0245
Deep Shoulder CT Image Synthesis from MR via Context-aware 2.5D Generative Adversarial Networks1Radiology, Columbia University Irving Medical Center, New York, NY, United States, 2Information and Computer Engineering, Chung Yuan Christian University, Taoyuan City, Taiwan, 3Radiology, Stony Brook Medicine, Stony Brook, NY, United States
Synopsis
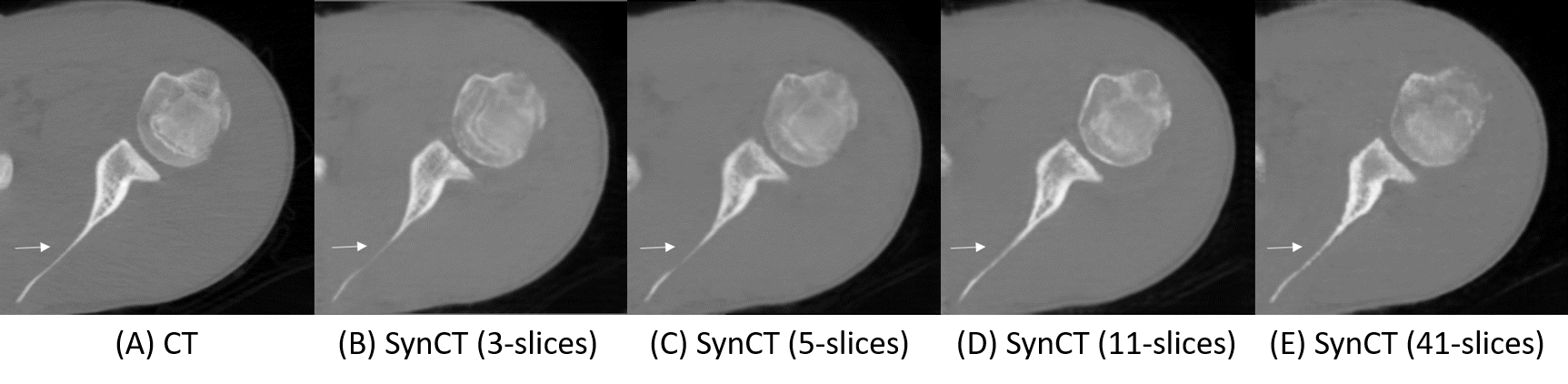
We developed a context-aware 2.5D Generative Adversarial Network (GAN) to generate synthetic CT images from MRI. Adjacent 2D slices with in plane matrix of 512 x 512 and user defined slice context (from 3 to 41-slices) were provided as input. This allows the network to learn out-of-plane information for the slice of interest thereby alleviating the intensity discontinuity problem seen in 2D networks. In addition, this approach uses less GPU memory than a 3D GAN. Our results indicated that the network trained with larger number of adjacent slices outperform the fewer slice network.
Introduction
Glenoid track measurements acquired on CT scan are critical for preoperative planning in shoulder instability surgery. They help dictate what type of surgery is needed based on the degree of bone loss in the humeral head and glenoid 1. However, there are drawbacks to CT including cost and radiation. Synthetic CT generation from MRI data using deep learning (DL) can provide CT-like images for preoperative planning which could obviate the need for CT and provide an alternative to 3D MRI techniques. Here we utilize a context-aware 2.5D generative adversarial network (GAN) algorithm to generate accurate synthetic CT images from MRI.Cross-modality DL image synthesis especially GANs 2, 3 has gained popularity recently. In our study, a GAN is formed by adding a discriminator network to examine the synthetic CT made from the generator network, therefore forcing the generator to output indistinguishable images from the actual CT. Due to the GPU memory bottleneck, intake of a whole 3D volume and training a 3D GAN is unfeasible. Rather, 3D volumetric data is usually provided to the network as either 2D slices or cropped into 3D patches. Using 2D training strategy with a single slice without adjacent context information often suffers from intensity discontinuity between predicted slices. On the other hand, if 3D patches are used for training this can manifest into grid artifact in the reconstructed 3D data 4. In this study, we used a full 2D MR slice without cropping to retain in-plane information along with the neighboring slices in the through-plane direction to train a context-aware 2.5D GAN. The 2.5D GAN was trained by varying the number of adjacent slices around the slice of interest from 3 to 41 to evaluate the effect of context slices on the accuracy and structural similarity of the synthetically generated slice as compared to ground truth CT.
