0823
Water and Fat Separation with a Dixon Conditional Generative Adversarial Network (DixonCGAN)1Imaging Physics Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 2Diagnostic Radiology Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 3Department of Diagnostic Radiology, The University of Texas Southwestern Medical Center, Dallas, TX, United States, 4Cancer Systems Imaging Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States
Synopsis
A Dixon conditional generative adversarial network (DixonCGAN) was developed for Dixon water and fat separation. For the robust water image reconstruction, DixonCGAN performs water and fat separation with three processing steps: (1) phase-correction with DixonCGAN, (2) error-correction for DixonCGAN processing, and (3) the final water and fat separation. A conditional generative adversarial network (CGAN) originally designed to change photo styles could be successfully modified to perform phase-correction with improved global and local image details. Moreover, localized deep-learning processing errors could be effectively recovered with the proposed deep-learning error-correction processes.
INTRODUCTION
The conditional generative adversarial network (CGAN)1-3 uses two independent neural-networks that compete against each other to learn how to process images. During their learning processes, a “generator” learns how to create new images indistinguishable with output images provided only to a “discriminator.” The discriminator can learn how to distinguish images created by the generator from reference output images. Compared to traditional maximum-likelihood approaches, CGAN using CGAN loss models to evaluate the performance of both networks can learn global and local details of images, then depict them when creating new images.In this work, we developed a Dixon conditional generative adversarial network (DixonCGAN) for Dixon water and fat separation. The proposed framework is based on a CGAN originally designed to change photo styles.3 The errors created in the image-to-image translation were corrected in deep-learning error recovery processes.
METHODS
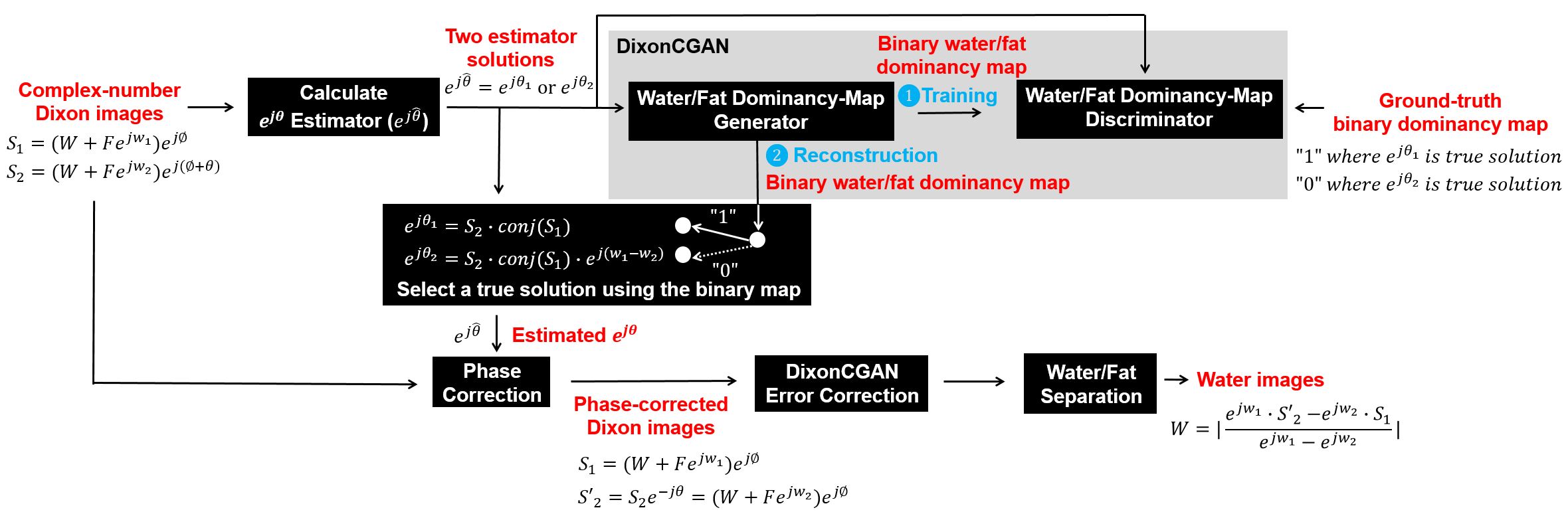
