0248
Quantitative T1 Mapping from Incoherently Undersampled MR Images Using Self-Attention Convolutional Neural Networks1Stanford University, Stanford, CA, United States, 2Radiology, University of California San Diego, La Jolla, CA, United States, 3Radiation Oncology, Stanford University, Stanford, CA, United States
Synopsis
The application of current quantitative MRI techniques is limited by the long scan time. In this study, we propose a deep learning strategy to derive quantitative T1 map and B1 map from two incoherently undersampled variable contrast images. Furthermore, radiofrequency field (B1) inhomogeneity is automatically corrected in the derived T1 map. The tasks are accomplished in two steps: joint reconstruction and parameter quantification, both employing self-attention convolutional neural networks. Significant reduction in data acquisition time has been successfully achieved, including an acceleration in variable contrast image acquisition caused by undersampling and a waiver of B1 map measurement.
INTRODUCTION
Currently, quantitative MRI is not widely adopted in clinical practice due to the long scan time required by the acquisition of variable contrast images. In this study, we propose a multi-step deep learning strategy to extract quantitative T1 map and B1 map from incoherently undersampled variable contrast images, which will significantly reduce data acquisition time. Furthermore, after the T1 mapping model is established, B1 inhomogeneity is automatically compensated for without measurement of B1 map. The strategy is mainly validated in cartilage MRI.METHODS
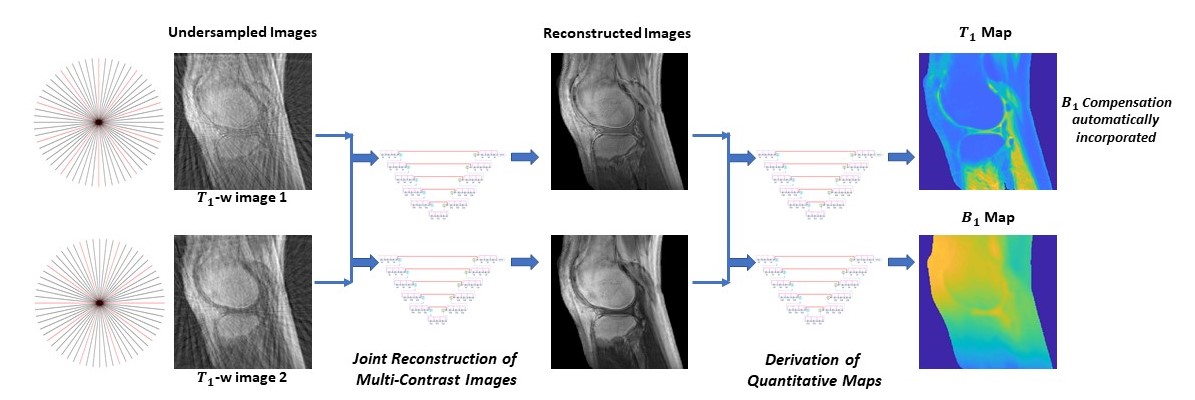
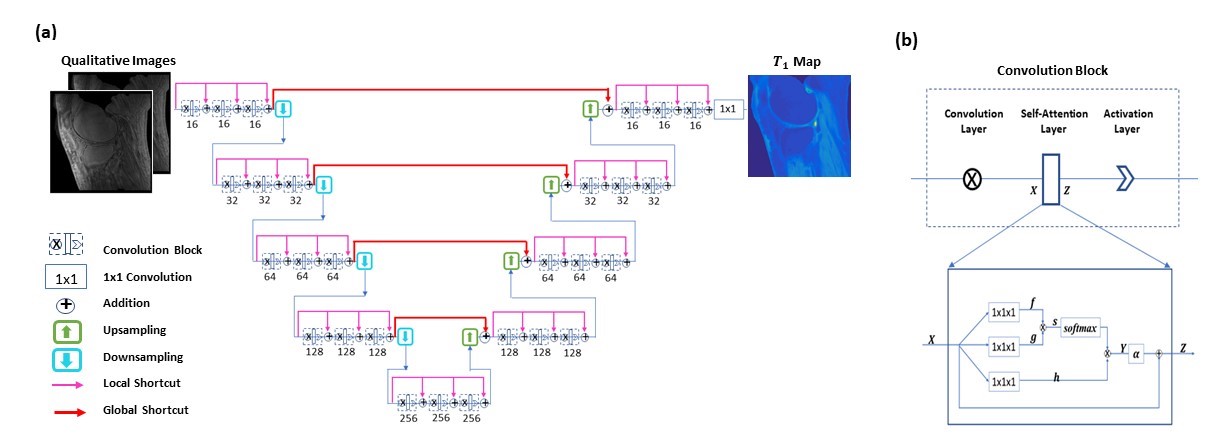
To provide mappings from incoherently undersampled variable contrast images to the corresponding T1 map and B1 map, convolutional neural networks are employed, where every ground truth T1 map is obtained from T1 weighted images (acquired using variable flip angle of 5°, 10°, 20°, and 30°) and a B1 map (measured using the actual flip angle method) 1. A multi-step deep learning-based approach is proposed for the task, as illustrated in Figure 1. First, multi-contrast images are jointly reconstructed from incoherently undersampled images using deep neural networks, in which data consistency enforcement is performed. Subsequently, the corresponding T1 map and B1map are derived from the reconstructed multi-contrast images using deep learning. Notice that in an established T1 mapping model, B1 compensation is