Methods
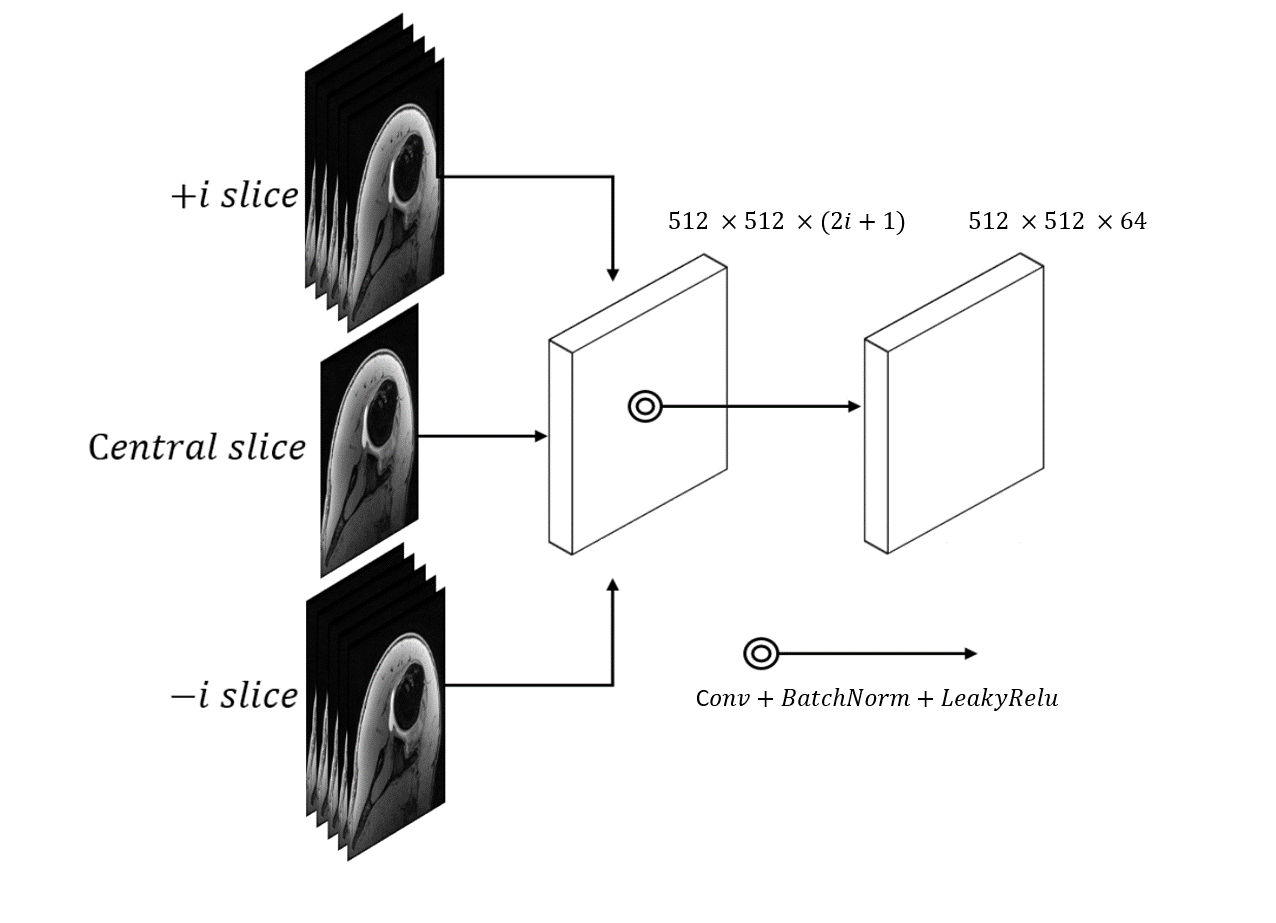
Patient data: An IRB approved retrospective study was performed which identified 13 shoulder instability patients with MR shoulder arthrograms that included an axial volume interpolated breath-hold examination (VIBE) sequence and a paired CT scan within 2 months prior to operative intervention (mean age 26.3 ± 7.2 years old). MRs were performed on a 3T Skyra scanner (Siemens) and CT scans were performed on a Somatom Definition AS scanner (Siemens). Axial VIBE images were acquired with voxel size 0.625 x 0.625 x 0.6 mm3. CT images were acquired with voxel size 0.5 x 0.5 x 0.5 mm3. For data preprocessing, to ensure pixel-wise accuracy between paired MRI and CT data, affine 3D image registration was performed with normalized mutual information metric using ANTs 5 software. The CT volume was resampled to match the MR volumes. 10 randomly selected cases were designated for network training; 3 cases were reserved for testing.DL Network Architecture: We used Pix2Pix implementation 6 to perform conditional generative adversarial network (cGAN) learning. The