5401
Automatic delicate segmentation of the intervertebral discs from MR spine images using deep convolutional neural networks: ICU-net1School of Electrical and Electronic Engineering, Yonsei University, Seoul, Republic of Korea, 2Philips Korea, Seoul, Republic of Korea, 3Department of Radiology, VA San Diego Healthcare System, San Diego, CA, United States, 4Department of Radiology, University of California-San Diego, La Jolla, CA, United States
Synopsis
The segmentation method using Deep Convolutional Neural Networks shows good performance in medical imaging. In particular, U-net is a well-known and successful model. However, U-net based on classification network shows weakness in fine segmentation. We developed a new model by changing layers and structure of U-net. Our model enables more detailed segmentation of the intervertebral discs in spine MR images.
Purpose
Methods using Convolutional Neural Networks (CNN) have a good performance for segmenting desired objects in medical images. Among them, the U-net model1 is well-known as a very effective model. However, since U-net is based on a network for classification, there is a limit to detect the details of the image. So, it is necessary to overcome these limitations in order to segment objects with thin and sharp parts such as intervertebral discs in spin MR images. We aim to make a new network model which can do the delicate segmentation of intervertebral discs in MR spine images.Method
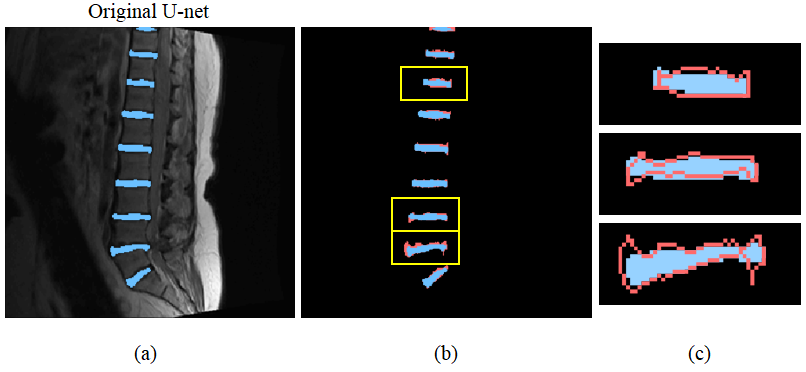
Since Classification basically focuses on the existence of objects, the Deep Convolutional Neural Network (DCNN) for Classification draws out only the robust concepts through several convolution and pooling processes. Therefore, it concentrates on global rather than detail and it is difficult to segment objects which require dense prediction of pixel unit2. To overcome these limitations, U-net tried to preserve detailed information by using up-convolutional network and resolution preserving path. However, as can be seen in Figure 1, U-net does not preserve such fine information sufficiently.
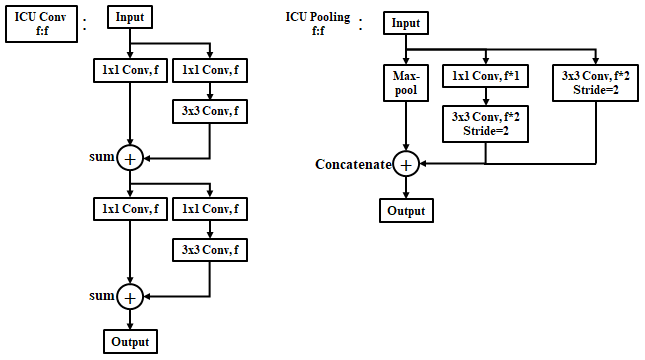
In order to preserve the detailed information disappearing during the convolution and pooling process, we have devised an ICU (Iterative Composite U-net) convolutional layer and an ICU-pooling layer as shown in Fig.2. First is about the ICU-convolutional layer. We use 3x3 convolutions which has superior performance for extracting features, and use 1x1 convolutions to preserve the information that the pixel itself has. Then we added both to send the output containing both pieces of information to the next layer. In the case of ICU-pooling layer, max-pooling discards the rest of the information in the process of extracting important information, so we used a convolutional layer additionally, which has stride 2, to preserve it. Since a 1x1 convolution with a stride of 2 discards information like max-pooling, a 1x1 convolution specifies a stride of 1 and then uses a 3x3 convolution again with a stride of 2. The pooling processes need to distinguish the important parts from the other parts for the feature extraction. So concatenation rather than summation is more appropriate in the joint part.
