0306
Improving the performance of non-enhanced MR for predicting the grade of hepatocellular carcinoma by transfer learning1School of Medical Information Engineering, Guangzhou University of Chinese Medicine, Guangzhou, China, 2Department of Radiology, Guangdong General Hospital, Guangzhou, China
Synopsis
Contrast agent has several limitations in clinical practice, and the diagnostic performance of non-enhanced MR for lesion characterization should be thoroughly exploited. Inspired by the work of cross-modal learning framework,we propose a deeply supervised cross-modal transfer learning method to remarkably improve the malignancy characterization of HCC in non-enhanced MR, in which the cross-modal relationship between the non-enhanced modal and contrast-enhanced modal is explicitly learned and subsequently transferred to another CNN model for improving the characterization performance of non-enhanced MR. The visualization method Grad-CAM is also applied to verify the effectiveness of the proposed cross-modal transfer learning model.
Introduction
In clinical practice, medical imaging with contrast agent administration has played a significant role in lesion diagnosis and characterization, especially for the malignancy characterization of HCC1. However, contrast agent is reported to be associated with acute renal failure, especially for patients with pre-existing renal failure2. More importantly, the diagnostic performance of contrast enhancement may be limited due to the overlap of enhancement patterns for different types of malignancies. Inspired by the cross-modal learning framework in computer vision3, the cross-modal relationship between the non-enhanced modal and contrast-enhanced modal can be explicitly learned and transferred to the CNN model for improving the performance of lesion characterization in non-enhancement images. In this work, we propose a deeply supervised cross-modal transfer learning method to remarkably improve the malignancy characterization of HCC in non-enhanced MR.Methods
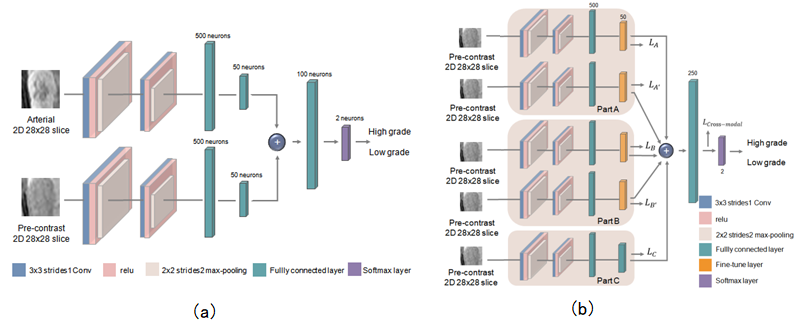
One hundred and twelve consecutive patients with one hundred and seventeen hisotologically proven HCCs from October 2012 to October 2018 were included in the present study (101 male, 11 female, aged 51.09±11.53 years ranged 27 to 79 years). Gd-DTPA-enhanced MR imaging were performed with a 3.0T MR scanner (Signa Excite HD 3.0T, GE Healthcare, Milwaukee, WI, USA). A deep learning network with Convolutional Neural Network (CNN) was first pre-trained to learn the cross-modal relationship between the non-enhanced modal and contrast-enhanced modal (Figure 1a), and then the pre-trained parameters were