5527
Increasing Arterial Spin Labeling Perfusion Image Resolution Using Convolutional Neural Networks with Residual-Learning1Institute of Biomedical Engineering, School of Communication and Information Engineering, Shanghai University, Shanghai, China, 2Temple University, Philadelphia, PA, United States
Synopsis
A common problem in arterial spin labeling (ASL) perfusion MRI is the relatively low spatial resolution and subsequently the partial volume effects. We evaluated a new deep learning-based super-resolution algorithm for solving that problem. The algorithm successively produced higher resolution ASL cerebral blood flow image from low resolution data, which even outperformed an existing super-resolution method.
Introduction
Arterial spin labeling (ASL) perfusion MRI [1] provides a non-invasive approach to map the quantitative cerebral blood flow (CBF) but often with low resolution. A confounding consequence of low-resolution is the partial volume effects (PVE), which may induce substantial CBF underestimation especially in the tissue boundary or in the presence of brain atrophy. Current ASL PVE correction is either purely based on an empirical brain water partition ratio [2] or a non-local mixing model [3], which both can induce errors due to the inaccuracy of the assumptions. Outside of the MRI field, residual-learning based convolutional neural networks (CNN) have been successfully used in achieving super-resolution (SR) for nature images [4]. In this study, we proposed and evaluated a stacked local wide residual networks (SLWRN) with performance exceeding the existing Very Deep Super Resolution (VDSR) algorithm [5]. The potential benefits of learning high-resolution from low-resolution data include: correcting PVE, inheriting the relatively high signal-to-noise-ratio and shorter acquisition time provided by low-resolution MRI.Methods
ASL MRI images with two different resolutions were acquired with a GE 3T Discovery 750 scanner from 13 healthy young adults who provided signed written informed consents. GE product 3D ASL sequence was used to produce CBF maps with the following parameters: label time=1450ms, delay time=1520ms, voxel size=4×4×3.4 and 2.7×2.7×3.4mm3 respectively for the two ASL scans, and TR/TE=4690ms/10.86ms.
The SLWRN we built had three modules: the patch extraction and representation, nonlinear mapping, and image reconstruction. The first module had one convolutional layer with 64 filters. The second stacked three residual blocks. Each residual block had two local wide residual units, each containing three convolutional layers. The first layer in the unit had 64 filters with the size of 3×3, which was doubled and then doubled again in the next two successive layers respectively. The rectified linear unit (ReLU) was used as the activation function of each convolutional layer. Residual-learning was included through
$$x_i=F_i(x_{i-1}; W_i)+h(x_{i-1})$$
where $$$x_i$$$ is the output of the i-th residual unit, $$$F_i$$$ is the local residual mapping to be learned, $$$W_i$$$ is the i-th layer weight, and $$$h(x_{i-1})$$$ is a skip connection unit
$$h(x_{i-1})=W^{skip}_i * x_{i-1}$$
where $$$W^{skip}_i $$$ is the weight of skip connection.
A two-layer convolutional network with 128 filters of size 3×3 and 1 filter of size 3×3 respectively was added to the end to finally project the nonlinear feature maps learned in the inner layers into the output SR reconstruction. SLWRN was compared with VDSR and validated with 6-fold cross-validations. Nonoverlapped image patches with a size of 21x21 voxels were extracted from intracranial regions. Augmentation through 90o rotation and scaling with a factor of 0.6 was used to generate more training data. Since the ASL CBF images were coregistered, each patch from the low-resolution map got the reference patch from the same location in the high resolution map. All algorithms were implemented with Caffe framework in a computer with NVIDIA Titan X GPU and CPU of the Intel E5-2630. Peak signal to noise ratio (PSNR) and structural similarity index (SSIM) were calculated as the performance indices.
Results
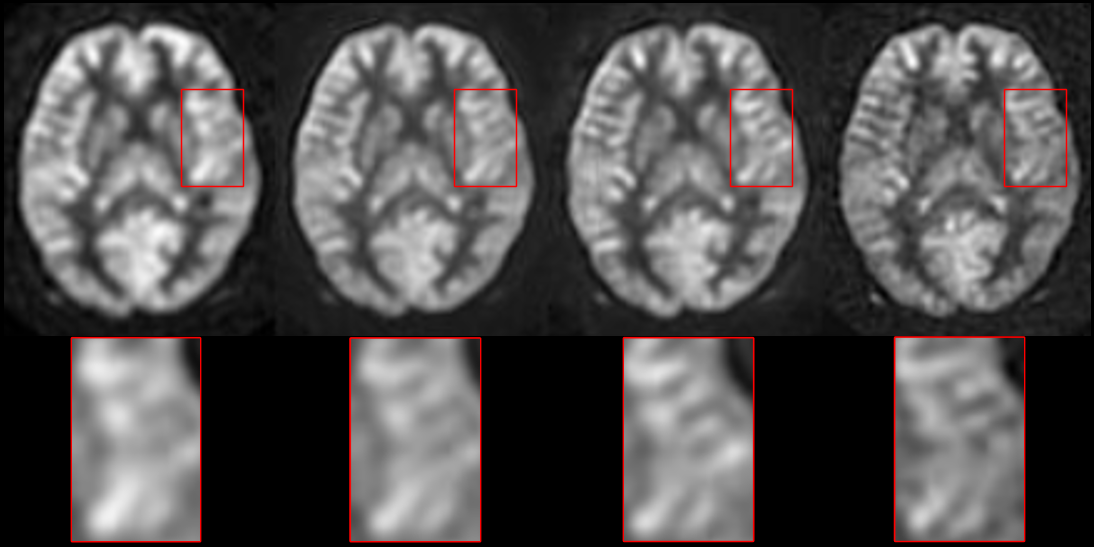
Table 1 shows that SLWRN produced a PSNR of 22.95±0.35 and SSIM of 0.7446±0.0177, both higher than that of VDSR. Fig. 1 shows the high resolution CBF reconstructed from low-resolution one for one representative subject. As compared to VDSR (2nd column), SLWRN (3rd column) produced a CBF map with more structure details, closer to the gold standard (4th column). As compared to the gold standard, SR CBF map clearly showed higher signal-to-noise-ratio.Discussion
We evaluated a deep CNN for getting super-resolution for ASL CBF map. Our data showed that the network outperformed an existing SR method and produced SR CBF map showing high similarity to the gold standard. While more data are needed to confirm the results, our data showed the capability of increasing resolution and then correcting PVE for ASL MRI.Acknowledgements
Work supported by Natural Science Foundation of Zhejiang Province Grant LZ15H180001, the Youth 1000 Talent Program of China, and Hangzhou Qianjiang Endowed Professor Program, National Natural Science Foundation of China (No. 61671198).References
1. Detre, J.A., et al., Perfusion imaging. Magnetic Resonance in Medicine, 1992. 23: p. 37-45. 2. Du, A.T., et al., Hypoperfusion in frontotemporal dementia and Alzheimer disease by arterial spin labeling MRI. Neurology, 2006. 67(7): p. 1215-20. 3. Asllani, I., A. Borogovac, and T.R. Brown, Regression algorithm correcting for partial volume effects in arterial spin labeling MRI. Magn Reson Med, 2008. 60(6): p. 1362-71. 4. Dong, C., et al., Image super-resolution using deep convolutional networks. IEEE transactions on pattern analysis and machine intelligence, 2016. 38(2): p. 295-307. 5. Kim, J., J. Kwon Lee, and K. Mu Lee. Accurate image super-resolution using very deep convolutional networks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.Figures