3365
Fast and Realistic Super-Resolution in Brain Magnetic Resonance Imaging using 3D Deep Generative Adversarial Networks1Department of Bioengineering, UCLA, Los Angeles, CA, United States, 2Biomedical Imaging Research Institute, Cedars-Sinai Medical Center, Los Angeles, CA, United States
Synopsis
High-resolution magnetic resonance image (MRI) are favorable by clinical application thanks to its detailed anatomical information. However, high spatial resolution typically comes at the expense of longer scan time, less spatial coverage, and lower signal to noise ratio (SNR). Single Image Super-Resolution (SISR), a technique aimed to restore high-resolution (HR) details from one single low-resolution (LR) input image, has been improved dramatically by the recent invention of deep Generative Adversarial Networks(GAN). In this paper, we introduce a new neural networks structure, 3D Densely Connected Super-Resolution GAN (DSRGAN) to realistic restore HR features of structural brain MR images. Through experiments on a dataset with 1,113 subjects, we demonstrate that our network outperforms bicubic interpolation in restoring 4x resolution-reduced images.
INTRODUCTION
High-resolution magnetic resonance image (MRI) is favorable by clinical application thanks to its detailed anatomical information. However, high spatial resolution typically comes at the expense of longer scan time, less spatial coverage, and lower signal to noise ratio (SNR). Single Image Super-Resolution (SISR), a technique aimed at restoring high-resolution (HR) details from one single low-resolution (LR) input image, has been improved dramatically by the recent invention of deep Generative Adversarial Networks(GAN). In this work, we introduce a new neural networks structure, 3D Densely Connected Super-Resolution GAN (DSRGAN) to realistically recover HR features of structural brain MR images. Through experiments on a dataset with 1,113 subjects, we demonstrate that our network outperforms bicubic interpolation in restoring 4x resolution-reduced images.METHODS
