0250
Task-Based UltraFast MRI: Simultaneous Image Reconstruction and Tissue Segmentation1Department of Radiology and Biomedical Imaging, University of California, San Francisco, San Francisco, CA, United States, 2EECS, University of California, Berkeley, Berkeley, CA, United States, 3Department of Bioengineering, University of California, Berkeley, Berkeley, CA, United States
Synopsis
We propose a novel task based deep learning framework for simultaneous MRI reconstruction and segmentation. On a dataset of retrospectively undersampled knee-DESS volumes we demonstrate that irrespective of ultra-high acceleration factors (i.e. 48×) a multitask 3D encoder-decoder is capable of reconstructing with high fidelity the knee MRI, accurately segment cartilaginous and meniscal tissues and reliably provide cartilage thickness. Our multitask solution outperforms two other methods: a compressed sensing reconstruction step, followed by a deep learning-based tissue segmentation. The other method comprises a cascade of two convolutional neural networks that sequentially perform image reconstruction and segmentation.
Introduction
Long MRI scan times lead to low patient throughput, problems with patient comfort, artifacts from patient motion, and high exam costs1. Many methods have been proposed to accelerate MRI. However, there is a need for greater systematic evaluation of the impact of accelerated-MRI on the extraction of clinically relevant metrics. Furthermore, fast image acquisition and accurate image post-processing are typically considered as two independent problems. In this study, we propose a multi-task deep learning approach capable of simultaneously reconstructing accelerated MRI (up to 48×AF) and segmenting tissues of interest. As example, we apply our method on retrospectively accelerated-knee MRI, where we segment tibial, femoral and patellar cartilage and menisci. Finally, we show that irrespective of the AF, our method can reliably measure knee cartilage thickness.Methods
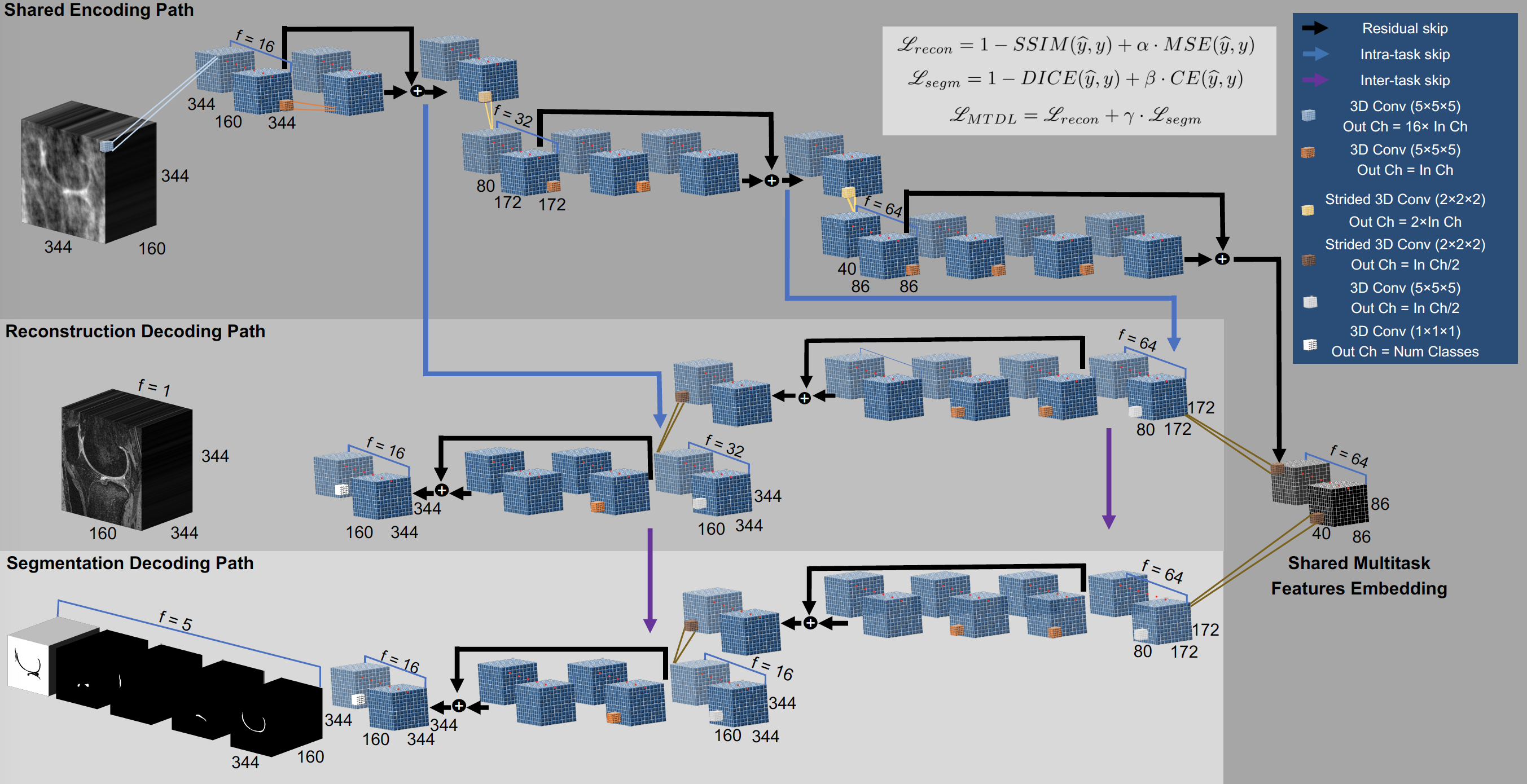
172 3D Dual-Echo-Steady-State (DESS) knee volumes (TE 4.7 ms, TR 16.2 ms, field of view 14 cm, matrix 307 × 384, slice thickness 0.7 mm, and bandwidth 185 kHz) were used to evaluate the acceleration methods. Volumes were Fourier Transformed to generate synthetic k-space data and retrospectively undersampled by using a variable-density Poisson disk undersampling pattern2 with AF=[1.5, 2, 3, 4, 6, 12, 24, 36, 48] along the encoding phase directions. To simulate a compressed sensing acquisition and reconstruction (L1-CS)3, all the images were reconstructed via constrained optimization with an L1-Wavelet regularization using a primal-dual hybrid gradient algorithm4,5. After image reconstruction, cartilage and meniscus were automatically segmented using a 3D V-Net6 on all