The DixonCGAN framework (Fig.1) was developed to perform water and fat separation in three stages: (1) phase-correction with DixonCGAN, (2) error-correction for DixonCGAN processing, and (3) the final water and fat separation.(1) Phase-correction: Dual-echo Dixon images ($$$S_{1}(\vec{x}),S_{2}(\vec{x})$$$) were acquired at arbitrary echo times and used to calculate two estimates ($$$e^{j\theta_{1}(\vec{x})},e^{j\theta_{2}(\vec{x})}$$$) for their background phase-difference ($$$e^{j\theta(\vec{x})}$$$) according to two signal models in Fig.1. DixonCGAN was trained with two estimate images ($$$e^{j\theta_{1}(\vec{x})}$$$ and $$$e^{j\theta_{2}(\vec{x})}$$$) to generate a binary water and fat dominancy map. The ground-truth binary-map for the training was semantically segmented as “1” where $$$e^{j\theta_{1}(\vec{x})}$$$ is a true solution, and “0” where $$$e^{j\theta_{2}(\vec{x})}$$$ is a true solution for each voxel. DixonCGAN was implemented with a U-Net generator3-6 paired with a PatchGAN having the 70x70 receptive field.3,7 We trained our model for 100 epochs using a loss model with a cross-entropy objective and an adaptive moment estimation optimizer (mini-batch=30, initial learning rate=0.0002, and momentum=0.5). After training, binary-maps were generated from test images, then phase-difference maps ($$$e^{j\theta(\vec{x})}$$$) were composed by selecting a real solution between $$$e^{j\theta_{1}(\vec{x})}$$$ and $$$e^{j\theta_{2}(\vec{x})}$$$ for each voxel referring to generated binary-maps. Then, the estimated $$$e^{j\theta(\vec{x})}$$$ was removed from $$$S_{2}(\vec{x})$$$ (Fig.1).
(2) Error-correction: The binary-map generated by DixonCGAN may include CGAN translation errors, leading to incorrect solutions between $$$e^{j\theta_{1}(\vec{x})}$$$ and $$$e^{j\theta_{2}(\vec{x})}$$$ for some voxels. In this work, these errors were corrected by applying phase-smoothing filters for the translation error recovery under the assumption that the translation errors are localized and $$$e^{j\theta(\vec{x})}$$$ is spatially smooth.
(3) The final water and fat separation: After translation errors are corrected, water-only and fat-only images can be reconstructed from $$$S_{1}(\vec{x})$$$ and $$$S'_{2}(\vec{x})$$$ with a direct arithmetic operation (Fig.1).
