0108
Real-time estimation of 2D deformation vector fields from highly undersampled, dynamic k-space for MRI-guided radiotherapy using deep learning1Department of Radiotherapy, Division of Imaging & Oncology, University Medical Center Utrecht, Utrecht, Netherlands, 2Computational Imaging Group for MR diagnostics & therapy, Center for Image Sciences, University Medical Center Utrecht, Utrecht, Netherlands, 3Department of Neurosciences, University of Turin, Turin, Italy
Synopsis
MRI-guided radiotherapy (MRgRT) enables new ways to improve dose delivery to moving tumors and the organs-at-risk (e.g. in abdomen) by steering the radiation beam based on real-time MRI. While state-of-the-art techniques (e.g. compressed sensing) can provide the required acquisition speed, the corresponding reconstruction time is too long for real-time processing. In this work, we investigate the use of multiple deep neural networks for image reconstruction and subsequent motion estimation. We show that a single motion estimation network can estimate high-quality 2D deformation vector fields from aliased images, even for high undersampling factors up to R=25.
Introduction
MRI-guided radiotherapy (MRgRT) promises real-time treatment adaptation (i.e., beam steering) to improve the treatment of tumors that are subjected to respiratory or cardiac motion. To enable this, MR images must be acquired with high temporal resolution and processed with minimal latency to estimate deformation vector fields (DVFs) such that the radiation beam can always be focused on the moving tumor. This precludes computationally intensive reconstruction algorithms such as Compressed Sensing (CS) and non-Cartesian Parallel Imaging (PI).Deep Learning (DL) has the advantage over CS and PI that the computationally intensive 'training' phase can be performed off-line prior to treatment, while the forward ‘inference’ operation can produce high-quality results in real-time[1]. A combined DL-based image reconstruction and motion estimation approach from highly undersampled k-space has therefore the potential to speed up DVF computation sufficiently to allow true real-time adaptive RT.
In this work we assess the performance of DL-based image reconstruction and motion estimation on heavily undersampled 2D golden-angle (GA) radial acquisitions. The individual and combined performance of both methods are assessed based on total computation time and quality of the eventual motion estimation compared to a fully-sampled ground-truth estimate. These approaches are illustrated in Figure 1.
Materials & Methods
Training Data: We used clinically acquired, magnitude-only data from 106 patients, which resulted in 162 2D sagittal cine sequences of the abdomen, acquired on a 1.5T MRI scanner (Ingenia, Philips, Best, the Netherlands) with a balanced steady-state free precession (bSSFP) sequence (TR/TE=2.8/1.4ms, FA=50o, resolution=1.42x1.42mm2, FOV=320x320mm2, slice thickness=7mm) yielding 26095 images with a temporal resolution between 500 and 570ms. The length of cine varies between 25 seconds and 2.5 minutes. For each cine sequence Optical Flow DVFs[2] (OF DVFs) were estimated w.r.t. a randomly-chosen ”fixed“ image from the same cine. During training, images were retrospectively undersampled using a GA radial trajectory using the PyNUFFT library[3]. Data were divided in a 75/25% train-test split on a patient-basis.Reconstruction: Conventional NUFFT reconstructions from the GA radial k-space data were made using PyNUFFT’s adjoint operator, without CS or PI. DL reconstructions were made by training dAUTOMAP[4] on the gridded, undersampled k-space (R=10, Adam optimizer, lr=10−3) minimizing the $$$\ell_2$$$-loss.
