0247
Deep learning for the detection and differentiation of vertebral fracture1Department of Radiological Science, University of California, Irvine, CA, United States, 2Department of Radiology, E-Da Hospital and I-Shou University, Kaohsiung, Taiwan, 3Department of Radiology, Peking University Third Hospital, Beijing, China
Synopsis
This study investigated the value of deep learning for the detection and differential diagnosis of vertebral fracture. A model using ResNet50 was developed and tested in a separate dataset. The results were compared with the interpretation of an experienced radiologist. Our study noted that the analysis based on single vertebral body without inclusion of the soft tissue, the posterior elements, and the skipped lesions might be the reason why the radiologist’s reading was better than deep learning approach. For the identification of malignant fracture using whole images from training set, the prediction accuracy was only moderate, with rooms for improvement.
Introduction
The differentiation of benign and malignant vertebral fracture is necessary for a timely therapeutic planning. Clinical accurate diagnosis is difficult in elderly patients with no or minor trauma history. Imaging plays important roles for disease evaluation. Plain radiography has limitations. Although conventional MRI has been extensively used for accessing spinal lesions (1), the accurate differential diagnosis of benign fracture and malignant fracture remains challenging. Recently quantitative imaging methods, such as diffusion weighted imaging (DWI), have been investigated and showed their values (2, 3). Nevertheless, the method has not gained wide popularity due to technical and overlapping ADC values issues. In this study we investigated the potential value of deep learning approaches in the detection and differentiation of benign and malignant vertebral fracture.Methods
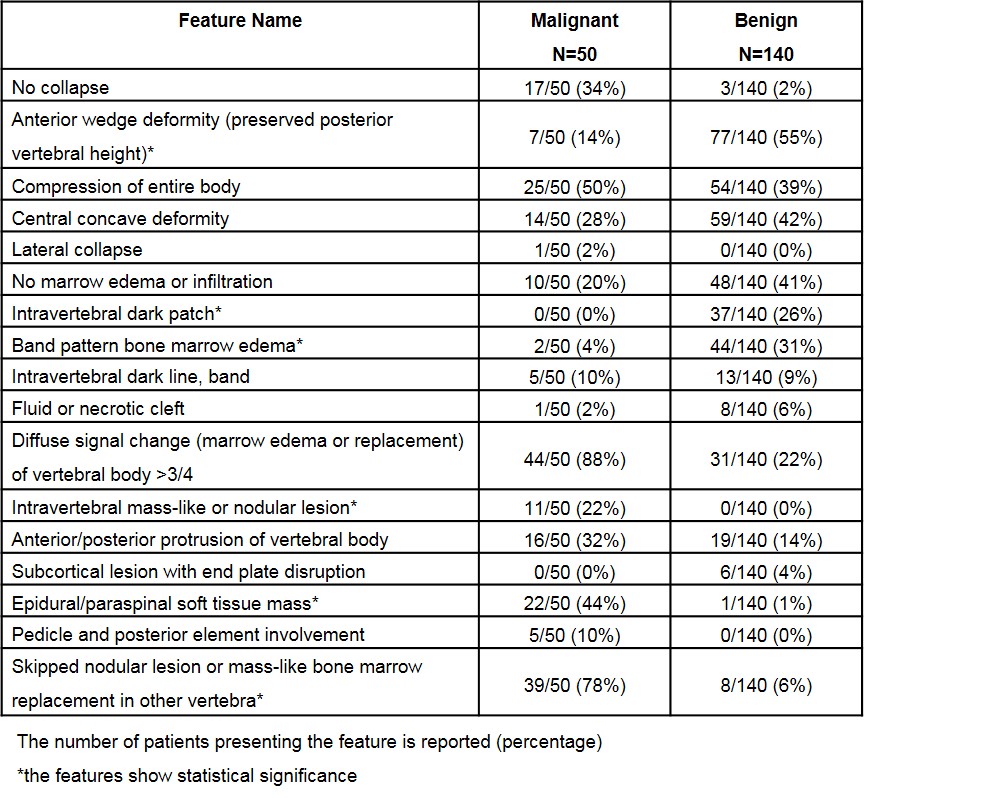