generator was formed by Res-U-Net, which contained short skip connections to preserve spatial information7; the discriminator was formed by 5 convolutional layers with 70 x 70 patch inputs to generate 1-dimensional outputs identifying the input image as ground-truth (CT) or not. To address the intensity discontinuity problem often present on a 2D network, we designed a multi-channel/multi-slice 2D convolution block (2.5D GAN) to intake 512 x 512 x (2i+1) data, where i denotes the context number in through-plane direction. This training strategy enabled cGAN to capture 3D context information from adjacent slices without cropping images into smaller patches. This network was compared with other synthetic CT generation algorithms like Res-U-Net and unpaired cycle consistency GAN 6.
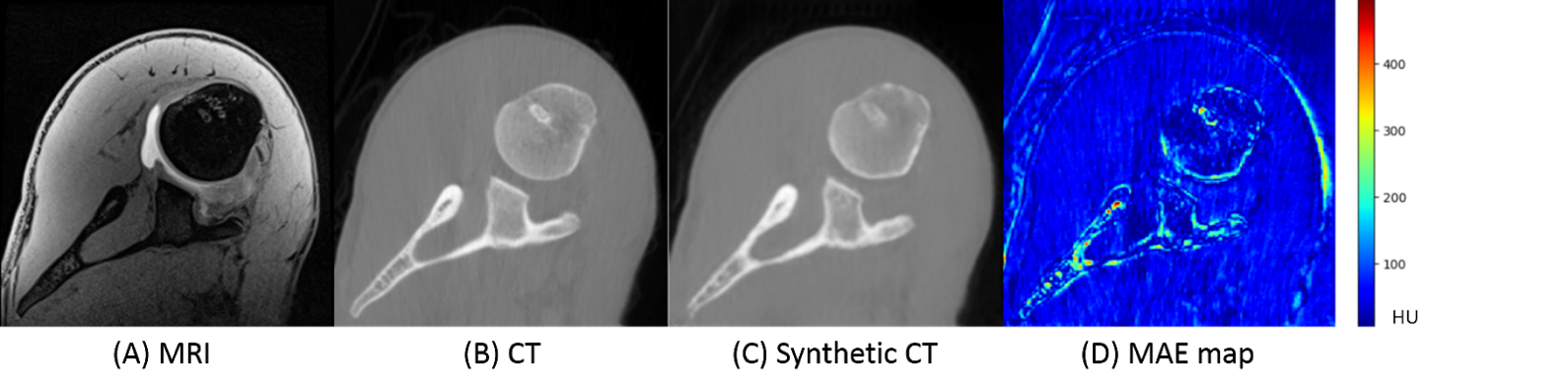
Comparison Analysis: CT images acquired from patients were treated as ground-truth to compare against the MRI-generated synthetic CT. The quality of synthetic CT was quantified using mean absolute error (MAE), mean square error (MSE), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM).
