1001
CINENet: Deep learning-based 3D Cardiac CINE Reconstruction with multi-coil complex 4D Spatio-Temporal Convolutions
Thomas Küstner1, Niccolo Fuin1, Kerstin Hammernik2, Aurelien Bustin1, Radhouene Neji1,3, Daniel Rueckert2, René M Botnar1, and Claudia Prieto1
1Biomedical Engineering Department, School of Biomedical Engineering and Imaging Sciences, King's College London, London, United Kingdom, 2Department of Computing, Imperial College London, London, United Kingdom, 3MR Research Collaborations, Siemens Healthcare Limited, Frimley, United Kingdom
1Biomedical Engineering Department, School of Biomedical Engineering and Imaging Sciences, King's College London, London, United Kingdom, 2Department of Computing, Imperial College London, London, United Kingdom, 3MR Research Collaborations, Siemens Healthcare Limited, Frimley, United Kingdom
Synopsis
CINE MRI is the gold-standard for the assessment of cardiac function. Compressed Sensing (CS) reconstruction has enabled 3D CINE acquisition with left ventricular (LV) coverage in a single breath-hold. However, maximal achievable acceleration is limited by the performance of the selected reconstruction method. Deep learning has shown to provide good-quality reconstructions of highly accelerated 2D CINE imaging. In this work, we propose a novel 4D (3D+time) reconstruction network for prospectively undersampled 3D Cartesian cardiac CINE that utilizes complex-valued spatial-temporal convolutions. The proposed network outperforms CS in visual quality and shows good agreement for LV function to gold-standard 2D CINE.
Introduction
CINE MRI is the gold-standard for the assessment of cardiac function. Conventionally, multi-slice 2D CINE is performed under multiple breath-holds to achieve left ventricular (LV) coverage. However, slice misalignments due to different breath-hold positions may lead to erroneous assessment of ventricular volume1. Parallel Imaging and Compressed Sensing (CS)2-5 have been used to enable single breath-hold 3D CINE imaging. However, maximal achievable acceleration is limited by the performance of the selected reconstruction method, leading to a trade-off between spatial and temporal resolution. Previous methods therefore only achieved anisotropic resolution3. A 3D Cartesian Cardiac CINE acquisition which achieves isotropic resolution in a single breath-hold of ~20s for LV coverage was recently proposed6.Further reduction of the breath-hold duration is desirable, but can only be achieved with an increase in undersampling. Highly undersampled data leads to a challenging ill-posed reconstruction problem for which spatial-temporal redundancies need to be fully exploited. Deep-learning based reconstruction methods have gained attention recently7,8 to solve non-linear optimizations efficiently. Previously proposed networks focused on cascaded convolutional neural networks (CNN)9, recurrent neural networks8 or 2D+1D spatio-temporal CNNs10,11 for the reconstruction of 2D dynamic datasets with coil-combined data.
In this work, we propose a novel multi-coil complex-valued 4D (3D+time) CNN to reconstruct highly prospectively undersampled 3D Cartesian cardiac CINE data. The network is trained on in-house acquired 3D Cartesian cardiac CINE data. The proposed 4D CINENet exploits 3D spatial and temporal redundancies combined with a complex-valued processing7,12,13 and handling of multi-coil data14. CINENet is trained and evaluated on prospectively undersampled 3D Cartesian cardiac CINE data and compared against a CS reconstruction3 and to the clinical gold-standard 2D CINE sequence.