automatically achieved without measurement of B1 map.A special convolutional neural network is constructed for joint reconstruction, T1 mapping, and B1 estimation 2. The network has a hierarchical architecture, composed of an encoder and a decoder. This enables feature extraction at various scales while enlarging the receptive field at the same time. A unique shortcut pattern is designed, where global shortcuts (that connect the encoder path and the decoder path) compensate for details lost in down-sampling, and local shortcuts (that forward the input to a hierarchical level of a single path to all subsequent convolutional blocks) facilitate residual learning. Attention mechanism is incorporated into the network to make efficient use of non-local information 3-5. Briefly, in self-attention, direct interactions are established between all voxels within a given image, and more attention is focused on regions that contain similar spatial information. In every convolutional block, a self-attention layer is integrated, where the self-attention map is derived by attending to all the positions in the feature map obtained in the previous convolutional layer. The value at a position of the attention map is determined by two factors. One is the relevance between the signal at the current position and that at other positions, defined by an embedded Gaussian function. The other is a representation of the feature value at the other position, given by a linear function. Here, weight matrices are identified by the model in training. The proposed network is shown in Figure 2.
Separate deep neural networks are trained for T1 mapping and B1 estimation. A total of 1,224 slice images from 51 subjects (including healthy volunteers and patients) are used for model training, and 120 images of 5 additional subjects are employed for model testing. The difference between the prediction and ground truth is backpropagated, and model parameters are updated using the Adam algorithm. This iterative procedure continues until convergence is reached.
RESULTS
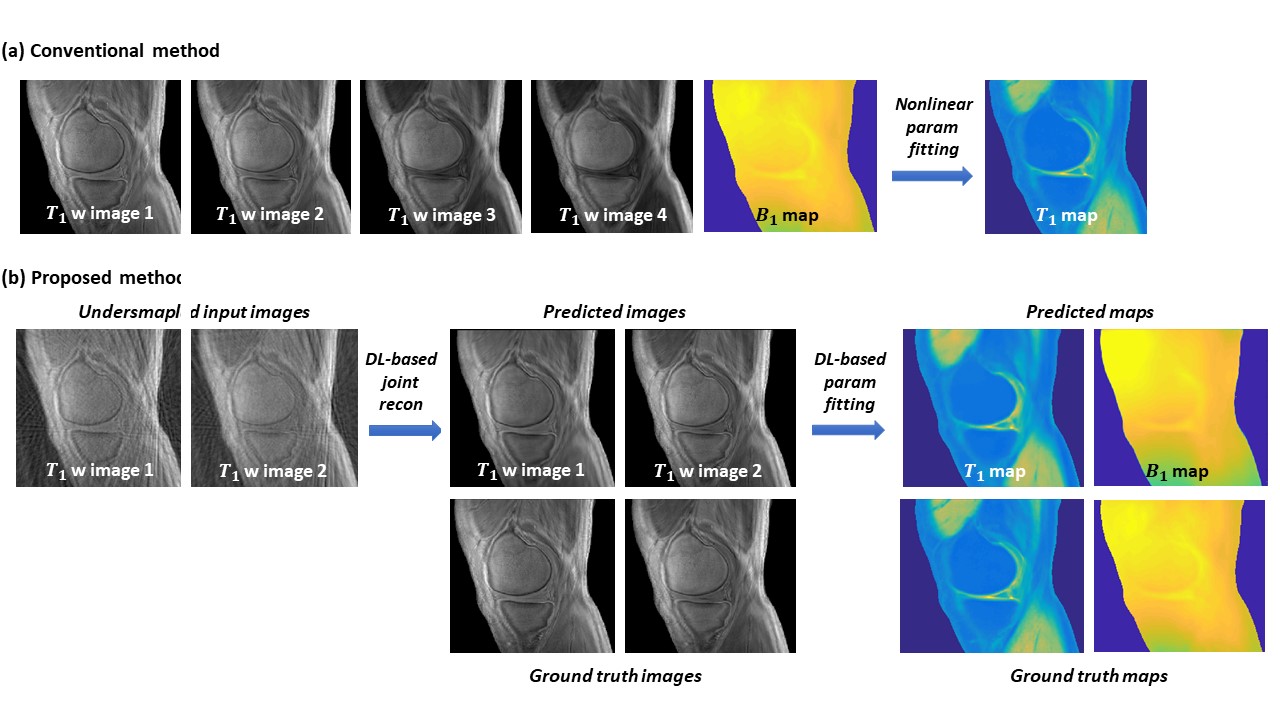
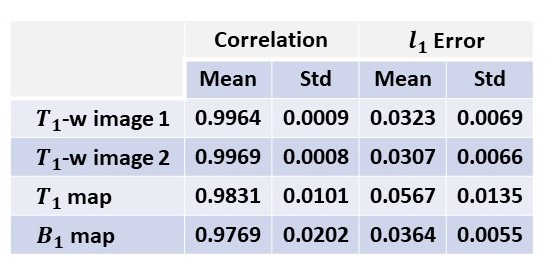