the L1-CS knee volumes. We refer to the cascade of L1-CS reconstruction and V-Net segmentation as “CS-DL”. The same undersampled dataset was also reconstructed and subsequently segmented using two identical and independent V-Nets: one trained to denoise images obtained from zero-filled Inverse-Fast Fourier Transform of the undersampled data and one trained to segment the output of the first network. We refer to this cascade of V-Nets with the term “cascadeRS”. To devise a task-based MRI reconstruction framework we propose a multitask deep learning “MTDL” approach. Fig.1 is descriptive of a novel deep neural network architecture we propose. Overall the network consumes a zero-filled k-space under-sampled MRI volume, and outputs a reconstructed MRI in addition to the tibial, femoral, patellar cartilage segmentation maps. The network has the structure of a 3D fully convolutional encoder-decoder, with an encoding path shared between tasks. Once a common embedded representation of both tasks is encoded, the network branches into two bottom level paths where task specific feature representations are learnt. As additional novel element, the network presents skip connections between the encoding and the image reconstruction paths, as well between the reconstruction and the segmentation paths. The reasoning behind such architectural design decision lies in the quality of the features that are passed through the network’s encoding-decoding paths via skip-connections: the features available at the encoding path suffer from under-sampled k-space artefacts, which, especially at high acceleration factors, result in a severe loss of finer details, which are crucial for tissue segmentation. On the contrary, the features available in the down sampling path are instrumental for reconstructing a high-resolution MRI, they provide a good initial solution, resulting in a faster convergence compared to a gaussian noise like initialization. The flow of features between the decoding paths, provides the segmentation branch with features representative of finer details.Results
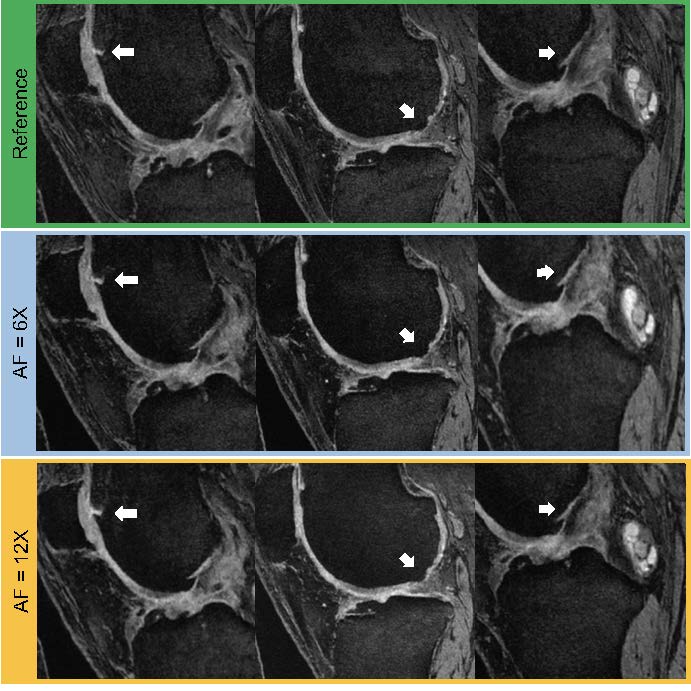
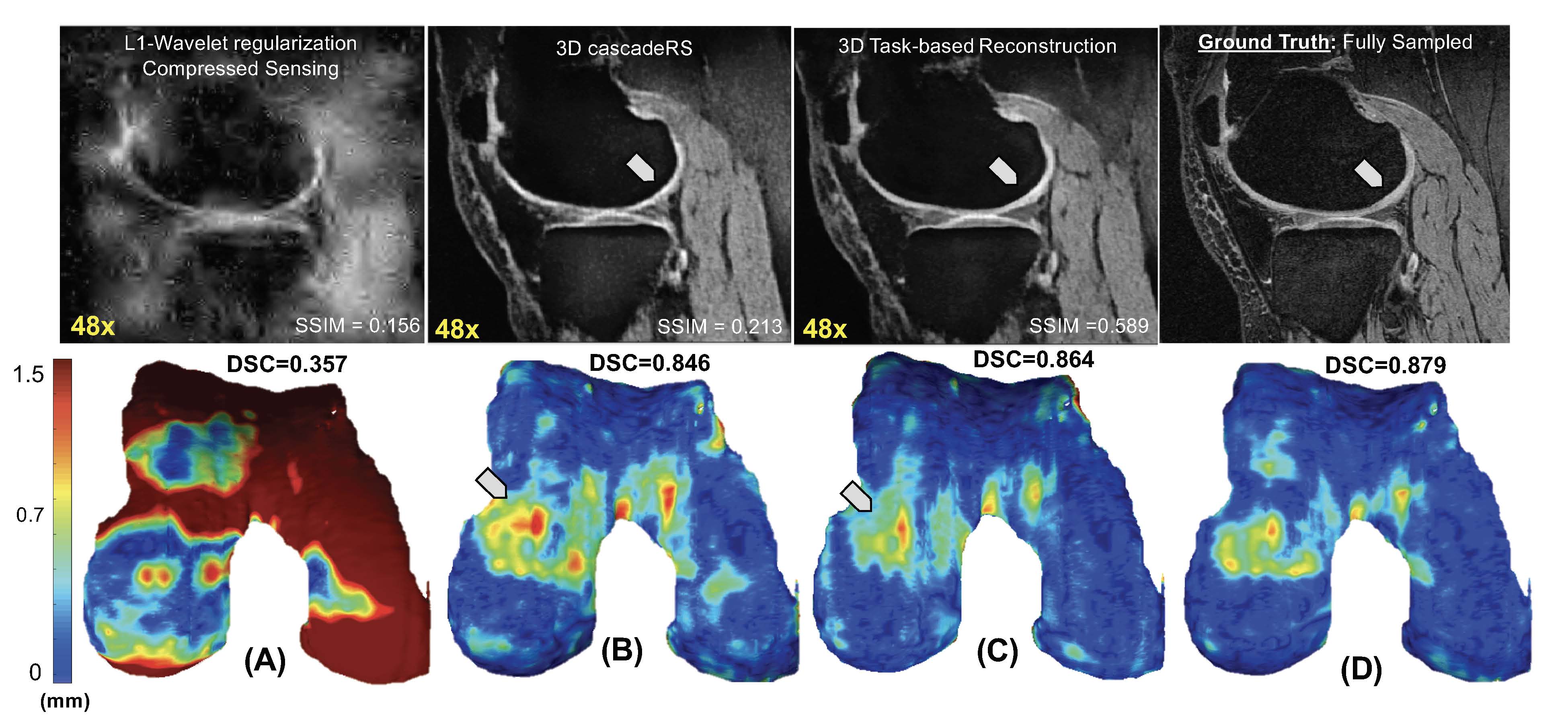
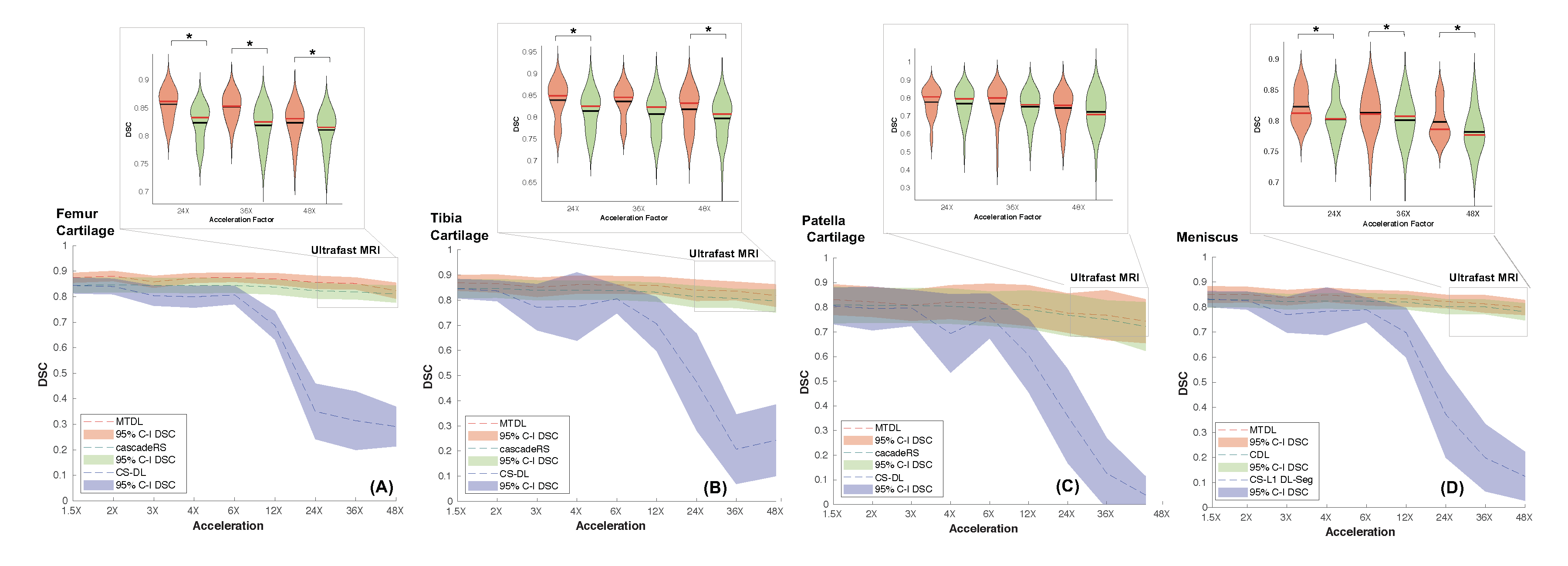
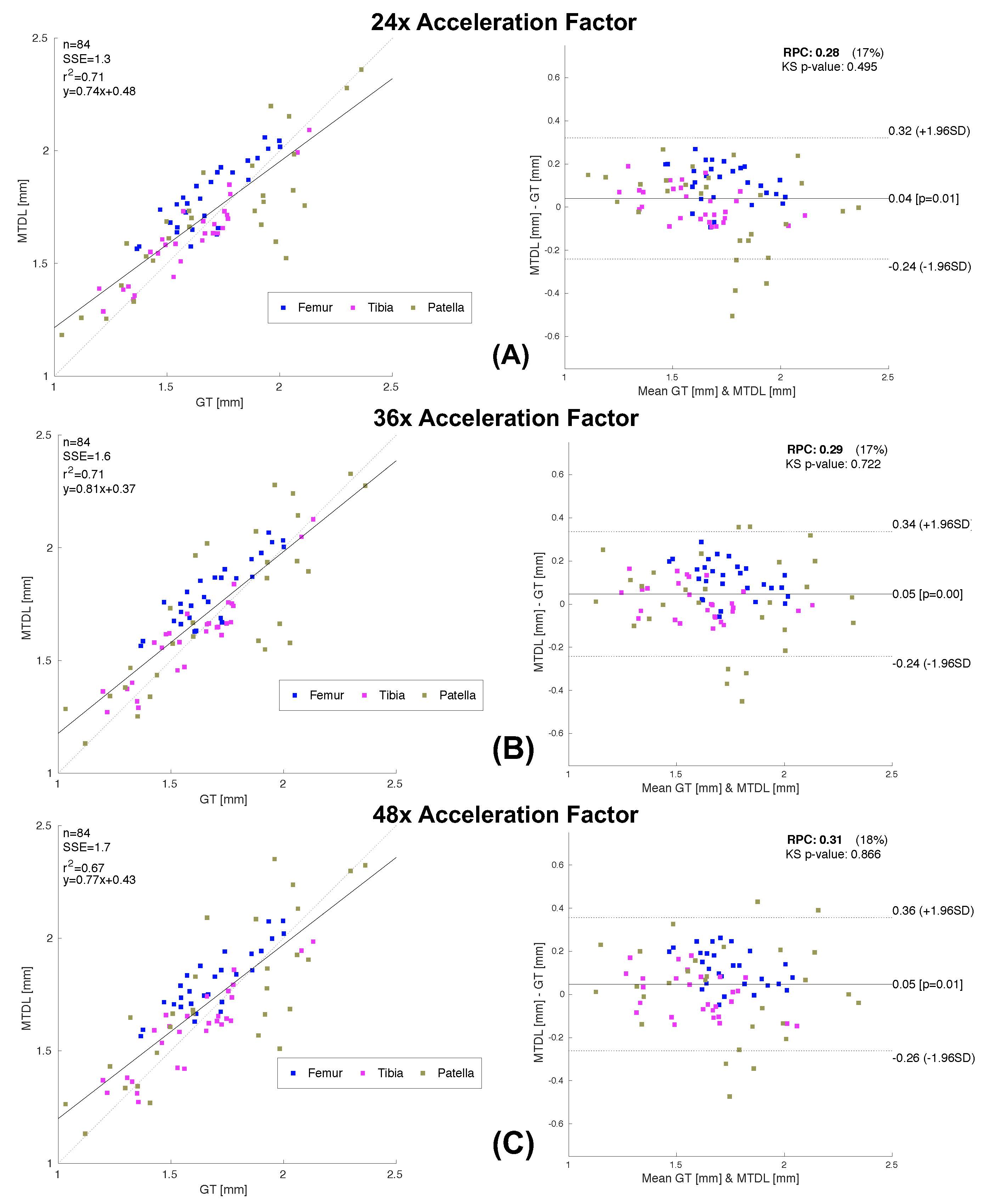
We tested our methods on a test-set of 28 volumes. Fig.2 is exemplary of the performance of MTDL on the reconstruction task at 6× and 12× AF. Fig.3 shows the reconstruction and corresponding cartilage segmentation and cartilage thickness maps obtained using the compressed sensing algorithm (A), the reconstruction portion of cascadeRS (B), and the output of the reconstruction branch of MTDL (C) on a 48× AF MRI. Fig.4-bottom depicts averages and 95C-I Dice Score Coefficient (DSC) as function of all the AF for the three methods. Up to AF 6×, all the three reconstruction