We used T1-weighted whole brain images in our simulation. Data were obtained from the Human Connectome Project (HCP)[1] database, which has 1113 different subjects. These 3D MPRAGE images are obtained from Siemens 3T platforms and have a matrix size of 320x320x256 and have a spatial resolution 0.7mm isotropic. Data were separated into three different groups: training, validation, and testing, with a split ratio of 8:1:1. To evaluate SR method, pairs of LR and HR images. The original images were referred as ground truth HR, then the LR images were generated by 1) converting HR images into k-space by 3D FFT; 2) lowering the resolution by truncating the outer part of k-space, with a scale of two, along two axes representing two phase encoding directions in MR. 3) Applying invert FFT and linear interpolation to convert images back to the same size of HR. We believed that this downgrading process is closer to the real-world low-resolution MRI acquisition. The pairs of original and subsampled images from the training set were used to train the super-resolution neural networks, as we discuss below.
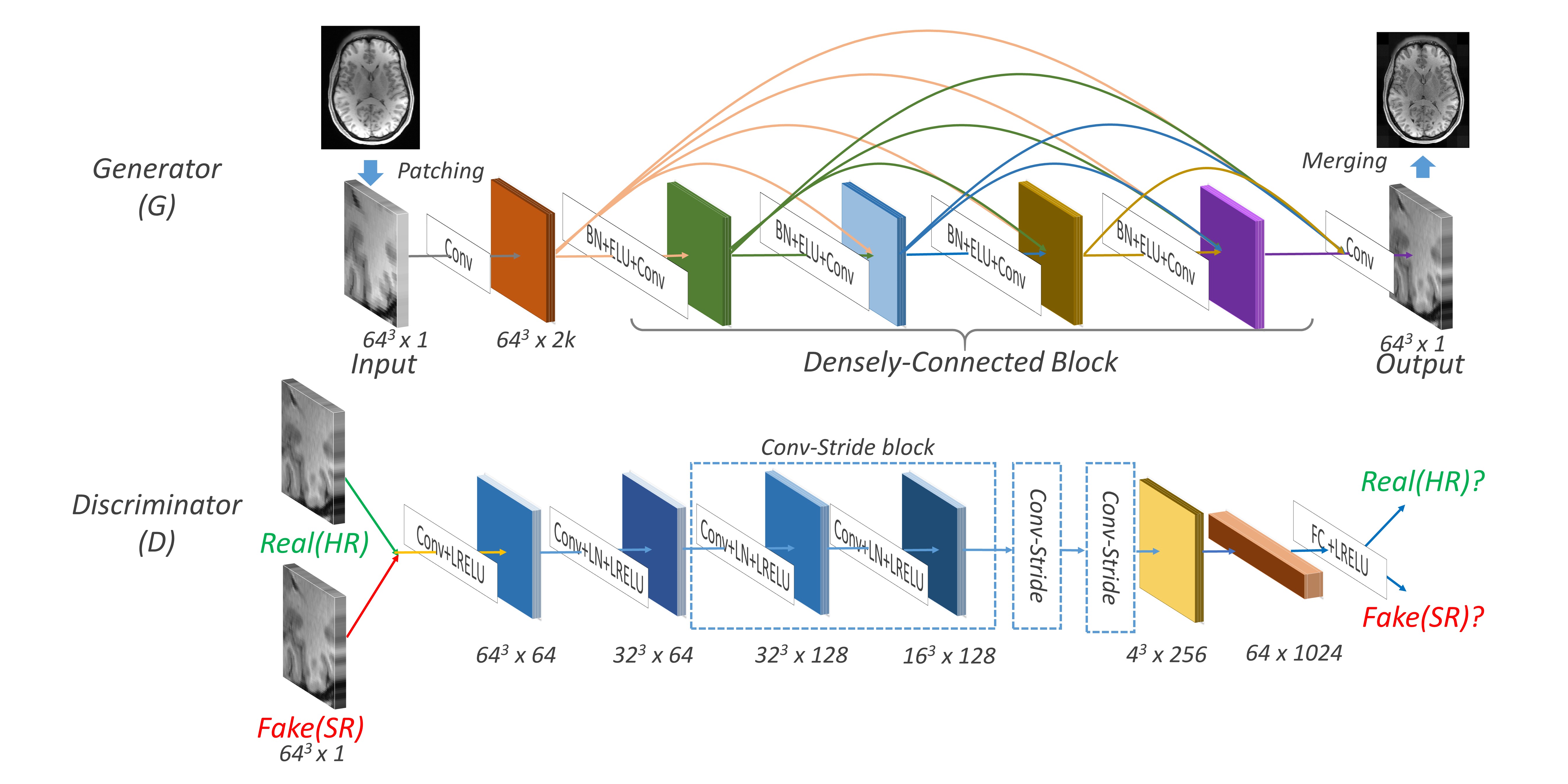
We proposed more efficient and advanced 3D DCSRN inspired by the Densely Connected Neural Networks(DenseNet) [2] and DCGAN[3]. Network structure details are shown in Fig.1. During the training, we fed the generator networks(G) with LR image patches, in a size of 64x64x64, which were randomly cropped from the whole 3D image data to produce SR images. Next, both the real HR and SR images are fed into the Discriminator networks (D). We trained the D to give out scores to distinguish real HR from SR. After D reached some optimal states, the scores from SR were used to trained G again. By alternately training D and G, D learned to distinguish HR and SR better and better while G learned to generate more and more realistic SR output. When the training is finished, G would be able to produce almost identical images to HR. In testing, the patches were merged in sliding window manner whose steps were half of the patch size. Networks were all implemented in Tensorflow [4].