A dataset of 190 patients, 140 benign and 50 malignant fractures, were analyzed. All subjects received MRI of the spine at a GE 1.5T scanner. Imaging sequences included sagittal T1-, axial and sagittal T2-weighted imaging. These images were reconstructed into 512x512 matrix. An experienced radiologist confirmed the lesions and gave the binary score for 17 qualitative features as well as a final diagnostic impression of benign vs. malignant for each patient. All interpretative parameters were combined to develop a classification model using logistic regression (Table 1). Another experienced radiologist identified the abnormal region on sagittal T2W images by manually placing a rectangle region of interest (ROI). The generated smallest bounding box containing the entire abnormal area was used as input, and mapped to T1W using linear registration. The input of network includes both T1W and T2W of the selected slice combined with its two neighboring slices containing the lesion. Therefore, the input channel number is 6. We used Resnet 50 as backbone and a convolutional layer with 1x1 filter was added to the bottom of the network to extract interchange features and transformed 3 channels to 6 channels (4). The classification performance in the training dataset was evaluated using 10-fold cross-validation. The developed model using ResNet50 was applied to a second independent testing dataset of 113 benign and 113 malignant patients. Of these, 78 patients had reconstructed matrix size of 512x512, and 148 had matrix size of 384x384. In the testing dataset, the malignancy probability for each slice was directly calculated based on the model. A prediction probability over 0.5 was considered as malignancy. To explore the ability of deep learning for malignancy detection, the whole images from training set was used to train another ResNet50 to identify the slices containing malignant tumors. A classification activation map (CAM) method was used for the weakly supervised cancer localization (5). The activation map generated before the fully-connected layer could be interpreted as a heatmap that presented the likelihood of tumor lesions across spatial locations. The result was compared to the ground truth and IoU (Inresection over Union) were calculated.Results
