4413
ASIC Model of SENSE to Accelerate MR Image Reconstruction1COMSATS Institute of Information Technology, Islamabad, Islamabad, Pakistan, 2Linkoping University, Linkoping, Linkoping, Sweden
Synopsis
In Parallel MRI (pMRI), imaging process is accelerated by acquiring less data using multiple receiver coils and offline reconstruction algorithms (e.g. SENSitivity Encoding (SENSE)) are applied to reconstruct fully sampled data. We present a synthesizable high-description language (HDL) model of SENSE algorithm where the reconstruction can be performed within signal processing chain of MRI scanner. The proposed architecture is tested using simulated human brain data with 8 channel receiver coils and quality of reconstructed images is analyzed using artifact power. The results show that the proposed reconstruction model achieves 0.014 artifact power and is 700 times faster than the CPU based SENSE reconstruction.
Introduction
The speed of MRI systems is determined by the speed at which data is acquired and the time taken by the reconstruction system (in pMRI) to get fully sampled images from the acquired undersampled data1. It is desirable to have an advanced reconstruction platform that is capable of handling computationally intense reconstruction algorithms like SENSE. In MRI systems, an efficient hardware platform for real-time processing of the acquired undersampled images can be highly useful2,3.Methods
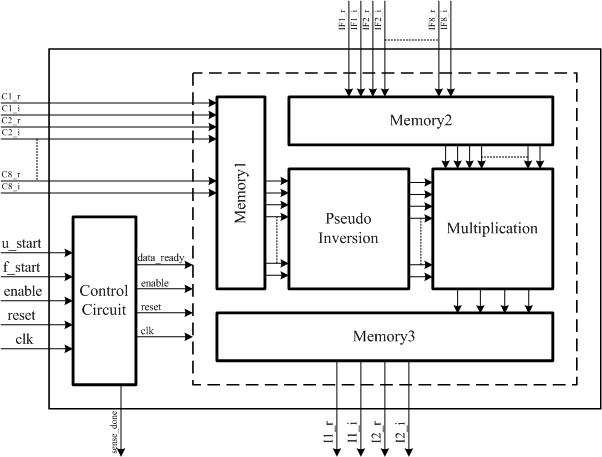
SENSE uses inversion of the encoding matrix to reconstruct fully sampled image from the undersampled data acquired from MRI scanner. We present an architecture to implement SENSE algorithm within the front end (conventionally used to process the received MRI data) of MRI scanner. The proposed architecture is implemented in Verilog HDL using fixed point arithmetic. The design uses 32-bit binary vectors to represent real and imaginary parts of the input data. A control module is used to handle the data writing operation to memories (used to store the input data). Memory1 is used to store the encoding matrix and Memory2 is used to store the undersampled data from the receiver coils. In Figure 1, when u_start signal is high, the encoding matrix will be stored in Memory1 and an asserted f_start signal will enable writing of the undersampled data into Memory2.
After successfully storing the encoding matrix and undersampled data into the memories, the control module activates the SENSE reconstruction module using the data_ready signal. The reconstruction module uses left inverse method3, to compute inverse of the encoding matrix. The inverted matrix is then multiplied with the undersampled data using 'Multiplication' module. The resultant solution image points are then stored in Memory3, which eventually will contain the whole resultant image. A flag sense_done is used to indicate when estimation of a pixel is complete and the design is ready to estimate next pixel.
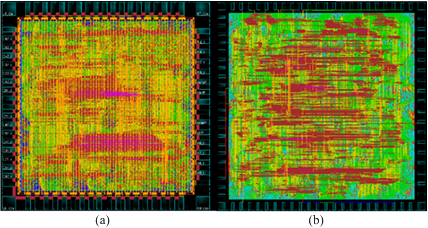
The physical layout of the proposed ASIC model was implemented with 65nm process using the Cadence SoC Encounter. The overall architecture consists of two modules (one Pseudo inverse and one Multiplication). However, multiple Pseudo Inversion and Multiplication modules can be used to estimate multiple pixels in parallel to reduce the reconstruction time. The layout (including IO pads, power pads, corner pads, power routing wires) of both the modules is shown in Figure 2.
Results
The proposed architecture of ASIC can reconstruct 2 pixels of the solution image (a typical case for acceleration factor 2) at a time using the undersampled data. However, the architecture presented is scalable, and can be used to accommodate a higher number of parallel processes to estimate multiple pixels (typically the case in most MRI reconstruction algorithms).
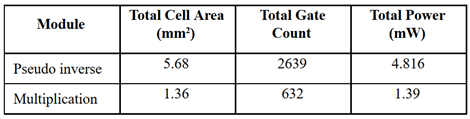
The area, timing and power analyses (shown in Table 1) of the proposed architecture are obtained from the Design Vision Tool. The proposed design is compiled using multi-core processor and it took 31 hours to compile the pseudo-inversion module and approximately 8 hours to compile the Multiplication module. All the synthesis is done using specific libraries and default parameter settings (normal threshold, etc.). The total power consumption of the design is a combination of the dynamic power and leakage power.