transferred to a second deep learning model with CNN based only on non-enhanced MR for malignancy characterization of HCC (Figure 1b). Furthermore, a deeply supervised subnetwork4 was designed for the pre-contrast classification network. The data set was randomly split into three parts: the pre-train set (35 HCCs), the pre-contrast training set (42 HCCs) and the fixed test set (40 HCCs). The training and testing were repeatedly performed five times. Receiver operating characteristic curve (ROC) and area under the curve (AUC) were used to assess the characterization performance. The visualization method Grad-CAM5 was applied for quantitative analysis in order to understand the characteristics of the proposed cross-modal transfer learning model. The output probability of the deep learning model in the fixed test set for HCC differentiation was assessed by the independent student's t-test. P<0.05 was considered statistically significant.Results
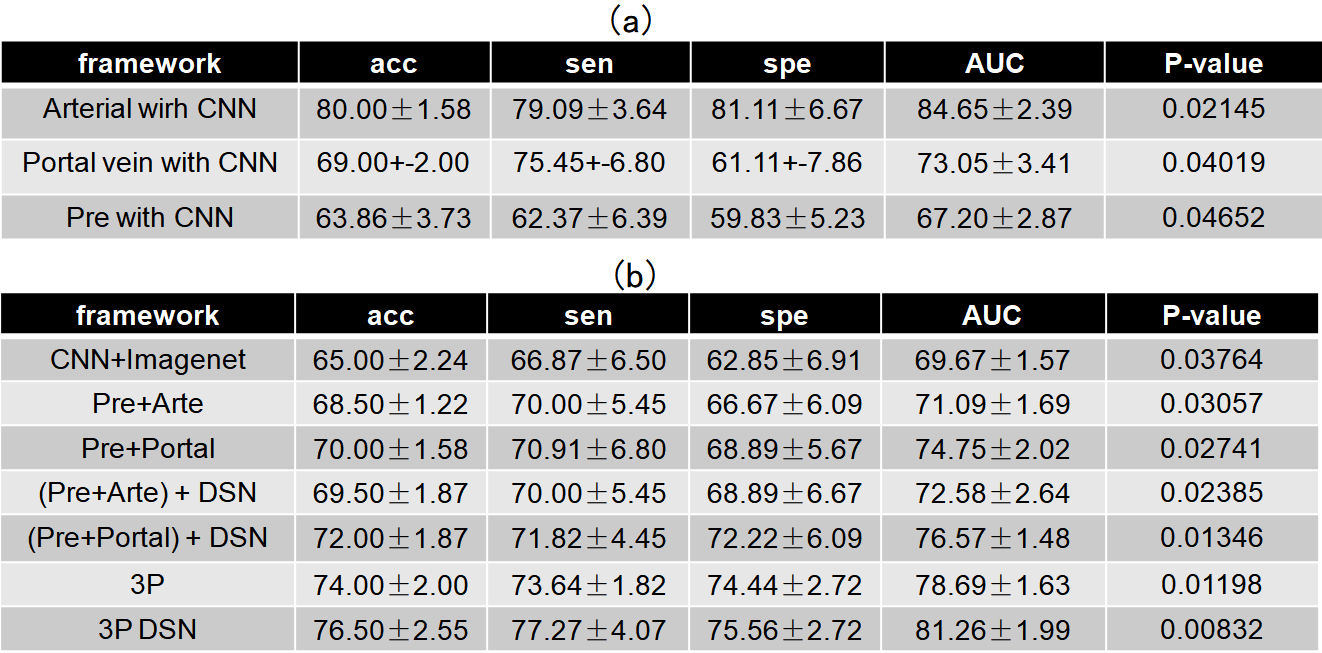
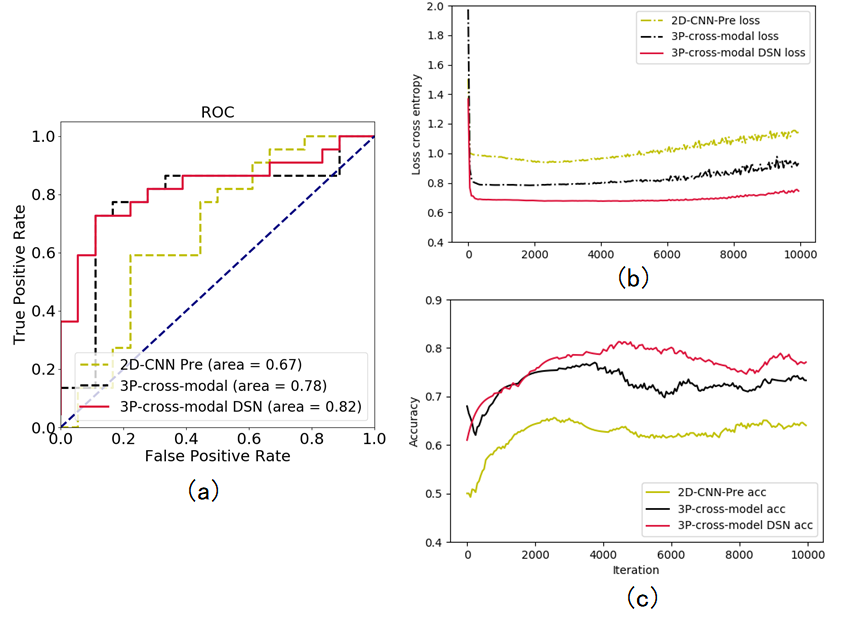
Table 1a shows the characterization performance of different methods for malignancy characterization of HCC using the 42 HCCs for pre-contrast training and the 40 HCCs for independent testing. It can be found that the arterial phase yielded best performance with the mean accuracy of 0.80, and followed by portal vein phase with the mean accuracy of 0.69 and pre-contrast phase with the mean accuracy of 0.64 for malignancy characterization of HCC. Table 1b shows the comparison results of different pre-train strategies using the 35 HCCs for pre-training, 42 HCCs for pre-contrast training and the 40 HCCs for independent testing. It can be clearly found that pre-train methods all improve the performance of pre-contrast classification. By comparison, the cross-modal pre-train method yielded much better performance than that of the pre-train by ImageNet (mean accuracy of 0.65). Furthermore, the pre-train by the cross-modal from the three phases (mean accuracy of 0.74)including pre-contrast, arterial and portal vein obtained much better results than those of the pre-train by the cross-modal from two phases (mean accuracies of 0.69 and 0.70, respectively). Finally, the proposed deeply supervised cross-modal learning model yielded best performance for malignancy characterization of HCC(mean accuracy of 0.77 in Table 1b) on pre-contrast, which was very close to the performance of arterial phase (mean accuracy of 0.80 in Table 1a). In addition, the ROC curves, loss curves and accuracy curves of different models were also plotted in Figure 2. In Figure 3, we provide a set of feature map and the important regions illustrated by the Grad-CAM. For CNN baseline in pre-contrast phase, the tumor border is the important region contributed for the prediction as shown in Figure 3(b). However, for the subnetwork A, B and C, more salient regions are reported to be important for the prediction as shown in Figure 3(c-e).Discussion
