cine MRI protocols due to their inability in holding breath. Many methods have been proposed to overcome this problem, either using explicit binning with compressed sensing [1] or exploiting the structure in the dynamic data [2]. Recently, methods that rely on deep learning have been proposed in MRI reconstruction. Both direct inversion methods that rely on a large CNN to recover the data directly from the measurements as well as model-based strategies that rely on regularization penalties that involve smaller CNN blocks, have been introduced with promising results. The extension of CNN based methods to the 2D+time setting in dynamic MRI is challenging due to the large size of the datasets as well as the need for 3-D filters. Moreover, there is considerable variability in temporal profiles between subjects due to the variability in cardiac and respiratory patterns, which makes it difficult for a pre-learned network to capture them.Methods
Data was collected on a 3T GE scanner using a golden angle rotated gradient echo radial pulse sequence with navigators. A temporal resolution of 46.8 ms was obtained by sampling 10 lines of k-space per frame. Each frame was sampled by two k-space navigator spokes, oriented at 0 degrees and 90 degrees respectively, which are used to learn the temporal CNN prior. Sequence parameters includes: TR/TE 4.68ms/2.1ms, slice thickness 8mm, number of slices 10~14 covering the whole heart, starting from apex to base of the heart and total number of subjects 18. For the experiments in this work, we retained the initial 10 seconds of the original acquisition. The reconstructed results were compared to SToRM reconstructions from 43 seconds of data as ground truth. We introduce a model based deep learning framework with two separate spatial and temporal priors to recover free breathing and ungated cardiac MRI data. This separable learning approach significantly reduces the memory demand of the learning process. More importantly, it facilitates the self-learning of the temporal profiles from k-space navigators. We formulate the recovery as: , $$\mathbf X^{*} = \arg \min_{\mathbf X} \|\mathcal A (\mathbf X)-\mathbf Y\|^{2}_{2}+ \lambda_1~ \|\mathbf X - \mathcal D_{\Theta}^{T}(\mathbf X)\|^{2} + \lambda_2~ \|\mathbf X - \mathcal D_{\Theta}^{S}(\mathbf X)\|^{2} (1) $$Here, $$$\mathcal D_{\Theta}^{T}$$$ and $$$\mathcal D_{\Theta}^{S}$$$ are temporal and spatial deep learned denoising priors to exploit the redundancy in the temporal and spatial components, respectively. We propose to self-learn the temporal denoiser $$$\mathcal D_{\Theta}^{T}$$$ from k-space navigators of each subject using a denoising auto-encoder (DAE). This patient-dependent prior is different for each subject and is designed to capture the respiratory and cardiac pattern. This approach is motivated by theoretical results, which shows that DAE captures the smoothed probability density of the data, while the residual representation error is a measure of the derivative of the log density [3]. Unlike the temporal prior, the spatial prior is population generic and is pre-learned from exemplar data. The spatial network $$$\mathcal D_{\Theta}^{S}$$$ is learned using a six-layer CNN from training data estimated from the 42 seconds-SToRM reconstruction, which includes 16 subjects out of 18 subjects. Each subject has 10~14 slices to cover the whole heart and within each slice there are 900 frames.
Results
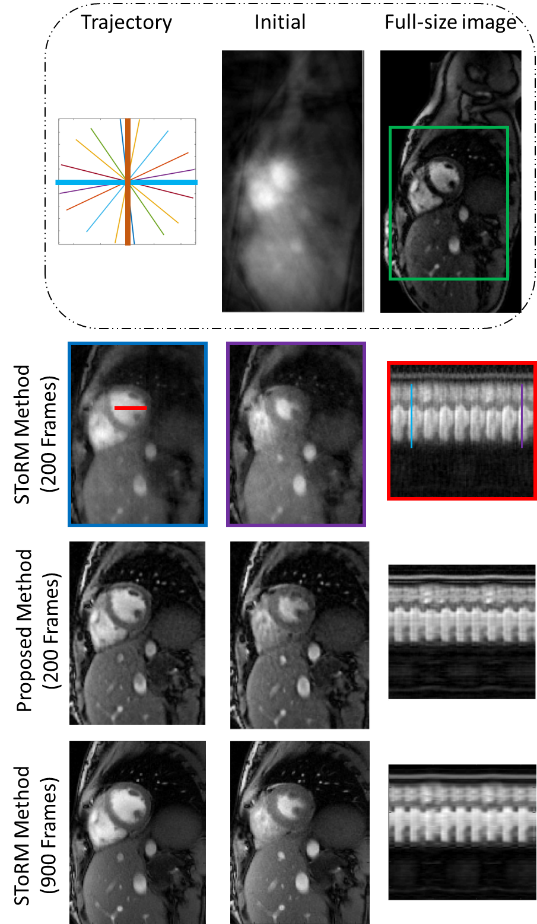
Fig 1 shows the benefit of using spatial-temporal priors. First row shows the results of spatial prior as a regularizer. We observe see some residual aliasing artifacts. Second row shows the temporal prior based reconstruction, which offers better recovery than the spatial prior. Specifically, we notice improved temporal fidelity. Third row shows the results of using both spatial and temporal priors, which offers the best results. The comparison of the proposed method against the SToRM method is shown in Fig 2. We observe that the SToRM scheme provides good reconstructions from 900 frames (42 seconds of data). However, this scheme results in quite significant distortions when only 10 seconds of data(200 frames) is available. By contrast, the proposed method provides reduced aliasing artifacts and improved sharpness, when compared to the SToRM reconstruction with 200 frames.Discussion
In this method, we have reconstructed cardiac cine MRI using two separable deep learning image priors, which capture the spatial and temporal redundancies in the data, respectively. The temporal CNN is self-learned from the k-space navigators, while the spatial network is pre-learned from exemplar data. Our results show that the proposed approach provides better recovery than SToRM reconstructions using same amount of data. Specifically, the reconstructions exhibit considerably reduced spatial and temporal blurring.Conclusion
In this work, we have proposed a new dynamic MRI reconstruction method based on the deep learning image priors. We have trained the denoising autoencoder using navigator data, to learn the dynamic structure in the cardiac CINE images. To incorporate the spatial regularization, we have trained the six layers CNN. Then these trained networks are used as the image priors to reconstruct the cardiac CINE images from highly undersampled data. Results show the ability of our method to give better spatial and temporal resolution.Acknowledgements
No acknowledgement found.References
1. Feng, Li, Leon Axel, Hersh Chandarana, Kai Tobias Block, Daniel K. Sodickson, and Ricardo Otazo. "XD‐GRASP: golden‐angle radial MRI with reconstruction of extra motion‐state dimensions using compressed sensing." Magnetic resonance in medicine 75, no. 2 (2016): 775-788.
2. Poddar, Sunrita, Yasir Mohsin, Deidra Ansah, Bijoy Thattaliyath, Ravi Ashwath, and Mathews Jacob. "Manifold recovery using kernel low-rank regularization: application to dynamic imaging." IEEE Transactions on Computational Imaging (2019).
3. Vincent, Pascal, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. "Extracting and composing robust features with denoising autoencoders." In Proceedings of the 25th international conference on Machine learning, pp. 1096-1103. ACM, 2008.
Figures