Methods
Data were acquired in 14 subjects with a prospectively ECG-triggered balanced steady-state free-precession sequence (TE=1.3ms, TR=2.6ms, flip angle=39°, spatial resolution=1.9mm3 isotropic, temporal resolution=~50ms, 16 cardiac phases) and a variable-density spiral-like Cartesian trajectory6. A sequence-adaptive tiny-golden and golden increment between consecutive spiral arms and an out-inward trajectory enables incoherent and non-redundant sampling between and within cardiac phases. Each cardiac phase is undersampled by a pre-set acceleration factor L for imaging of the LV within a single breath-hold. For comparison, multi breath-hold 2D CINE imaging was acquired with 10 slices (1.9x1.9x8mm).Prospectively undersampled datasets are reconstructed by the proposed 4D CINENet as depicted in Fig.1. The network reflects an unrolled ADMM algorithm with cascaded 4D UNets and intermittent data consistency blocks. The input to the network is the complex-valued undersampled image $$$x\in\mathbb{C}^{N_x\times\,N_y\times\,N_z\times\,N_t}$$$ with spatial matrix size $$$N_x=112,N_y=160,N_z=36$$$ and $$$N_t=16$$$ cardiac phases, as well as the acquired k-space $$$y\in\mathbb{C}^{N_x\times\,N_y\times\,N_z\times\,N_t\times\,N_{ch}}$$$ with $$$N_{ch}=14$$$ MR receiver coils and the undersampling mask $$$\phi\in\mathbb{Z}^{N_y\times\,N_z}$$$. The coil sensitivity maps $$$S\in\mathbb{C}^{N_x\times\,N_y\times\,N_z\times\,N_{ch}}$$$ are obtained with ESPIRIT15. The 4D UNet has four encoding and decoding stages which consist of complex-valued spatial convolutional layers of size 3x3x1 ($$$k_y\times\,k_z\times\,t$$$) followed by a temporal convolution of size 1x1x2, a complex batch normalization and complex ReLU activation. A dyadic increase in channel size is selected between stages. Residual paths within stages and between encoder/decoder stages improve convergence. In the encoder branch max-pooling is applied between stages while transposed convolutions are performed in the decoder side. The data consistency follows the approach proposed from Schlemper et al.9.
For three cascaded 4D UNets, the overall network results in ~900.000 trainable parameters. Training images were acquired in 14 healthy subjects with an acceleration factor L=2.5 (1.9x1.9x3.8mm acquired resolution) in an extended single breath-hold of TA=~30s and reconstructed with iterative SENSE to serve as reference for training. Retrospective subsampling (L=3 to 8) of the reference data forms together with the reference image the input training pairs which minimize a mean squared error (MSE) loss optimized by ADAM16 with a learning rate of 10-4 and data consistency parameter $$$\lambda=10^{-3}$$$. Training took ~24h, but inference is performed in ~3s. A 3-fold cross-validation with training from scratch on 11 healthy subjects was conducted with 3 healthy subjects (not included in training) left-out for testing. Testing was performed on separately acquired and prospectively undersampled data of L=9,11,15 respectively TA=~16s, ~13s, ~10s (1.9mm3 isotropic resolution) in overall 9 subjects (not included in training). Reconstruction results are compared qualitatively against a zero-filled and CS (spatio-temporal wavelets3) reconstruction and against the 2.5x reference image (separate acquisition) and quantitatively against a conventional multi breath-hold 2D CINE by comparing LV functional parameters: end-systolic volume (ESV), end-diastolic volume (EDV) and ejection fraction (EF), which were derived from manually segmented LV endo- and epicardium.
Results and Discussion
Animated Figs.2+3 show the cardiac motion-resolved reconstructions of two test subjects with different heart rate and body mass index, i.e. fat-related aliasing. Visually improved reconstruction results are obtained with the proposed network compared to CS. Especially for highly accelerated datasets (L>9), the proposed CINENet still achieves good quality images. Animated Fig. 4 shows the motion-resolved spatial coverage of a 3D CINE (L=15) reconstructed with CINENet in comparison to gold-standard 2D CINE imaging revealing high agreement. Fig.5 depicts the LV functional parameters indicating minimal bias for ESV/EDV, but close agreement for EF with tight confidence intervals for ESV=±2.4ml, EDV=±2.1ml and EF=±1.7%.Conclusion
Deep learning reconstruction for 3D Cartesian cardiac CINE is feasible with the proposed 4D CINENet providing good image quality in prospectively highly accelerated acquisitions.Acknowledgements
This work was supported by EPSRC (EPSRC EP/P032311/1, EP/P001009/1 and EP/P007619/1) and Wellcome EPSRC Centre for Medical Engineering (NS/A000049/1).References
1. Jahnke C, Paetsch I, Achenbach S, Schnackenburg B, Gebker R, Fleck E, Nagel E. Coronary MR imaging: breath-hold capability and patterns, coronary artery rest periods, and beta-blocker use. Radiology 2006;239(1):71-78.2. Kressler B, Spincemaille P, Nguyen TD, Cheng L, Xi Hai Z, Prince MR, Wang Y. Three-dimensional cine imaging using variable-density spiral trajectories and SSFP with application to coronary artery angiography. Magnetic resonance in medicine 2007;58(3):535-543.
