0611
DeepRF: Designing an RF pulse using a self-learning machine1Department of Electrical and Computer Engineering, Seoul National University, Seoul, Korea, Republic of
Synopsis
Designing an RF pulse or developing a design rule requires a deep understanding of MR physics, and, therefore, is not easy. In this work, we demonstrate that an AI agent can self-learn the design strategy of an RF pulse and successfully generate a complex RF pulse (adiabatic RF) that satisfies given design criteria. The machine-designed pulse has a substantially different shape but shows performance comparable to the conventional adiabatic pulse.
Introduction
In MRI, several types of RF that have different purposes (e.g., SLR, adiabatic, spin-lock) have been developed. Designing these pulses or developing the design rules requires a deep understanding of MR physics, and, therefore, is not easy. Recent advances in deep reinforcement learning (DRL) have demonstrated that self-learning enables an artificial intelligence (AI) agent to master complex games (e.g., Go and StarCraft) by repetitively playing self-matches1-3. Using a similar approach, Shin et al. recently demonstrated that an AI agent can design a multiband SLR RF pulse4. In this work, we further investigate the idea of machine-designed RF and demonstrate that an AI agent successfully designs a more complex RF pulse (adiabatic RF) that satisfies given design criteria. Different from Shin’s work, which finds the optimum binary combination, the new task is to determine RF amplitude and phase with no specific constraint (e.g., no SLR transformation). Therefore, it is substantially more challenging. We named this novel design method as “DeepRF”.Methods
A non-selective inversion RF pulse that has immunity to B1+ inhomogeneity is designed.[Hyperbolic secant RF] For a conventional adiabatic pulse, a hyperbolic secant (HS) pulse5 is designed with the coverage of B1 from 0.1 to 2.0 and off-resonance (Δω0) from -100 Hz to 100 Hz6. After optimization, the parameters were set to be β = 4000 rad/sec, μ = 2.0, duration = 8 ms, and maximum amplitude = 0.2 Gauss.
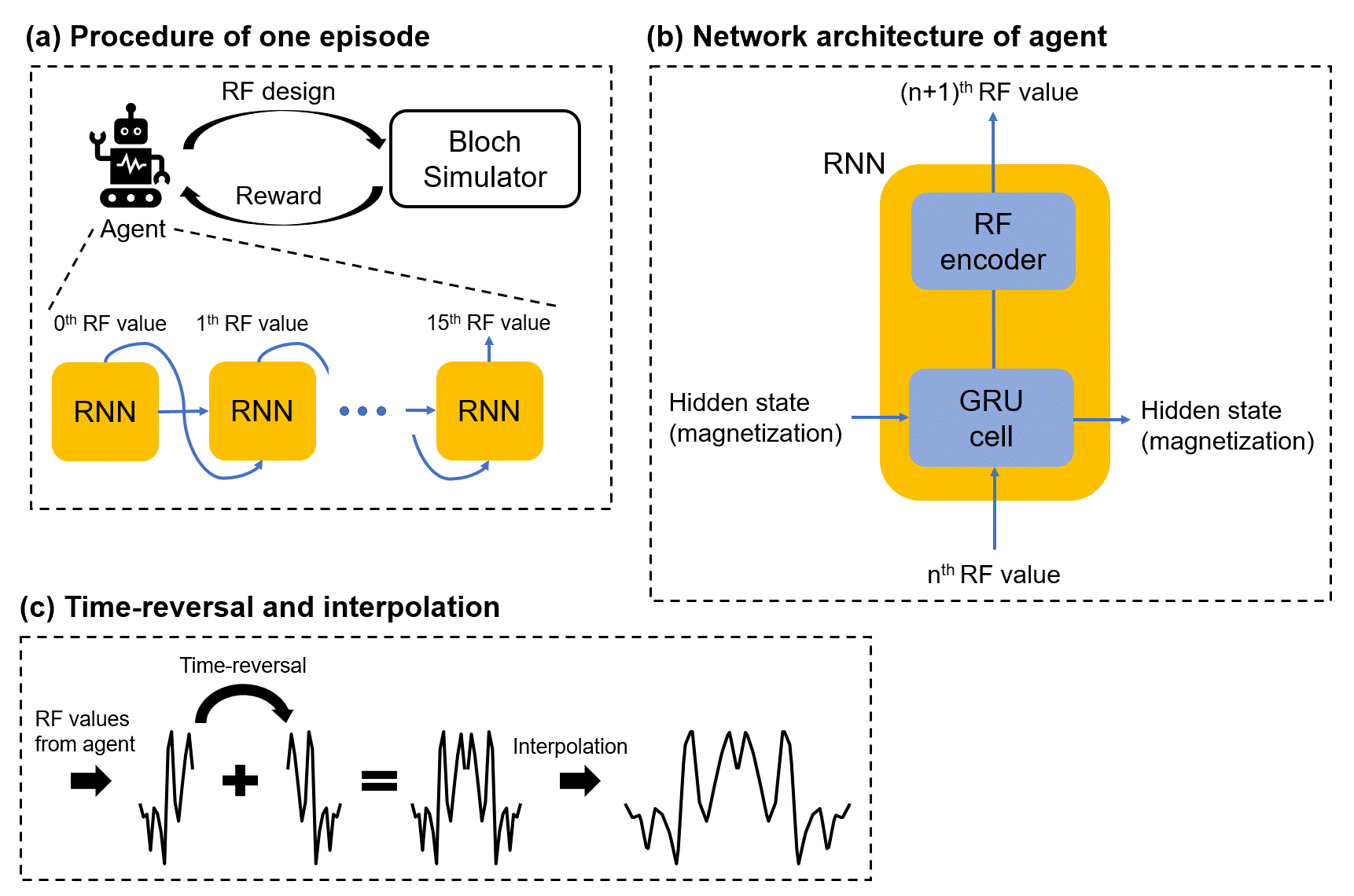