RESULTS
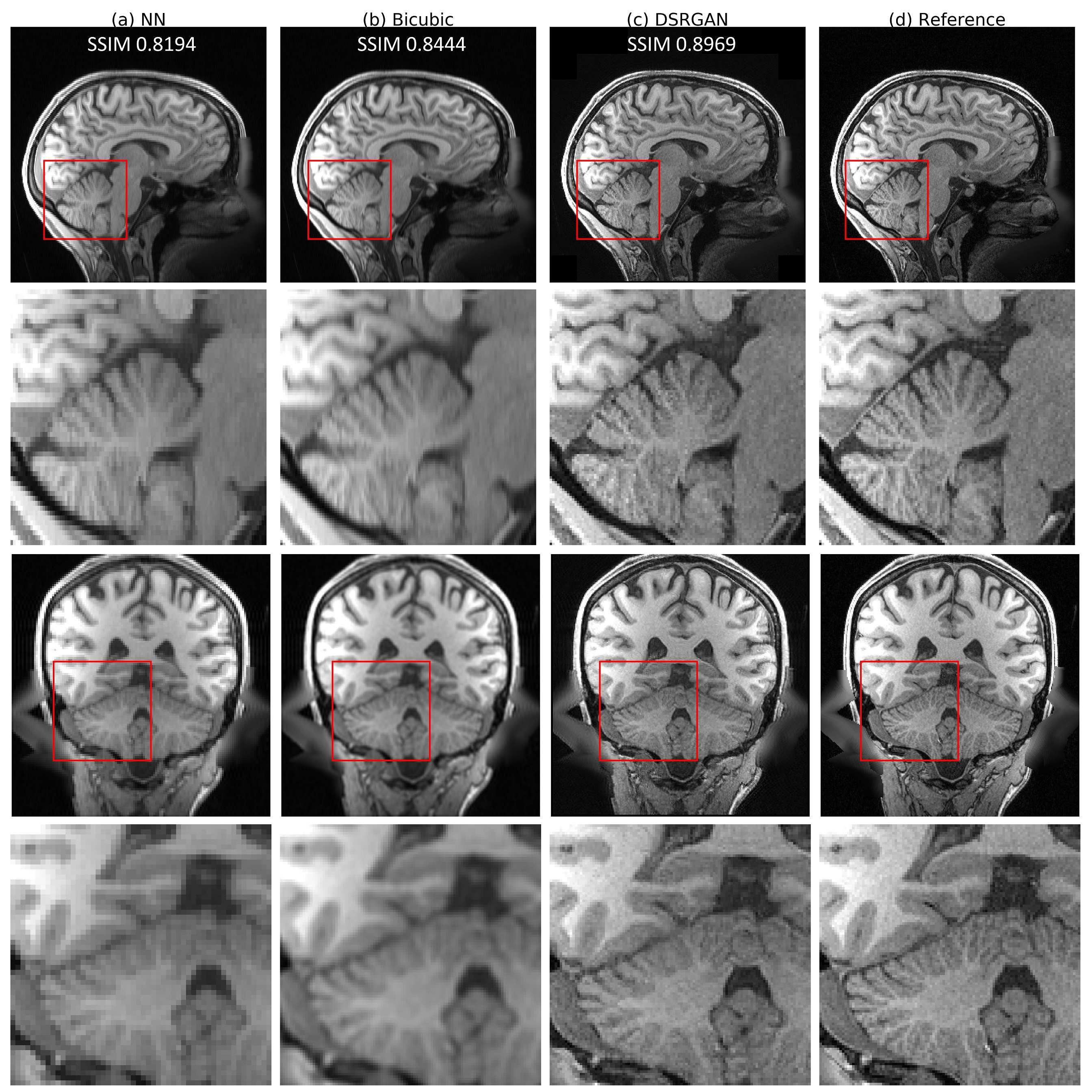
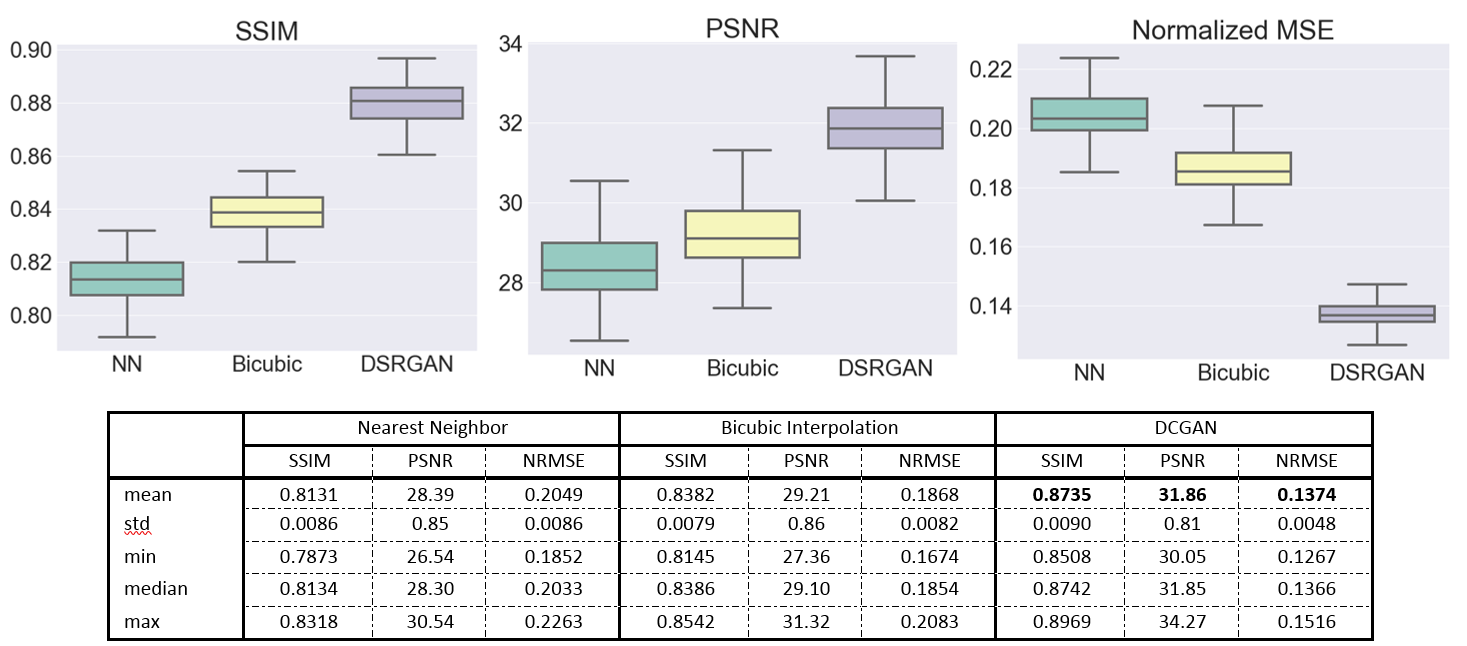
We compared three different models' SR with the original, nearest neighbor (NN), and bicubic interpolation, as shown in Figure 2. For quantitative analysis of our results, we compared the SR output with the HR images in three similarity metrics: peak signal-to-noise ratio (PSNR) and structural similarity (SSIM)[5], normalized root mean square error (NRMSE). Analysis on the test set is shown in Figure 3. The result demonstrated that our model could generate realistic images that are difficult to tell the difference visually. Thanks to the densely-connected structure, our model was very small and ran very fast in testing. On average, it took about 20 seconds to process a whole 3D volume.DISCUSSION
In this work, we proposed a novel deep learning neural network DSRGAN for super-resolution to recover brain T1w images from LR images. Our preliminary study showed that our proposed method outperformed widely used bicubic interpolation and provided realistic images. The ability of this deep learning model to generate high-quality images only based on limited information shows the potential to perform MRI scans in low resolution without sacrificing image quality.CONCLUSION
We demonstrated that a novel deep learning super-resolution network could successfully restore high-resolution brain MR images from low-resolution images. The proposed method outperformed existing methods. It may potentially enable high-resolution MRI with shortened scan time.Acknowledgements
Data were provided [in part] by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.References
[1] David C. Van Essen, Stephen M. Smith, Deanna M. Barch, Timothy E.J. Behrens, Essa Yacoub, Kamil Ugurbil, for the WU-Minn HCP Consortium. (2013). The WU-Minn Human Connectome Project: An overview. NeuroImage 80(2013):62-79.
[2] Huang, Gao, et al. "Densely connected convolutional networks." arXiv preprint arXiv:1608.06993 (2016).
[3] Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
[4] M. Abadi, “TensorFlow: learning functions at scale,” ACM SIGPLAN Notices, vol. 51, no. 9, pp. 1–1, Apr. 2016.
[5] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image Quality Assessment: From Error Visibility to Structural Similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
Figures