RESULTS
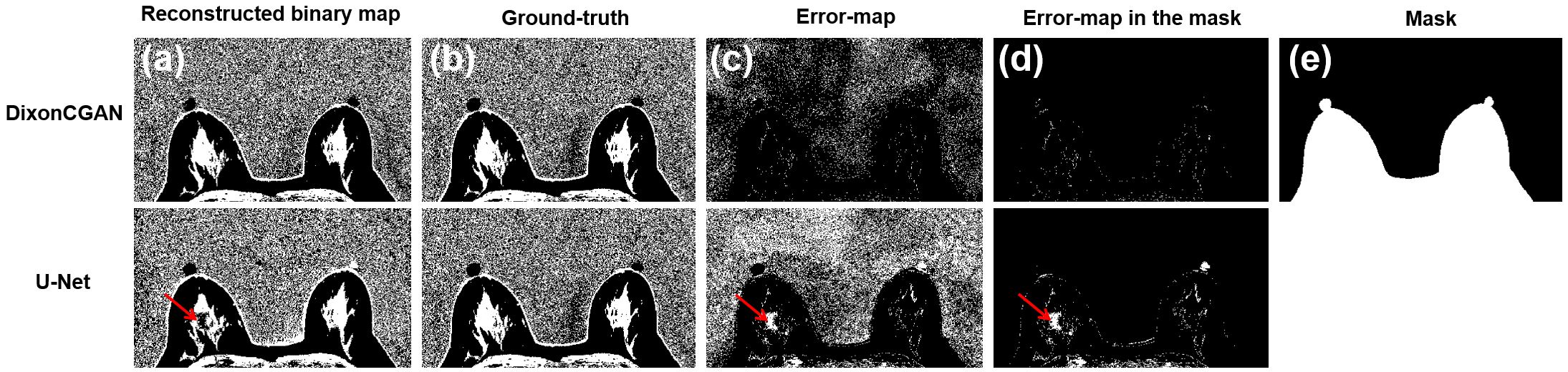
The DixonCGAN framework was implemented on a NVIDIA DGX-1 system with a 32GB Tesla V100 GPU (NVIDIA, Santa Clara, CA, USA), and trained with 3,899 sets (3,675 sets for training and 224 sets for validation) of images from 53 patients. All the images were acquired from breast cancer patients and on a 3T MRI scanner (GE Healthcare, Waukesha, WI, USA). Dixon images were acquired with a 3D fast spoiled gradient-echo two-point Dixon pulse sequence8 (TE1/TE2/TR=2.0/3.7/8.3ms, NxxNyxNzxNDCE=512x512x102x5, NFExNPE1xNPE2=480x384x102, slice-thickness/slice-gap=2/0mm, FOV=30x30x22.4cm, RBW=±250kHz, and scan-time=8min 50secs).Water and fat dominancy maps were separately reconstructed using DixonCGAN and U-Net.6 The performance of both models was compared in Fig.2. DixonCGAN using two paired networks was able to reconstruct binary-maps with improved global and local details compared to U-Net. The U-Net was trained with the same training parameters. The estimation accuracy of DixonCGAN and U-Net measured at the entire map (Fig.2.(c)) was 88% and 59% for each. When noise regions were excluded with a defined mask in Fig.2.(e), the estimation accuracy of DixonCGAN and U-Net was 98% and 87% respectively.
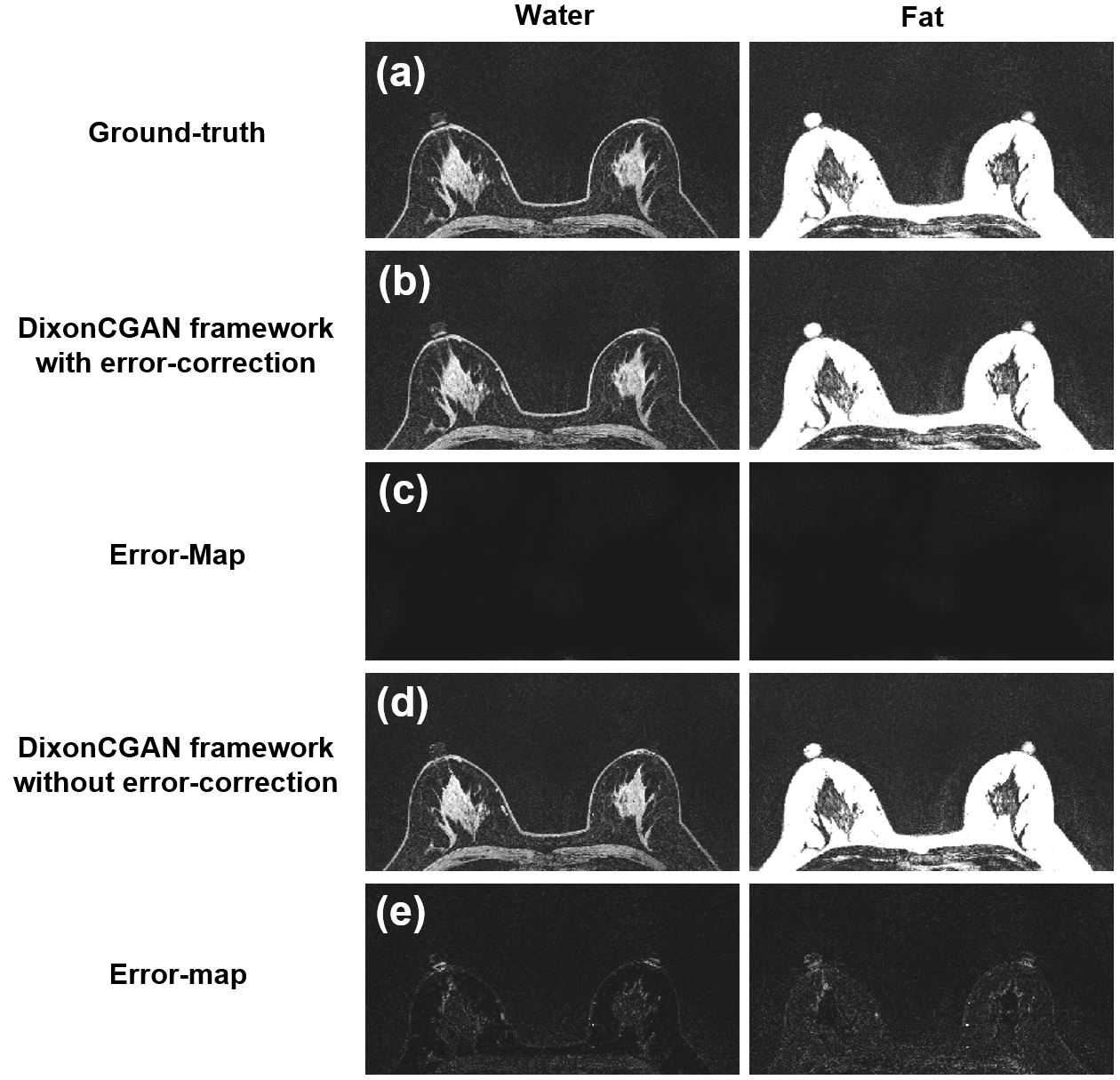
Water images were reconstructed with the DixonCGAN framework with and without the proposed deep-learning error recovery processes (Fig.3(b) and (d)). The binary map generated by DixonCGAN (Fig.2(a)) was used for both reconstructions. The corresponding error maps for both methods (Fig.3(c) and (e)) were compared to the ground-truth water-only and fat-only images (Fig.3(a)).8 The proposed error recovery processes were able to fix most of localized errors encountered in image translation as compared in Fig.3 (c) and (e).
The DixonCGAN framework was able to recover from localized deep-learning processing errors, which would lead to incorrect water and fat separation of some locally clustered pixels in some other proposed deep learning methods (Fig.4). Most of previous methods "directly" create water images as their network output, thus the proposed deep-learning error recovery is hard to be applied as phase information is already lost in their output water signals.