3. Wetzl J, Schmidt M, Pontana F, Longère B, Lugauer F, Maier A, Hornegger J, Forman C. Single-breath-hold 3-D CINE imaging of the left ventricle using Cartesian sampling. Magn Reson Mater Phy 2018;31(1):19-31.
4. Barkauskas KJ, Rajiah P, Ashwath R, Hamilton JI, Chen Y, Ma D, Wright KL, Gulani V, Griswold MA, Seiberlich N. Quantification of left ventricular functional parameter values using 3D spiral bSSFP and through-time non-Cartesian GRAPPA. J Cardiovasc Magn Reson 2014;16:65.
5. Makowski MR, Wiethoff AJ, Jansen CH, Uribe S, Parish V, Schuster A, Botnar RM, Bell A, Kiesewetter C, Razavi R, Schaeffter T, Greil GF. Single breath-hold assessment of cardiac function using an accelerated 3D single breath-hold acquisition technique--comparison of an intravascular and extravascular contrast agent. J Cardiovasc Magn Reson 2012;14:53.
6. Küstner T, Bustin A, Neji R, Botnar R, Prieto C. 3D Cartesian Whole-heart CINE MRI Exploiting Patch-based Spatial and Temporal Redundancies. Proceedings of the European Society for Magnetic Resonance in Medicine (ESMRMB); 2019.
7. Hammernik K, Klatzer T, Kobler E, Recht MP, Sodickson DK, Pock T, Knoll F. Learning a variational network for reconstruction of accelerated MRI data. Magnetic resonance in medicine 2018;79(6):3055-3071.
8. Qin C, Schlemper J, Caballero J, Price AN, Hajnal JV, Rueckert D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imag 2019;38(1):280-290.
9. Schlemper J, Caballero J, Hajnal JV, Price AN, Rueckert D. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imag 2018;37(2):491-503.
10. Zhao Y, Li X, Zhang W, Zhao S, Makkie M, Zhang M, Li Q, Liu T. Modeling 4D fMRI data via spatio-temporal convolutional neural networks (ST-CNN). International Conference on Medical Image Computing and Computer-Assisted Intervention; 2018. Springer. p 181-189.
11. Sandino CM, Lai P, Vasanawala SS, Cheng JY. DL-ESPIRiT: Improving robustness to SENSE model errors in deep learning-based reconstruction. Proceedings of the International Society for Magnetic Resonance in Medicine (ISMRM); 2019. p 659.
12. Dedmari MA, Conjeti S, Estrada S, Ehses P, Stöcker T, Reuter M. Complex Fully Convolutional Neural Networks for MR Image Reconstruction. International Workshop on Machine Learning for Medical Image Reconstruction; 2018. Springer. p 30-38.
13. Scardapane S, Van Vaerenbergh S, Hussain A, Uncini A. Complex-valued neural networks with nonparametric activation functions. IEEE Transactions on Emerging Topics in Computational Intelligence 2018.
14. Cheng JY, Mardani M, Alley MT, Pauly JM, Vasanawala SS. DeepSPIRiT: Generalized Parallel Imaging using Deep Convolutional Neural Networks. Proceedings of the International Society for Magnetic Resonance in Medicine (ISMRM); 2018. p 570.
15. Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, Vasanawala SS, Lustig M. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magnetic resonance in medicine 2014;71(3):990-1001.
16. Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:14126980 2014.