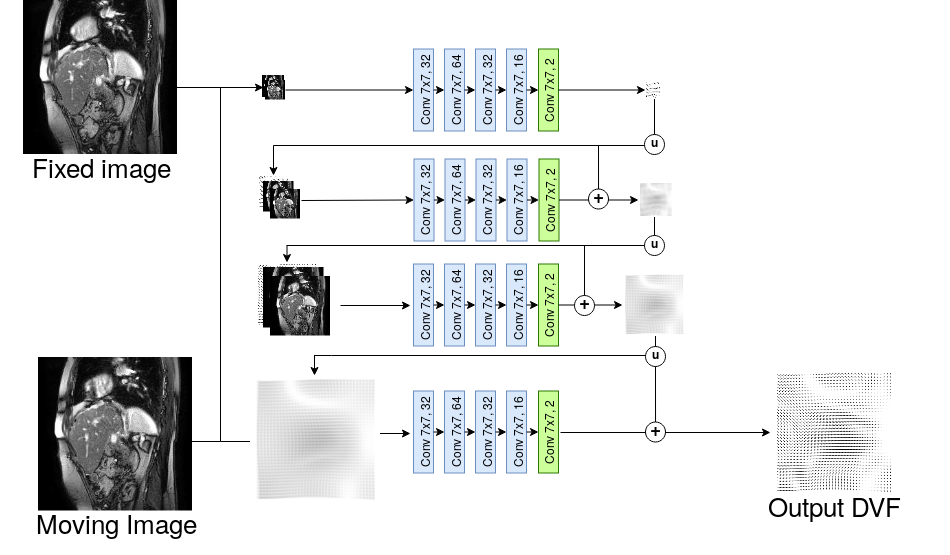
Motion Estimation: We computed OF DVFs on NUFFT- and dAUTOMAP-reconstructed images. For DL-based motion estimation we trained a modified SPyNET[5] on NUFFT- and dAUTOMAP-reconstructions (R=10) using four pyramid levels (Adam optimizer, lr= 5−4) minimizing the $$$\ell_2$$$-loss w.r.t. ground-truth OF DVFs. The training of SPyNET is explained in Figure 2.
Evaluation: We evaluated the DVFs for multiple acceleration factors (R=10/16/20/25) according to three metrics:
- Registration error - The error in millimeter of an estimated motion field w.r.t. the ground truth DVF within an ROI.
- SSIM - The average SSIM[6] of the cine sequence after registration compared to the corresponding fixed image, indicating the quality of the motion field for registration.
- Time - The time it takes to estimate the DVFs from k-space.
Results & Discussion
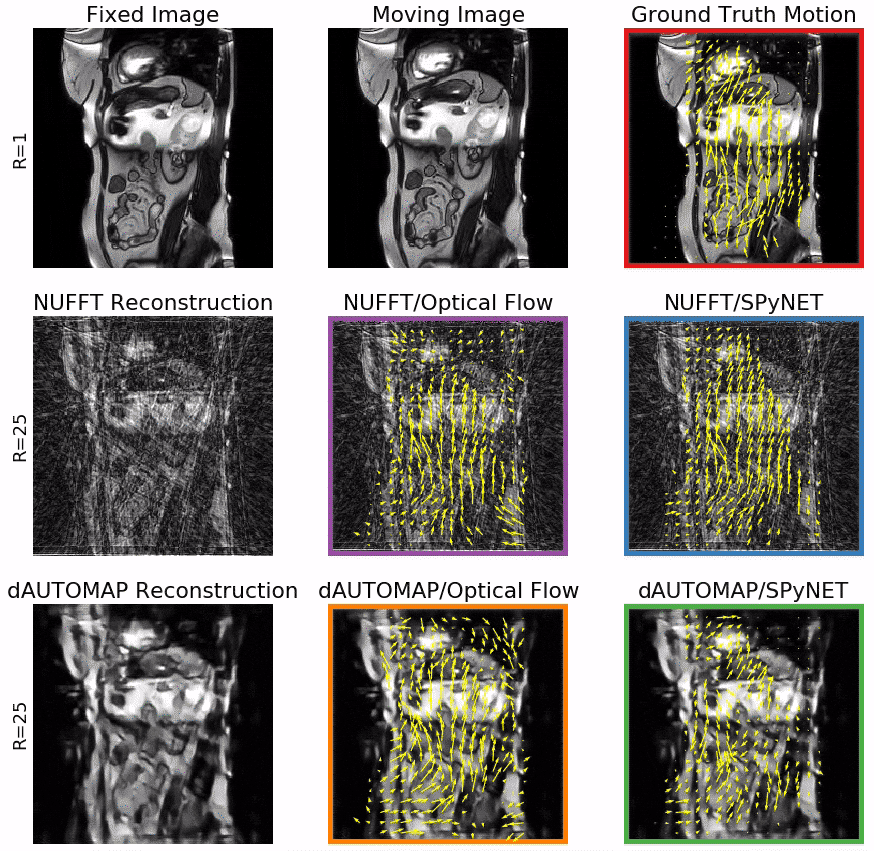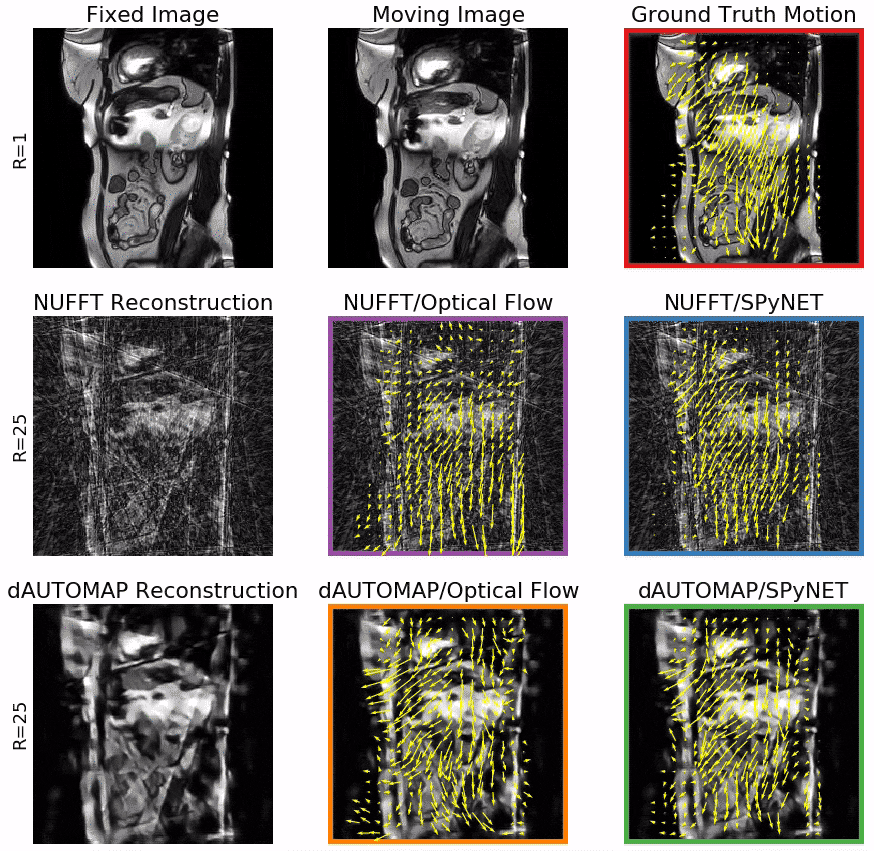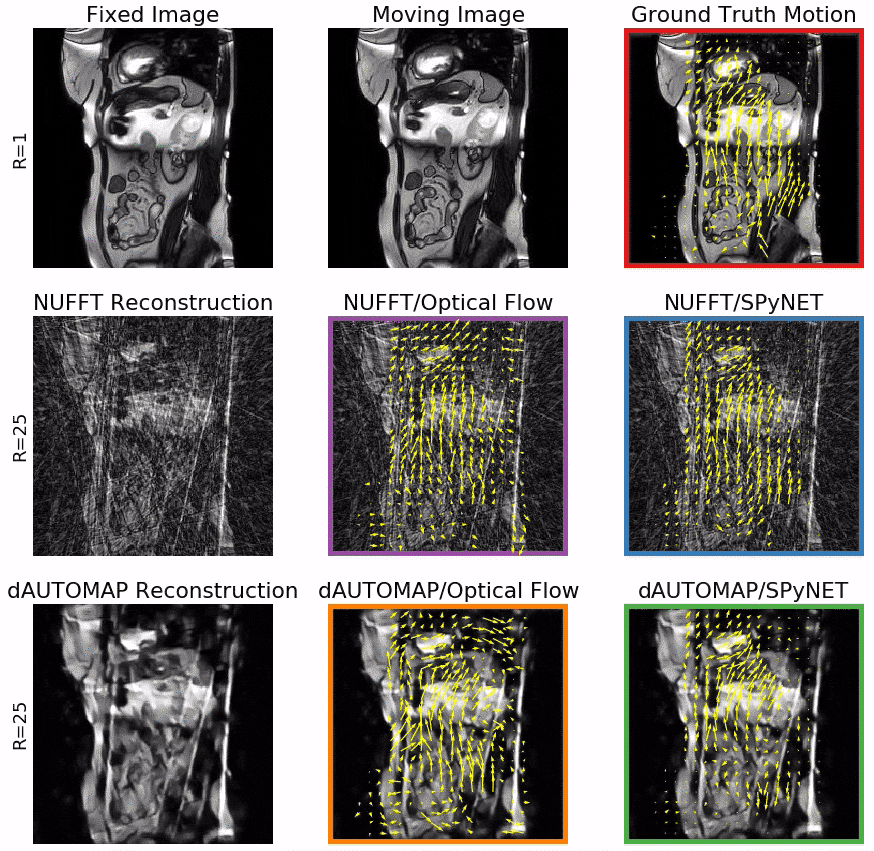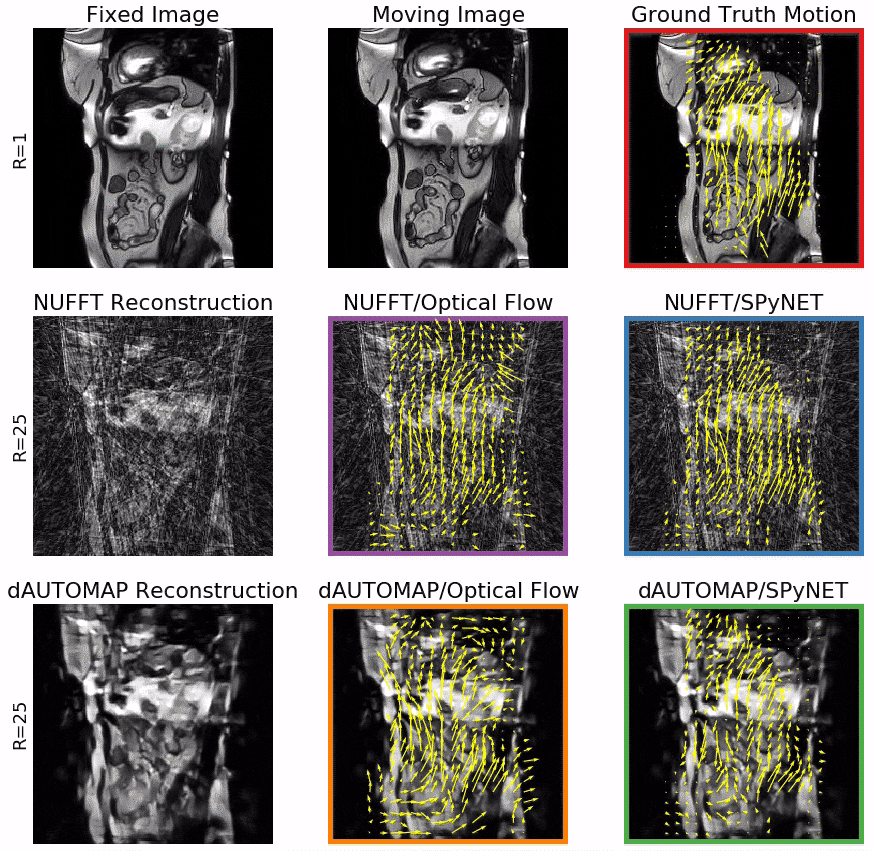
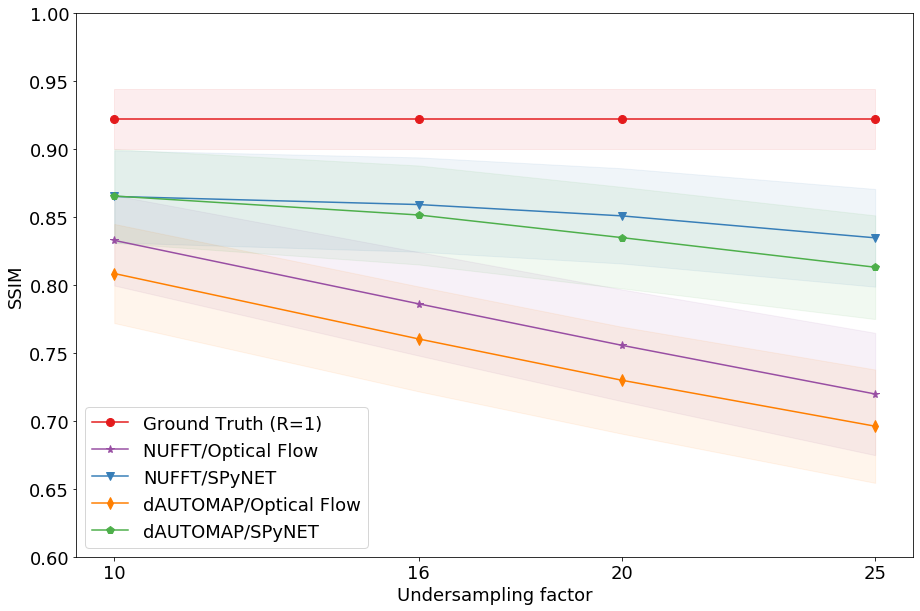