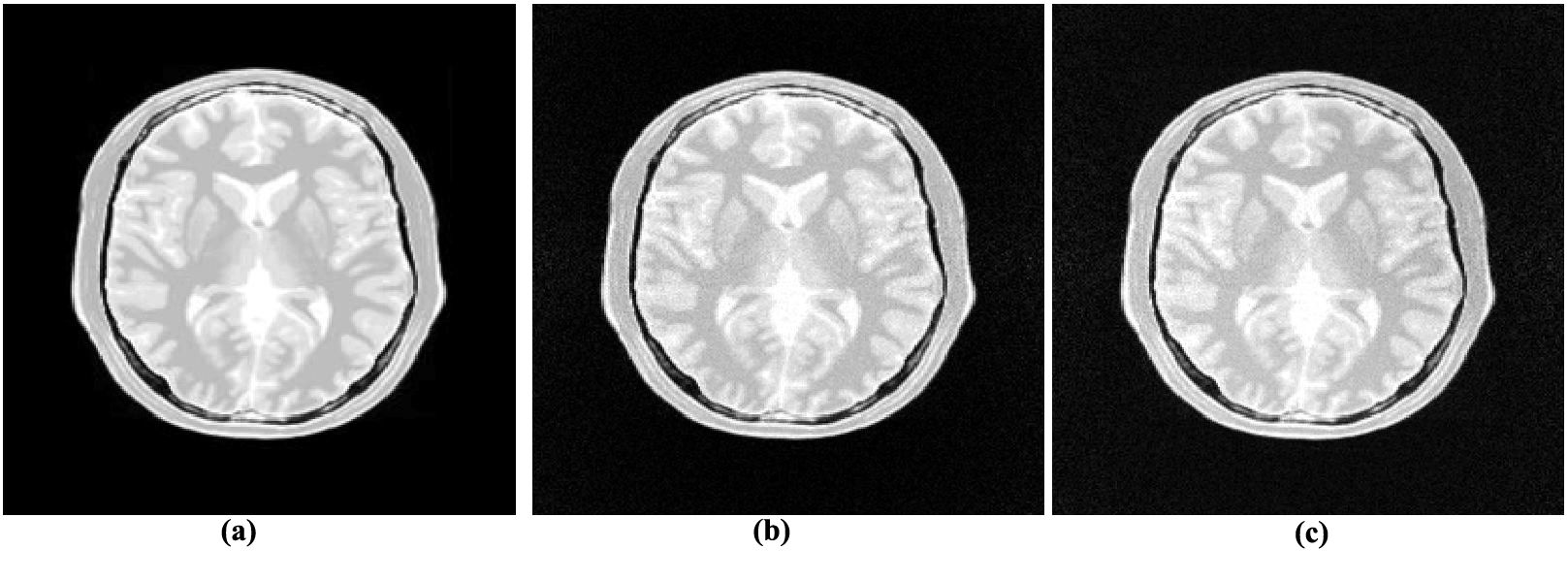
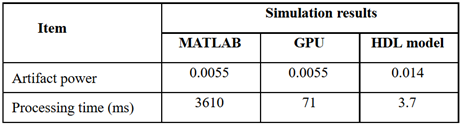
Figure 3 shows the SENSE reconstruction results using CPU (Figure 3b) and using the proposed HDL model (Figure 3c), whereas an original image (Figure 3a) is shown for reference. Figures 3b and 3c show no significant differences between the original image and the reconstructed images. The artifact power of the proposed method is larger as compared to CPU simulation results but still it is within an acceptable range for most MR images. The artifact power can be further reduced by using larger word length (to represent data) with an increased number of fractional bits.
The computation time of the images reconstructed using the proposed architecture (shown in Table 2) is 3.7ms for the simulated human brain dataset which is much less than the CPU model of SENSE reconstruction which takes 3610ms to reconstruct the same dataset (on Core i7 CPU, 6GB RAM and 2.2GHz processor).
Conclusion
In this study, we presented a generalized architecture for SENSE reconstruction using HDL language. The proposed architecture can estimate two pixels of the solution image at a time (as required for AF=2). The architecture is scalable and can be used to estimate multiple pixels at a time (for AF=2) to further reduce the processing time. The architecture provides good image reconstruction results, while a significantly reduced reconstruction time (700 times faster than CPU) enables the use of this architecture for real-time image reconstruction.Acknowledgements
No acknowledgement found.References
1. Stone SS HJ, Tsao SC, Sutton BP, Liang ZP. Accelerating advanced MRI reconstructions on GPUs. Journal of Parallel and Distributed Computing. 2008;68(10):1307-18.
2. Li L, Wyrwicz AM. Design of an MR image processing module on an FPGA chip. Journal of Magnetic Resonance. 2015; 255:51-8
3. Siddiqui, Muhammad Faisal, et al. "FPGA implementation of real-time SENSE reconstruction using pre-scan and Emaps sensitivities." Magnetic Resonance Imaging 44 (2017): 82-91.
Figures