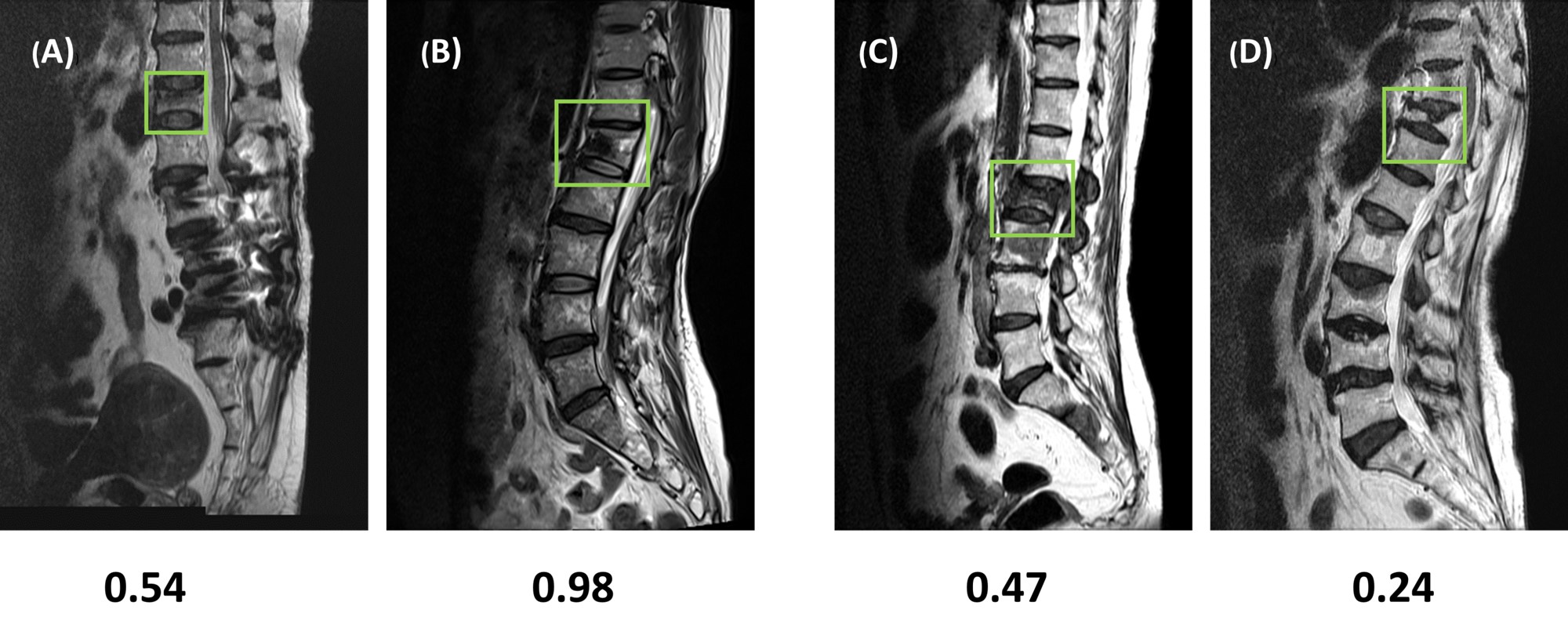
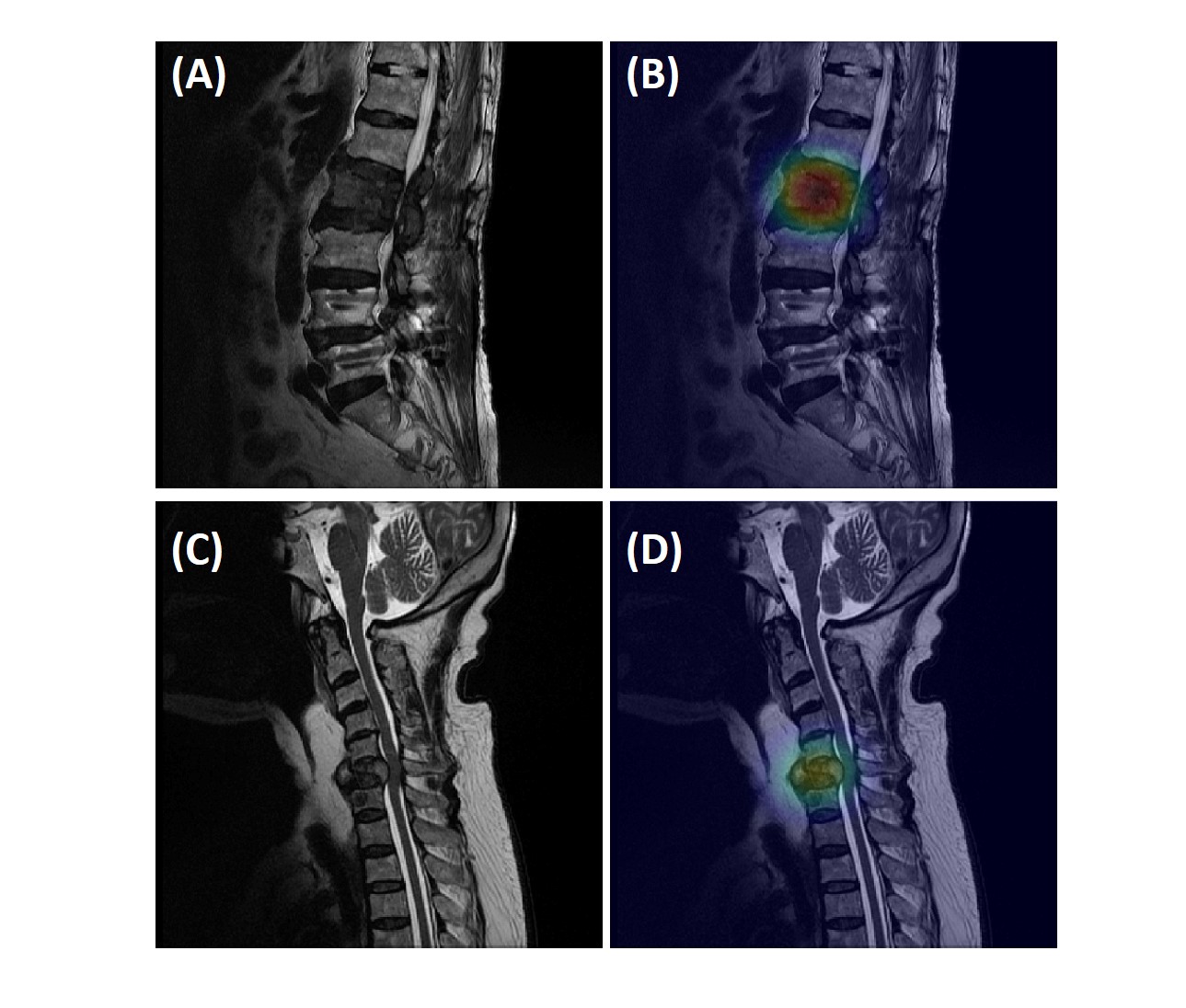
In the training dataset, the radiologist’s diagnostic accuracy was 0.99. When using the scores of 17 features to build a logistic regression model, the accuracy was 0.94. Using ResNet50, the accuracy was 0.84 for per-slice diagnosis, and 0.92 for per-patient diagnosis. For the testing in the second independent dataset, the matrix size of the image was found to have a great influence on the performance. When using images of 512x512 matrix size, the accuracy was 0.80 for per-slice diagnosis and 0.76 for per-patient diagnosis. But, when the matrix size was changed to 384x384, the per-slice accuracy was reduced to 0.71 and the per-patient accuracy became much lower (0.66). Figure 1 shows four examples of correct prediction of malignant and benign vertebral fracture. Figure 2 shows four examples of wrong prediction of malignant and benign vertebral fracture. To adjust the difference between matrix sizes, an architecture of the resolution fitted model was developed, as shown in Figure 3. One additional convolutional layer was added to the bottom of the developed convolutional layer with 3x3 filter size for adaptive pre-processing. We used 1/3 of patients with matrix 384x384 to tune the trained model and used the other 2/3 patients as validation set. By using this strategy to account for different matrix size, the per-slice accuracy was improved from 0.71 to 0.78, and the per-patient accuracy was improved from 0.66 to 0.74. For identification of malignant fracture using whole images from training set, the prediction accuracy is 0.71. We used 0.5 as a threshold to estimate the lesion boundary and obtained an IoU of 0.46. Figures 4 shows two examples of malignant vertebral lesion localized by the CAM method.Discussion