Figure 3 shows typical DVFs computed by the four evaluated methods at R=25. OF on NUFFT-reconstructions shows good agreement with the ground truth, but introduces false motion due to streaking artifacts. Computing OF on dAUTOMAP reconstructions performs poorly due to the introduction of pseudo-random intensity variations. Using SPyNET rather than OF shows a clear improvement in DVF quality w.r.t. the ground truth. These results are quantified in Figures 4 and 5. Figure 4 shows the displacement agreement of a motion method w.r.t. the ground-truth OF within a manually selected ROI for 25 patients in the test set. This is expressed by the Pearson correlation factor between the ground-truth and the motion method. Figure 5 presents the SSIM w.r.t. the fixed image after registration as a function of the undersampling factor. The results attest that the displacement agreement and SSIM increase significantly when using SPyNET rather than OF. They also show that using SPyNET on NUFFT-reconstructed images results in the best motion estimation at high acceleration factor, meaning that dAUTOMAP has no value for motion estimation.At R=25, the MR acquisition will take ~45ms and both reconstruction without CS/PI and SPyNET take 15ms. With a total of 75ms, this method is fast enough for real-time MRgRT. These DL models are not significantly faster than well-optimized non-DL solutions, but increase in quality allows us to increase the undersampling factor which decreases acquisition time. The results also indicate that a general-purpose DL-based reconstruction approach such as dAUTOMAP obscures important motion information by favoring overly smoothed images with subtle intensity ramps; a known failure-case for OF. On the other hand, SPyNET learns to resolve streaking artifacts through its multi-resolution approach, yielding robust, high-quality DVFs.
Conclusion
In this work we demonstrated that DL enables high-quality motion estimation from the MRI signal within 75ms at R=25 with a registration error of typically less than 1 voxel. These results could enable real-time tumor tracking on MR-Linac devices during MRgRT. While dAUTOMAP was unable to produce suitable images at R=25, SPyNET produces accurate DVFs on the undersampled reconstruction (without CS/PI). This suggests that the DVFs are easier to learn and therefore allow for higher undersampling factors. Future work includes extending this method to 3D and more rigorous validation by training the models for more undersampling factors and with prospectively undersampled acquisitions.Acknowledgements
This work is part of the research program HTSM with project number 15354, which is (partly) financed by the Netherlands Organization for Scientific Research (NWO). We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for prototyping this research.References
[1] Hammernik, Kerstin, et al. "Learning a variational network for reconstruction of accelerated MRI data." Magnetic resonance in medicine 79.6 (2018): 3055-3071.
[2] Zachiu, Cornel, et al. "An improved optical flow tracking technique for real-time MR-guided beam therapies in moving organs." Physics in Medicine & Biology 60.23 (2015): 9003.