techniques provide good enough quality to achieve a good tissue segmentation with DSC of: femur 0.81±0.04, 0.84±0.03, 0.87±0.02; tibia 0.81±0.06, 0.84±0.04, 0.86±0.04; patella 0.76±0.09, 0.79±0.07, 0.81±0.08; menisci 0.79±0.05, 0.82±0.03, 0.83±0.03. Conversely, while cascadeRS and MTDL maintain high quality segmentation up to 48×; from AF 12×, CS-DL reveal a noticeably DSC drop: femur 0.69±0.05, 0.84±0.03, 0.87±0.02 tibia 0.70±0.11, 0.83±0.08, 0.86±0.03; patella 0.60±0.15, 0.79±0.08, 0.82±0.08; menisci 0.70±0.10, 0.82±0.03 and 0.84±0.03 respectively. Violin plots in Fig.4-top report the outcome of a t-test conducted to analyse whether MTDL significantly outperforms cascadeRS at ultra-high AF. Fig.5 shows a Bland-Altman plot where the cartilage thickness measured on the manually annotated segmentation, is compared against the thickness computed on the automatically MTDL segmentation, showing that there is high correlation, no bias and no significant difference between the two measurements.Discussion and Conclusions
In this retrospective study, we show that the data-driven nature of DL based solutions have the potential to make task-based ultraFast MRI feasible. Our multi-task optimization framework proved to be a convincing solution, it uses fewer trainable parameters than conventional cascades of Deep Learning approaches. This was reinforced by a statistically significant improved performance