Figures
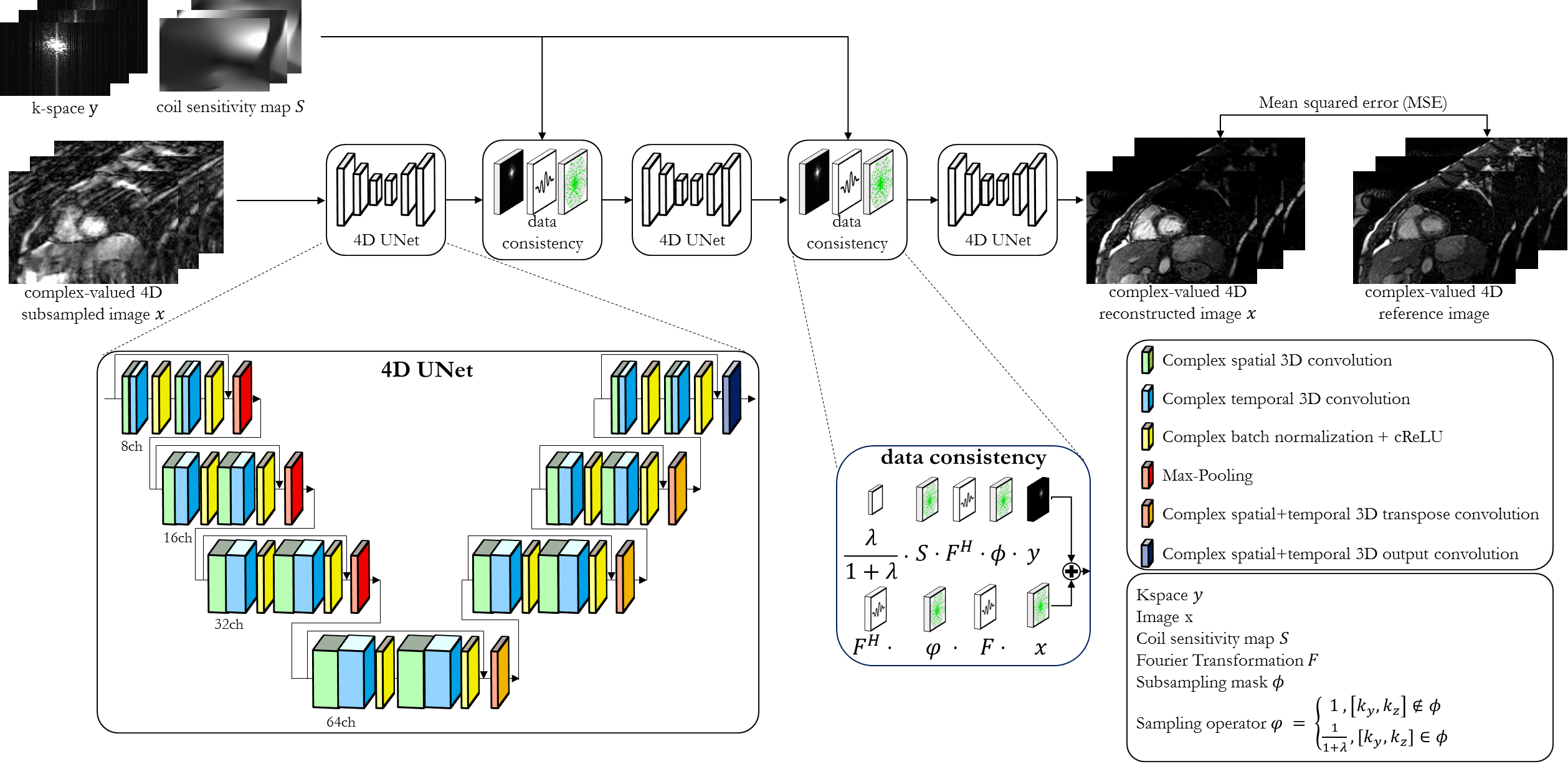
Fig.1: Proposed CINENet reconstruction network
as cascaded 4D (3D+time) UNets with intermittent data consistency blocks.
Complex-valued spatial-temporal convolutional layers are applied to the
complex-valued 4D subsampled images. Data consistency receives as input the
current reconstructed image, the k-space y,
coil sensitivity maps S, the
subsampling mask Φ and
the regularization parameter λ. The network is trained end-to-end with MSE
loss between retrospective undersampled image and “fully sampled” (2.5x
accelerated, reconstructed with iterative SENSE) reference.