DISCUSSION AND CONCLUSION
The DixonCGAN framework performs water and fat separation in multiple stages with several important advantages. First, it preserves the phase information after phase-correction, thus enabling potential errors in the image domain transfer to be corrected by post-processing. Second, the performance of DixonCGAN is maximized by simplifying the output to a binary semantic segmentation for each pixel as water-dominant or fat-dominant. Third, the dynamic range of reconstructed water images is not degraded by the selected numerical precision of the final pixel-classification layer, and the limited hardware resources like GPU memory. Finally, the possibility of binary outcomes is equally balanced (roughly 50% and 50% including background noise regions), thus it can prevent deep-learning classification errors originating from unbalanced classes in training and test images.Acknowledgements
No acknowledgement found.References
1. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, and Bengio Y. Generative adversarial networks. In Advances in Neural Information Processing Systems. 2014:2672-2680.
2. Mirza M and Osindero S. Conditional generative adversarial nets. arXiv:1411.1784, 2014.
3. Isola P, Zhu JY, Zhou T, and Efros AA. Image-to-image translation with conditional adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2017.
4. Radford A, Metz L, and Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. International Conference on Machine Learning. 2015.
5. Ioffe S and Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. International Conference on Machine Learning. 2015.
6. Ronneberger O, Fischer P, and Brox T. U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention. 2015:234-241.
7. Li C and Wand M. Precomputed real-time texture synthesis with Markovian generative adversarial networks. European Conference on Computer Vision. 2016.
8. Ma J, Son JB, and Hazle JD. An improved region growing algorithm for phase correction in MRI. Magn Reson in Med. 2015;76:519-529.
Figures