Results/Discussion
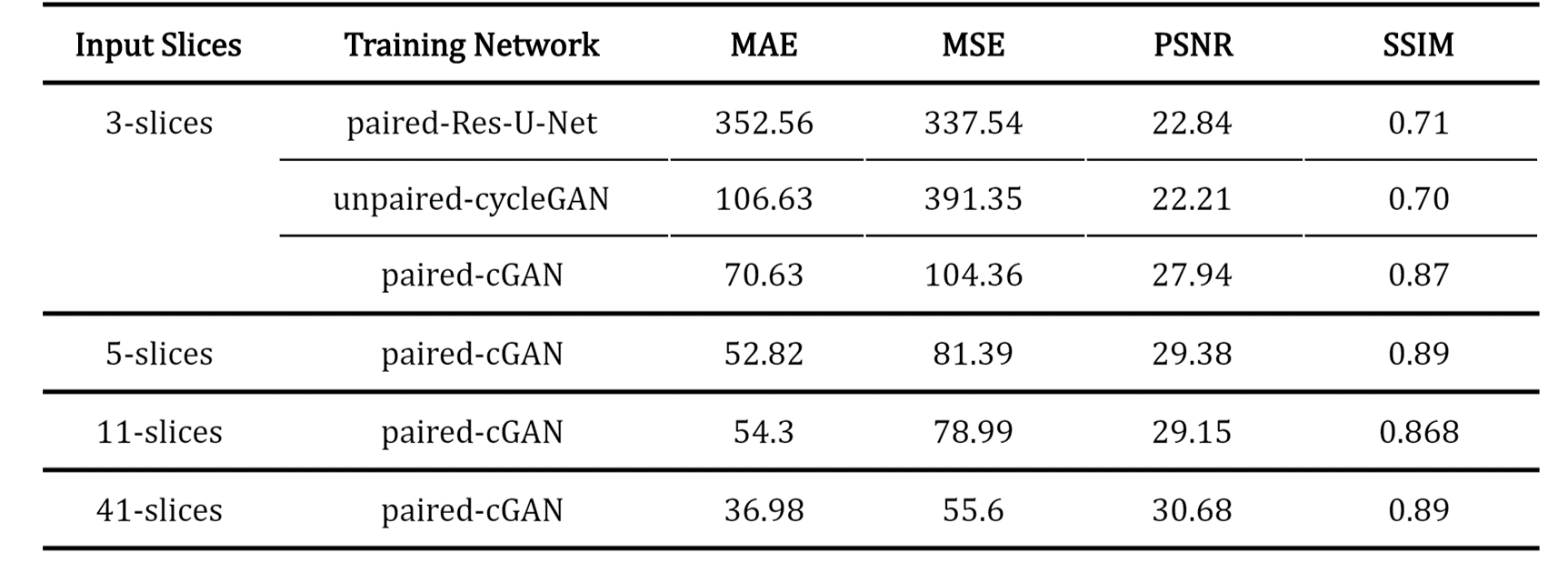
First, we compared the synthetic CT generated from 2.5D cGAN with output from Res-U-Net trained and cycle-consistency GAN data with 3-slices input (Table 1). The Res-U-Net and cycleGAN achieved comparable results, while cGAN trained with paired data outperformed both networks in all 4 metrics evaluated. These results demonstrate that paired training in a small dataset (10 cases) is more robust than unpaired training (cycleGAN); also, an adversarial network can yield more accuracy outputs than CNN architecture (Res-U-Net) under the same training condition.Second, we gradually increased the number of input slices from 3-slices to 5-slices, 11-slices, and 41-slices to increase the context-awareness of the network. Going from an input of 3-slices to 41-slices, MAE reduced by 47.6%, MSE reduced by 48.1%, PSNR increased by 28%, and SSIM increased by 2.2%.