[3] Lin, Jyh-Miin. "Python Non-Uniform Fast Fourier Transform (PyNUFFT): An Accelerated Non-Cartesian MRI Package on a Heterogeneous Platform (CPU/GPU)." Journal of Imaging 4.3 (2018): 51.
[4] Schlemper, Jo, et al. "dAUTOMAP: decomposing AUTOMAP to achieve scalability and enhance performance." arXiv preprint arXiv:1909.10995 (2019).
[5] Ranjan, Anurag, and Michael J. Black. "Optical flow estimation using a spatial pyramid network." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[6] Wang, Zhou, et al. "Image quality assessment: from error visibility to structural similarity." IEEE transactions on image processing 13.4 (2004): 600-612.
Figures
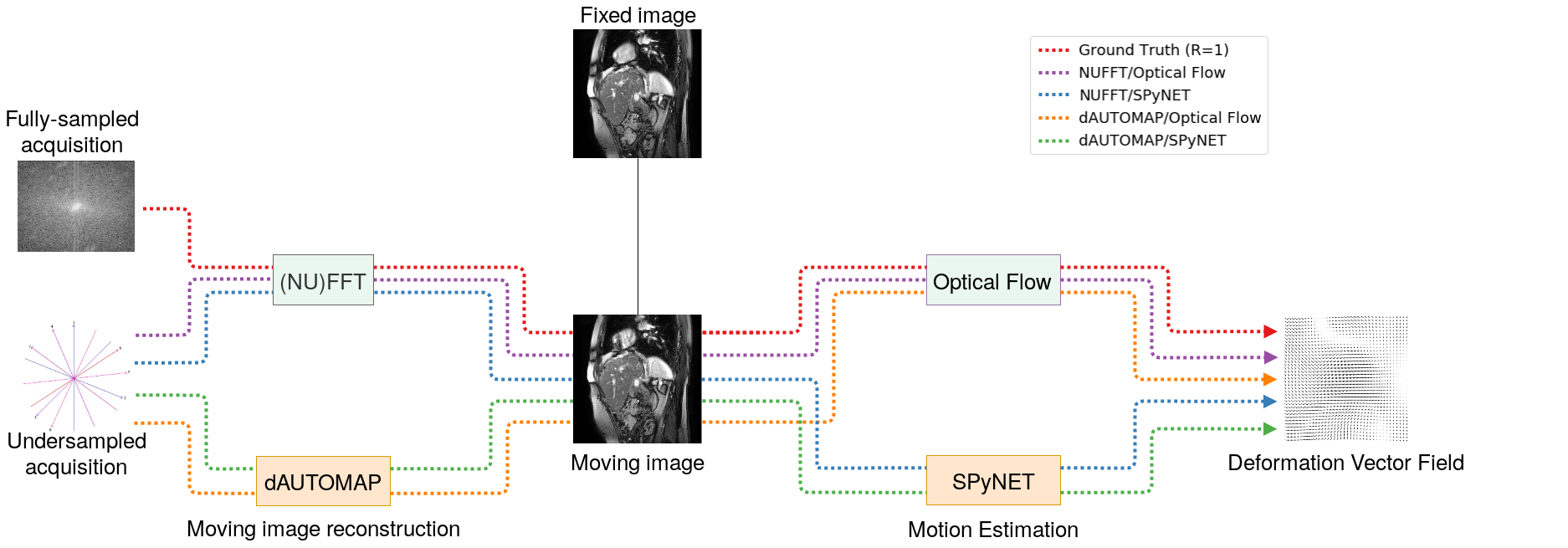
Figure 1: Model overview. An overview of our model comparison setup. We compute ground truth motion with Optical Flow from fully-sampled images (red). Our candidate models reconstruct images from undersampled acquisitions and estimate motion between the moving and fixed image (reconstructed with the same algorithm). Our candidate models are:
- NUFFT reconstruction and Optical Flow (purple)
- NUFFT reconstruction and DL-based motion estimation (blue)
- DL-based reconstruction with dAUTOMAP and Optical Flow (orange)
- DL-based reconstruction and DL-based motion estimation (green)