[Machine-designed RF] We utilized DRL7 to self-learn an RF design by trial and error. In DRL, a neural-network agent performs a series of actions and receives a reward that corresponds to the actions. This process is repeated so that the agent finds the optimal series of actions that maximize the reward. In our design, the agent determines a series of amplitude and phase values to generate an RF pulse (Fig.1a). Then, a Bloch simulator evaluates the performance of the pulse and returns a reward to the agent. The reward is calculated as follows:$$1/(1+\frac{1}{NM}\sum_{B_1}\sum_{\triangle\omega_0}M_z(RF,B_1,\triangle\omega_0))^2$$where N (= 50) and M (= 20) refer to the numbers of B1 and Δω0, respectively, and Mz is the longitudinal magnetization. The same B1 and Δω0 ranges as in the HS pulse are applied.
For our agent, a recurrent neural network (RNN)8, which gets the previous RF value and current magnetization as the inputs and determines the next RF value (amplitude and phase) as the output, is utilized (Fig.1b). The use of RNN is important because the magnetization is determined not only by the current RF input but also by the previous magnetization (a hidden state). The recurrent memory module of RNN allows the agent to understand the cumulative effect of the applied RF.
To reduce the degree of freedom, the agent generates 16 RF values, which correspond to the former half of an RF pulse. Then, the latter half is determined by a time-reversal version of the former half, generating a mirrored magnetization behavior. The final 32 complex-valued time points are linearly interpolated to 128-time points (Fig.1c).
The process of generating and evaluating RF is continued until no better design is found for 2000 episodes (1 episode = 1 RF pulse). DeepRF had the same duration and maximum amplitude limit as the HS pulse.
[Experiments] DeepRF and HS pulses were evaluated in a phantom (Fig.3a). A z-gradient (= 0.23 mT/m) was applied to introduce off-resonance. A sagittal plane was imaged at the nulling time (T1 = 100 ms, TI = 69.4 ms and TR = 600 ms). The scan was repeated while scaling the reference voltage (= 0.5:0.1:1.7) to acquire the inversion efficiency profile. The profile was calculated by averaging central 80 lines normalized by a reference scan (Fig.3b). For comparison, computer-simulated profiles were generated.