To our best knowledge, this study might be the first work to demonstrate the significance of transfer the relationship between pre-contrast and enhanced patterns for improving the performance of lesion characterization in the pre-contrast. Furthermore, from the visualization results of Grad-CAM (Figure 3), it can be found that the transfer of the relationship between pre-contrast and arterial phase and the transfer of the relationship between pre-contrast and portal vein phase can make the conventional CNN baseline in pre-contrast to exploit more information in the target regions. Subsequently, the proposed DSN method aggregates and utilizes the given features from different subnetworks for better predictions. The visualization results verify the effectiveness of the proposed cross-modal transfer learning model. More significantly, from the visualization, we can understand how the network extracts more features with the supervision of cross-modal transfer learning in the pre-contrast phase. We believe that it might be extremely helpful and significant for clinical interpretation.Conclusion
A deeply supervised cross-modal transfer learning method was investigated to remarkably improve the malignancy characterization of HCC in non-enhanced MR. The visualization method Grad-CAM demonstrated the effectiveness of the proposed cross-modal transfer learning model.Acknowledgements
This research is supported by the grant from National Natural Science Foundation of China (NSFC: 81771920).References
[1] Zhou W, Zhang L, Wang K, et al. Malignancy Characterization of Hepatocellular Carcinomas based on Texture Analysis of Contrast-enhanced MR Images. J MagnReson Imaging 2017;45(5):1476-1484.
[2] Andreucci M, Solomon R, Tasanarong A. Side effects of radiographics contrast media: pathogenesisi, risk factors and prevention. Biomed. Res. Int. 2014;741018.
[3] Xu D, Ouyang W, Ricci E, Wang X, Sebe N. Learning Cross-Modal Deep Representations for Robust Pedestrian Detection. Proc. IEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR) 2017: 4236 - 4244.
[4] Lee CY, Xie S, Gallagher P, et al. Deeply-Supervised Nets. Eprint Arxiv, 2014:562-570.
[5]Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-Cam: Visualization explanations from deep networks via gradient-based localization. Proc. IEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR) 2017: 618-626.
Figures