over a commonly used compressed sensing reconstruction technique. Our future work will involve testing the framework on real raw data, as well as further investigate the potential application of ultrafast MRI.Acknowledgements
This project was supported by R00AR070902 (VP), R61AR073552 (SM/VP) from the National Institute of Arthritis and Musculoskeletal and Skin Diseases, National Institutes of Health, (NIH-NIAMS).References
1 Zbontar, J., et al. "fastmri: An open dataset and benchmarks for accelerated mri." arXiv preprint arXiv:1811.08839 (2018).
2 Lustig, M., et al, “Sparse MRI: The application of compressed sensing for rapid MR imaging,” Magn. Reson. Med., vol. 58, no. 6, pp. 1182–1195, Dec. 2007.
3 Hammernik, K., et al. "Learning a variational network for reconstruction of accelerated MRI data." Magnetic resonance in medicine 79.6 (2018): 3055-3071.
4 Bridson, R.. “Fast Poisson disk sampling in arbitrary dimensions.” SIGGRAPH sketches. 2007.
5 Chambolle, A., & Pock, T. (2011). A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of mathematical imaging and vision, 40(1), 120-145.
6 Tamir J, et al., “Parameter-free Parallel Imaging and Compressed Sensing”, Proc. Intl. Soc. Mag. Reson. Med. 26 (2018).
7. Milletari, F., et al. "V-net: Fully convolutional neural networks for volumetric medical image segmentation." 2016 Fourth International Conference on 3D Vision (3DV). IEEE, 2016.
Figures