Conclusion
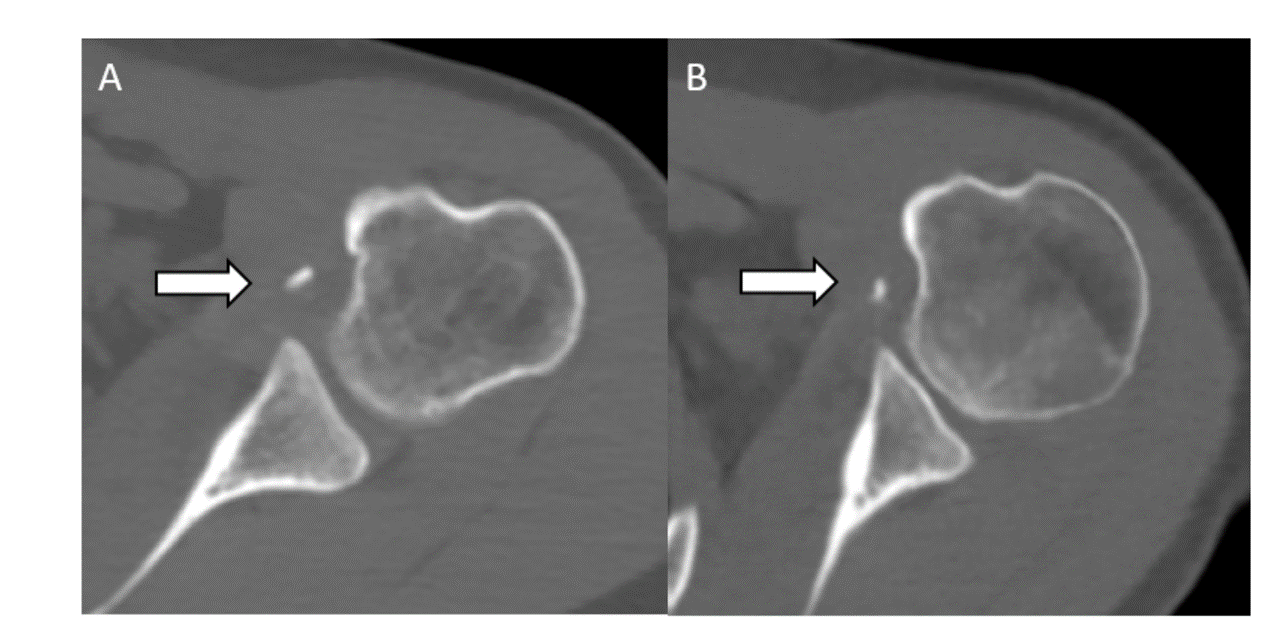
We develop a novel network training strategy to utilize multiple 2D slices (up to 41 slices) concatenated into a cGAN to increase the size of the training dataset and achieve superior synthetic CT results compared with a lower number of slices input. For the next step, we plan to perform non-inferiority testing on synthetic CTs generated by our algorithm in providing glenoid track measurements to demonstrate clinical utility (Figures 3 and 4).Acknowledgements
No acknowledgments found.References
1. Di Giacomo G, Itoi E, Burkhart SS. Evolving concept of bipolar bone loss and the Hill-Sachs lesion: from “engaging/non-engaging” lesion to “on-track/off-track” lesion. Arthroscopy. 2014 Jan;30(1):90–8.
2. Choi Y, Choi M, Kim M, Ha J-W, Kim S, Choo J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018. doi: 10.1109/cvpr.2018.00916.
3. Yi X, Walia E, Babyn P. Generative adversarial network in medical imaging: A review. Medical Image Analysis 2019;58:101552. doi: 10.1016/j.media.2019.101552.
4. Nie D, Cao X, Gao Y, Wang L, Shen D. Estimating CT Image from MRI Data Using 3D Fully Convolutional Networks. Deep Learning and Data Labeling for Medical Applications Lecture Notes in Computer Science 2016:170–178. doi: 10.1007/978-3-319-46976-8_18.
5. Avants BB, Tustison NJ, Song G, Gee JC. ANTS: Advanced Open-Source Normalization Tools for Neuroanatomy. Penn Image Computing and Science Laboratory. 2009
6. Isola P, Zhu J-Y, Zhou T, Efros AA. Image-to-Image Translation with Conditional Adversarial Networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017. doi: 10.1109/cvpr.2017.632.
7. Drozdzal M, Vorontsov E, Chartrand G, Kadoury S, Pal C. The Importance of Skip Connections in Biomedical Image Segmentation. Deep Learning and Data Labeling for Medical Applications Lecture Notes in Computer Science 2016:179–187. doi: 10.1007/978-3-319-46976-8_19.
Figures