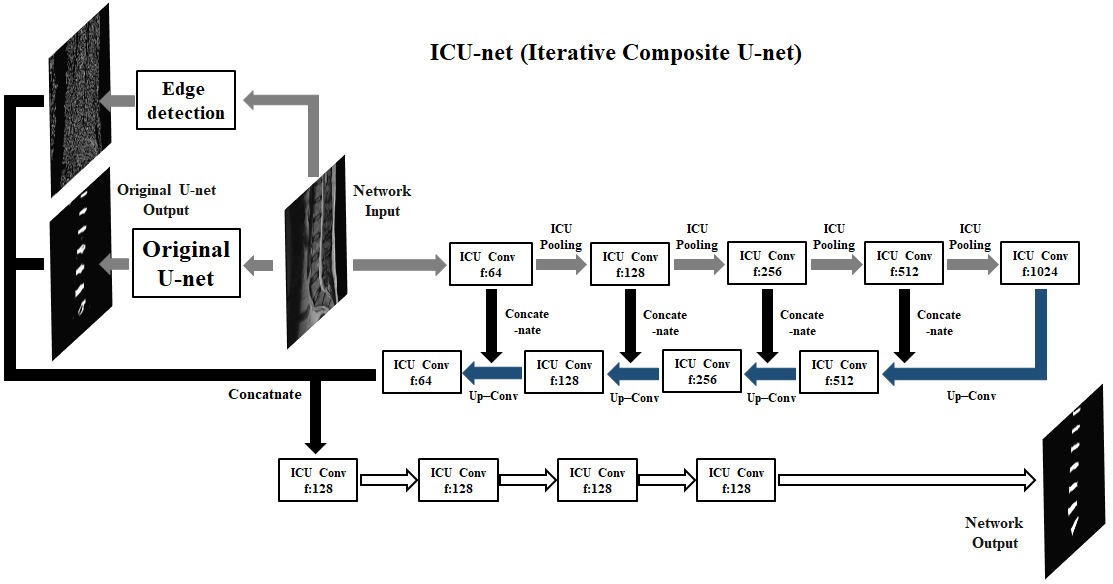
The changed network has increased performance in detail but the false positive section has risen. This is because the ability to see the whole has diminished because the network focuses on detail. To overcome these drawbacks, the overall network structure is constructed as shown in Figure 3. The input image is merged after passing three networks. The first network is a transformed U-net consisting of ICU-convolutional layers and ICU-pooling layers. The second network is Canny Edge detection3 for extracting Edge information. And the final network is the original U-net. The second network exists to emphasize fine edge information and the third network exists to reduce false positives. The combined three network outputs become output result after going through four ICU-convolutional layers.
Results and discussion
The experiments were performed using T2-weighted spine MR images from Spineweb4,5. The images used in the experiment were 25 sagittal images and k-fold cross validation method was applied (k=5). The original U-net achieved 88.0% dice accuracy and the proposed network (ICU-net) achieved 89.3% dice accuracy.
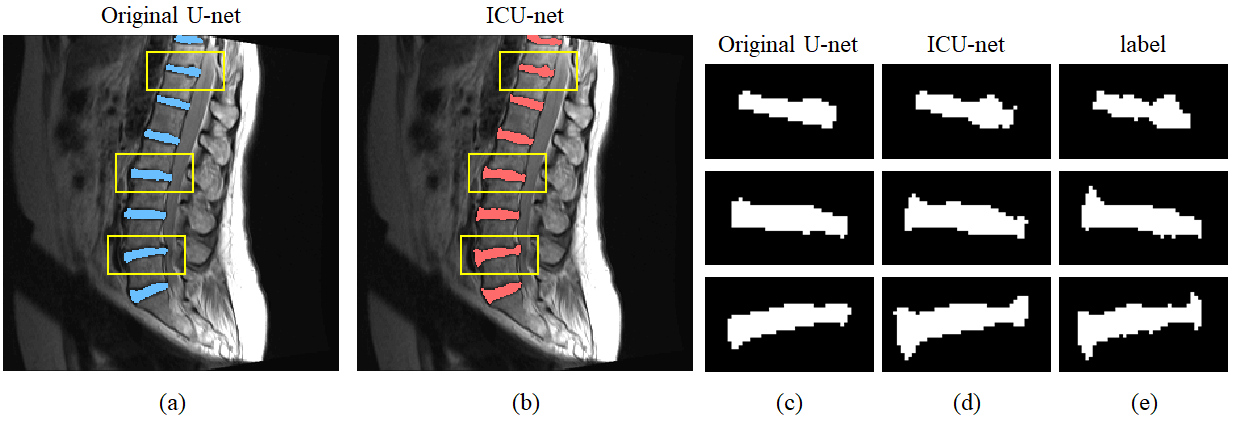
Figure 4 shows the comparison between the original U-net result and the proposed network result. Fig. 4(a) and (b) show segmentation results for the original U-net and the ICU-net, respectively. And fig. 4(c-e) show enlarged network results for the yellow boxes of fig. 4(a, b). Fig. 4(d) seems to follow the boundary region of fig. 4(e) (label) better than fig. 4(c). These show that the ICU-net segments more subtle detail than the original U-net. In comparison of segmented area boundaries, the original U-net shows a match of 49.7% with label boundaries, while the ICU-net shows a match of 54.1% which is 4.4% higher than the original U-net.
When looking at the results, the overall segmentation is already well done in the original U-net. Therefore, the proposed network aims to improve the segmentation performance at the fine boundary of the target object. 1.3% increase of dice accuracy may not be considered significant, but it is a fairly large increase if it is a rise at the boundary of the target object.
Conclusion
The precision of the intervertebral disc segmentation is very important. This is because a small difference in the boundary can greatly affect the diagnosis result. We propose a method that allows for such fine segmentation. Our experimental results show that our method is meaningful enough and has potential for development.Acknowledgements
This research is supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP) (2016R1A2R4-015016).References
1. Ronneberger O, Fischer P and Brox T. U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2015. p. 234-241.
2. Liang-Chieh C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected crfs. International Conference on Learning Representations. 2015.
3. Canny J. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence. 1986, 6:679-698
4. http://spineweb.digitalimaginggroup.ca/. Accessed November 8, 2017.
5. Cai Y, Osman S, Sharma M, et al. Multi-modality vertebra recognition in arbitrary views using 3D deformable hierarchical model. IEEE Transactions on medical imaging. 2015, 34.8:1676-1693
Figures