Results
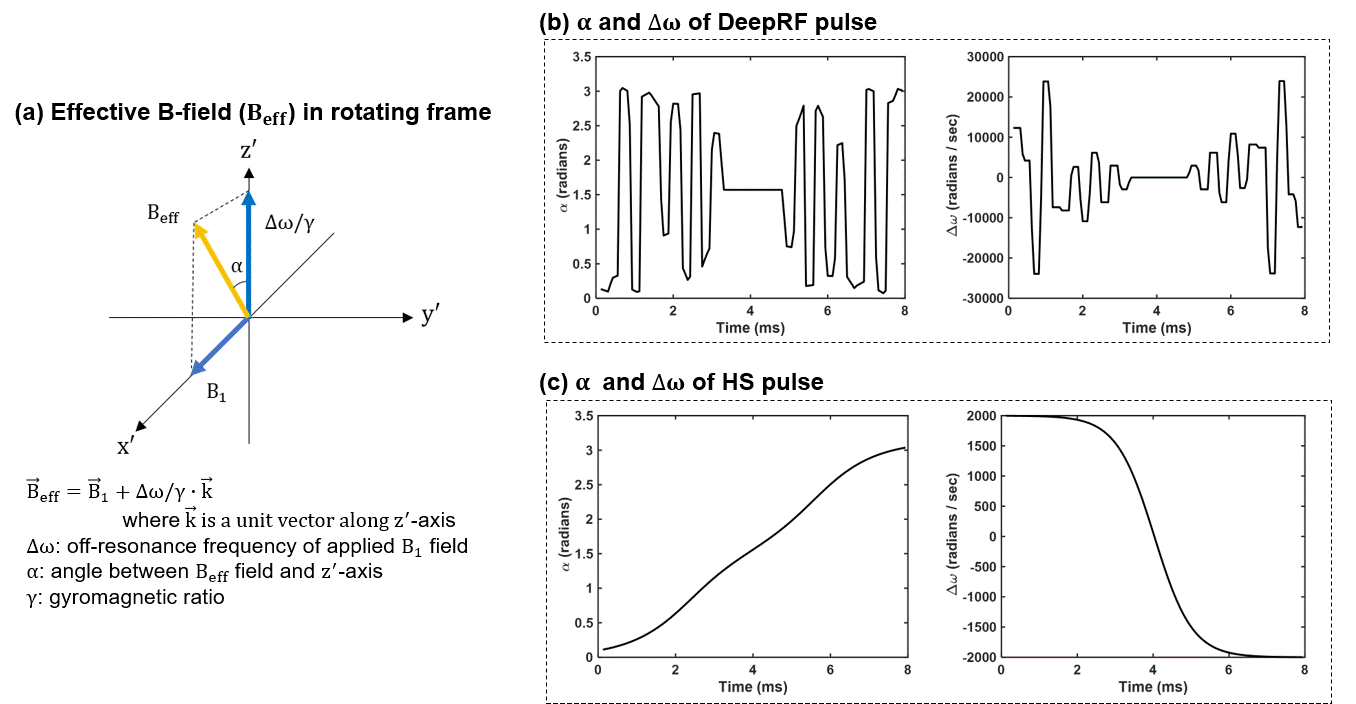
Figure 2 plots reward over episodes with a few example pulses. The final DeepRF pulse and HS pulse are shown in Figure 3c,d. The inversion efficiency plots of the simulation and experiment are presented in Fig 3e-h, showing good matches between the simulation and experiment. The DeepRF pulse has a smaller SAR (79% of HS) and lower peak amplitude (74% of HS). However, the inversion efficiency is degraded in low (< 0.4) and high (> 1.8) B1. A few examples of spin behaviors during the pulse duration are plotted for different B1 (0.7, 1.2, and 1.7) and Δω0 (-100, 0, and 100 Hz) (Fig.4). Interestingly, the spin behaviors of DeepRF roughly are similar to the HS pulse when the B1 scale is 0.7. However, it deviates for the higher B1 scales, showing complex rapid motions. Furthermore, the effective field9 of DeepRF demonstrates rapid changes in both α and Δω, revealing a substantially different behavior to the well-known adiabatic principle (Fig.5)10.Discussion and Conclusions
In this study, we proposed a novel RF design method, DeepRF, that utilized DRL to self-learn an RF design strategy. We demonstrated that DeepRF designs an inversion pulse robust to B1 and off-resonance and suggested evidence for a different inversion pathway that is difficult to be predicted in the conventional adiabatic RF design. The current DeepRF pulse is limited to a non-selective inversion but the method can be extended to a slice-selective RF pulse.Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (NRF-2018R1A2B3008445), the Brain Korea 21 Plus Project in 2019, and Samsung Research Funding & Incubation Center of Samsung Electronics under Project Number SRFC-IT1801-09.References
[1] Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of go without human knowledge. Nature. 2017;550(7676):354.
[2] Vinyals O, Babuschkin I, Czarnecki WM, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019.
[3] OpenAI. OpenAI Five. June 25, 2018. https://blog.openai.com/openai-five.
[4] Shin D, Ji S, Lee D, et al. Deep reinforcement learning designed RF pulse. In Proceedings of the 27th Annual Meeting of ISMRM, Montreal, Canada, 2019.
[5] Silver MS, Joseph RI, Hoult DI. Highly selective π/2 and π pulse generation. Journal of Magnetic Resonance. 1984;59(2):347-51.
[6] Stockmann JP, Wald LL. In vivo B0 field shimming methods for MRI at 7 T. NeuroImage. 2018;168:71-87.
[7] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms. arXiv. 2017;1707.06347.
[8] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv. 2014;1406.1078.
[9] Tannús A, Garwood M. Adiabatic pulses. NMR in Biomedicine. 1997;10(8):423-34.
[10] Abragam A. The principles of nuclear magnetism (No. 32). Oxford, UK: Oxford university press; 1961.
Figures