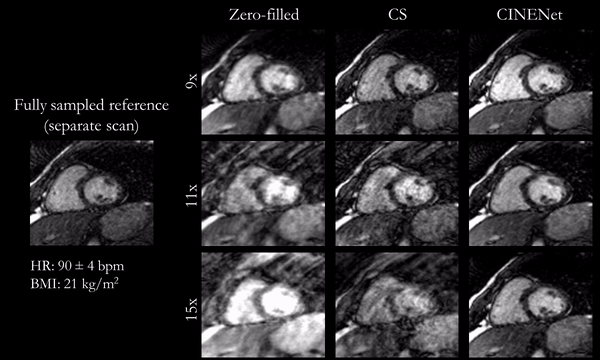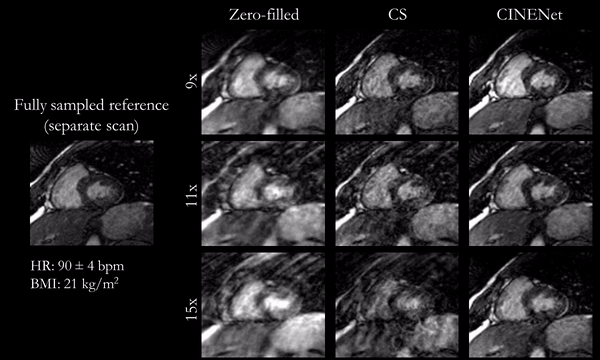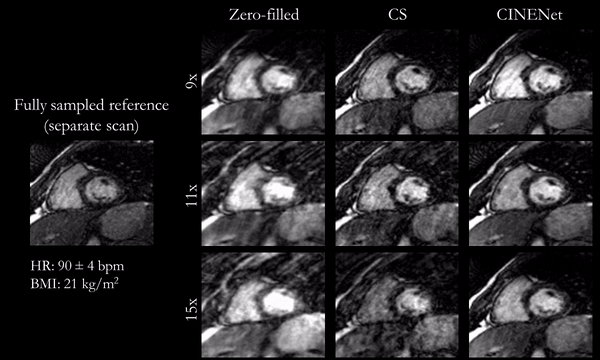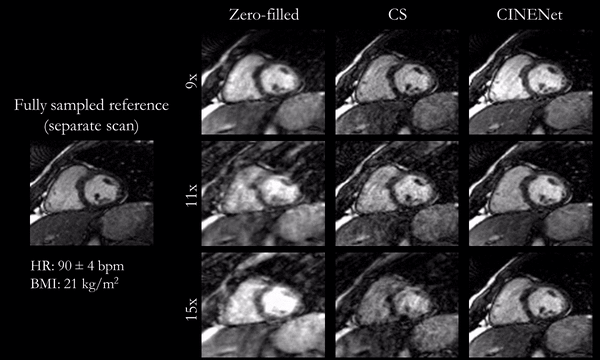
Fig.2
(animated): Cardiac motion-resolved reconstructions for prospectively undersampled
3D Cartesian CINE with acceleration 9x (TA=16s), 11x (TA=13s) and 15x (TA=10s).
Zero-filled, Compressed Sensing (CS) with spatial-temporal wavelets and
proposed CINENet reconstruction are depicted in comparison to “fully sampled”
(2.5x accelerated, reconstructed with iterative SENSE) reference (separate
acquisition).
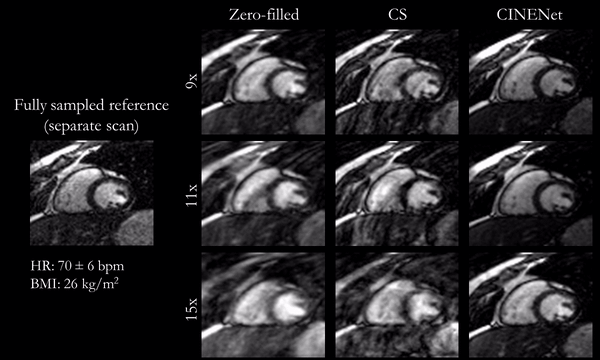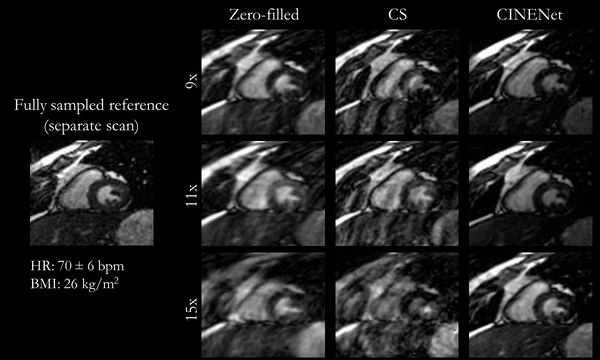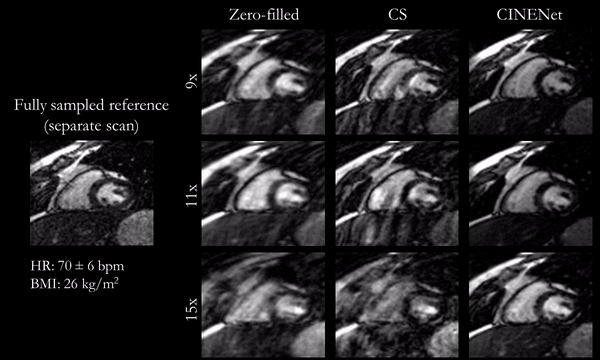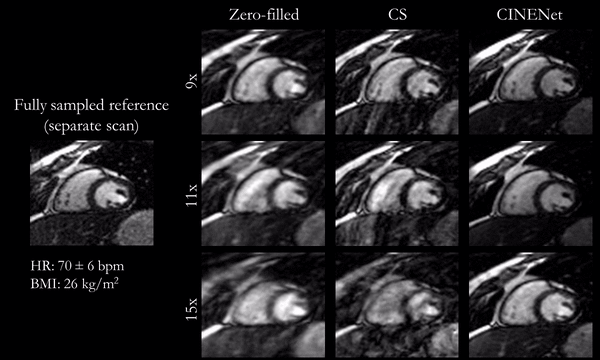
Fig.3
(animated): Cardiac motion-resolved reconstructions for prospectively undersampled
3D Cartesian CINE with acceleration 9x (TA=16s), 11x (TA=13s) and 15x (TA=10s).
Zero-filled, Compressed Sensing (CS) with spatial-temporal wavelets and