This study used ResNet50 as the deep learning approach to differentiate malignant and benign vertebral fracture. The results obtained from the training and the testing dataset were all inferior to the subjective reading of the experienced radiologist. The better diagnostic performance of human reading is likely due to the fact that in this study, we only analyzed one level of selected vertebral body. However, the radiologist’s diagnosis of benign or malignant fracture is based on the combined information derived from T1WI and T2WI images in all planes, including the detection of adjacent soft tissue mass, pedicle and posterior element involvement, and other skipped bone marrow lesion, which are more specific for malignancy. These imaging components were not analyzed by deep learning approach. However, the deep learning approach can potentially provide help for the young and inexperienced radiologists. For the equivocal cases difficult to make a definite diagnosis, it is also hoped that deep learning approach can increase the diagnostic specificity. Our study also noted that the imaging matrix had a huge impact of the diagnostic accuracy. Thus, the image matrix size or spatial resolution needs to be considered in designing algorithms to improve the robustness of the diagnostic model. For the detection of malignant fracture using whole images from training set, the prediction accuracy was only moderate, with rooms for improvement.Acknowledgements
This study was supported by NIH R01 CA127927, the National Natural Science Foundation of China (81971578, 81701648), and the Key Clinical Projects of the Peking University Third Hospital (BYSY2018007).References
[1] Jung HS, et al. Discrimination of metastatic from acute osteoporotic compression spinal fractures with MR Imaging. RadioGraphics. 2003;23:179–87.
[2] Herneth AM, et al. Vertebral metastases:assessment with apparent diffusion coefficient. Radiology. 2002;225:889–94.
[3] Chan JH, et al. Acute vertebral body compression fractures:discrimination between benign and malignant causes using apparent diffusion coefficients. J Radiol. 2002;75:207–14.
[4] He K, et al. Deep residual learning for image recognition. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2016.
[5] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. and Torralba, A., 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2921-2929).
Figures