4098
Motion correction in MRI using deep learning1Robarts Research Institute, London, ON, Canada, 2Medical Biophysics, Western University, London, ON, Canada
Synopsis
Subject motion in brain MRI remains an unsolved problem. We propose a machine learning approach for motion correction of brain images. Our initial objective is to train a neural network to perform a motion corrected image reconstruction on image data with simulated motion artefacts. Training pairs were generated using an open source MRI data set; a unique motion profile was applied to each 2D image. A deep neural network was developed and trained with over 3000 image pairs. The images predicted by the network, from motion-corrupted k-space, have improved image quality compared to the motion corrupted images.
Introduction
Subject motion in MRI remains an unsolved problem; motion during image acquisition may cause artefacts that severely degrade image quality. In the clinic, if an image with motion artefacts is acquired, it will often be reacquired. This provides a source from which a large number of motion-degraded images, along with their respective re-scans, could be collected. These pairs of images could be used to train a neural network to identify the mapping relationship between an image with motion artefacts and a high quality, artefact free image. Inspired by previous work demonstrating MR image reconstruction with machine learning,1,2 our objective is to train a neural network to perform motion corrected image reconstruction on image data with simulated motion artefacts. We simulate motion in previously acquired brain images and use the image pairs (corrupted + original) to train a deep neural network (DNN).Methods
Data: The image data were obtained from an open source neuro MRI data set3. This data set comprises T2* weighted FLASH magnitude and phase images for 53 patients, each with 128 non-overlapping image slices; the data set thereby provides thousands of unique 2D magnitude and phase images.
Motion Simulation: Each set of 2D magnitude and phase images, from the data set described above, was combined to create a single complex image which was Fourier transformed to simulate the acquired k-space data. To simulate rigid motion, k-space lines were rotated and phase shifted, simulating the k-space inconsistencies that would occur if the data were acquired while the subject was moving. The motion profiles were parameterized by the time, magnitude and direction of motion. All parameters were randomly generated with constraints to keep the motion in the realm of realistic head motion. A unique 2D motion profile was applied to each 2D image.
Network architecture and training: The DNN was developed and trained using the TensorFlow open source library4. The input layer is a vector of motion corrupted k-space data, and is fully connected to the first hidden layer, which is followed by a convolutional neural network with 3 convolutional layers. The activation functions for the fully connected layer and the convolution layers are the hyperbolic tangent function and rectified linear unit respectively. The output of the network is the reconstructed, motion corrected magnitude image. 3463 image pairs were used to train the network and 300 were reserved for validation and testing. The network was trained for 60 epochs (5 hrs) using the RMSprop optimization algorithm.5 Two 12 Gb GPU's on Compute Canada's SHARCNET computing network were used for training.
Results
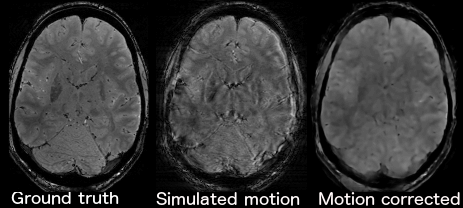
The images predicted by the network, from motion-corrupted k-space, have improved image quality compared to the motion corrupted images. The mean absolute difference between the motion corrupted and ground truth images is 17% while the mean absolute difference between the DNN predicted and ground truth images is only 10%. Many of the predicted images have significantly improved image quality; representative examples are shown in Figure 1. However, in some cases the network-predicted images have substantial blurring; a representative example is shown in Figure 2.Discussion
Motion-corrected image reconstruction using deep learning was successfully achieved on brain images with simulated motion artefacts. This work represents the first time machine learning has been used to perform motion corrected MR image reconstruction. Improving the consistency of the network's performance is the focus of ongoing work, we expect that optimization of the regularization and loss function will improve the networks ability to consistently generalize to new examples and produce sharper output images. Future work will focus on evaluation of the network’s transfer learning potential as well as developing a network for motion correction of 3D images.Acknowledgements
The authors thank Compute Canada for access to SHARCNET's computing resources.References
[1]Zhu B et al., Image reconstruction by domain transform manifold learning, 2017, arXiv:1704.08841 [cs.CV]
[2]Hammernik K et al., Learning a Variational Network for Reconstruction of Accelerated MRI Data, 2017, arXiv:1704:00447 [cs.CV]
[3] Forstmann BU, Keuken MC, Schafer AS., Bazin P., Alkemade A, Turner R (2014) Multi-modal ultra-high resolution structural 7-Tesla MRI data repository. Scientific Data 1:14005
[4] Abadi M et al., TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, 2015.
[5] Tieleman T, Hinton G (2012)
Figures