proposed CINENet reconstruction are depicted in comparison to “fully sampled”
(2.5x accelerated, reconstructed with iterative SENSE) reference (separate acquisition).

Fig.4 (animated): Cardiac motion-resolved images of 15x
accelerated 3D Cartesian CINE (acquisition time=10s) reconstructed with the
proposed 4D CINENet and conventional multi-slice and multi breath-hold 2D CINE
(acquisition time=4min20s). Similar anatomical slice locations to 2D CINE have
been selected for 3D CINE, i.e. not all 3D CINE slices are shown.
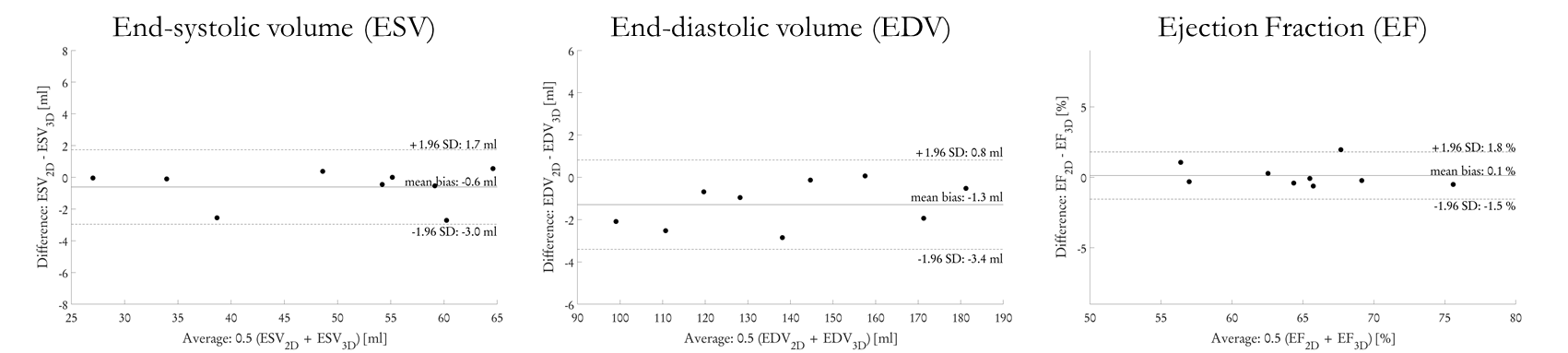
Fig.5: Extracted ventricular function parameters from
9 distinct subjects (3 test subjects in 3 cross-validation folds, 15x
prospectively undersampled) of end-systolic volume (ESV), end-diastolic volume
(EDV) and ejection fraction (EF) for 3D Cartesian cardiac CINE reconstructed
with 4D CINENet in comparison to conventional 2D CINE imaging.