Using established models, two high-quality images (presumably acquired using 5° and 20° respectively) are jointly reconstructed from incoherently undersampled images with an acceleration factor of 6 achieved in each image. Subsequently, T1 map and B1 map are predicted from the two reconstructed images. The resultant images and maps are highly consistent to the ground truth, as shown in Figure 3. Compared to a conventional approach that takes 14min 25s, the data acquisition time in the proposed method is significantly reduced to 47.3 seconds, including a high degree of acceleration in multi-contrast image acquisition (with a factor of 12) as well as a complete waiver of map measurement (which saves 4min 57sec). The evaluation results using quantitative metrics are shown in Figure 4.DISCUSSION
The proposed multi-step quantitative parametric mapping solution is advantageous over the deep learning-based quantitative MRI approaches that provide an end-to-end mapping from undersampled images to quantitative maps. Obtaining reconstructed images provides an opportunity to seamlessly incorporate data consistency enhancement into quantitative parametric mapping. Moreover, this step enables B1 estimation from reconstructed images (contrarily, B1 map estimation from undersamapled images is very challenging due to the low quality of the input images). In parametric mapping from reconstructed images, deep learning is employed instead of conventional nonlinear fitting, which not only reduces data processing time, but also improves the robustness of prediction and enables automatic B1 compensation in T1 mapping.CONCLUSION
We present a new data-driven strategy to accelerate the acquisition of quantitative MRI. In the cartilage MRI study, a high degree of acceleration has been achieved in T1 mapping and B1 estimation with image fidelity well maintained.Acknowledgements
This research is partially supported by NIH/NCI (1R01 CA176553), NIH/NIAMS (1R01 AR068987), NIH/NINDS (1R01 NS092650).References
1. Y. J. Ma, W. Zhao, L. Wan, T. Guo, A. Searleman, H. Jang, et al., "Whole knee joint T1 values measured in vivo at 3T by combined 3D ultrashort echo time cones actual flip angle and variable flip angle methods," Magnetic resonance in medicine, vol. 81, pp. 1634-1644, 2019.
2. Y. Wu, Y. Ma, D. P. Capaldi, J. Liu, W. Zhao, J. Du, et al., "Incorporating prior knowledge via volumetric deep residual network to optimize the reconstruction of sparsely sampled MRI," Magnetic resonance imaging, 2019.
3. Wu, Y., Y. Ma, J. Liu, W. Zhao, J. Du et al., Self-attention convolutional neural network for improved MR image reconstruction. Information Sciences, 2019. 490: p. 317-328.
4. Vaswani, A., et al. Attention is all you need. in Advances in Neural Information Processing Systems. 2017.
5. Zhang, H., et al., Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
Figures