2858
Active learning for automated reference-free MR image quality assessment: decreasing the number of required training samples by reduction of intra-batch redundancy.1Department of Diagnostic and Interventional Radiology, University Hospital of Tuebingen, Tuebingen, Germany, 2Institute of Signal Processing and System Theory, University of Stuttgart, Stuttgart, Germany, 3Section on Experimental Radiology, University Hospital of Tuebingen, Tuebingen, Germany
Synopsis
Active learning aims to reduce the amount of labeled data required to adequately train a classifier by iteratively selecting samples carrying the most valuable information for the training process. In this study, we investigate the influence of redundancy within the batch of selected samples per iteration, aiming to further reduce the amount of labeled data for automated assessment of MR image quality. An SVM and a DNN are trained with images labeled by radiologists according to the perceived image quality. Approaches to reduce redundancy are compared. Results indicate that reducing the intra-batch correlation for SVM needs fewest labeled samples.
Introduction
The quality of acquired medical images has a strong influence on the ability of a MR specialist to successfully answer a diagnostic question. However, MR images are prone to quality degradation due to numerous patient-related or technical factors. Assessment of image quality is thus a crucial task, yet time-consuming when performed manually and not really reproducible due to high intra- and inter-reader variance. To address these issues, automated approaches using a Support Vector Machine (SVM) or Deep Neural Network (DNN) have been proposed in previous studies1,2, achieving a classification accuracy of 91.2% and 92.5%, respectively. To keep the cost for labeling data as low as possible, active learning (AL) was included in the training process2-4, resulting in a reduction of needed training samples by roughly 50%. However, the proposed selection of multiple samples (batch) to be labeled during each AL iteration can lead to adding redundant information to the training data. Consequently, more iterations than necessary are required. To address this issue, methods which reduce intra-batch redundancy can be employed. In this study, we combined AL strategies to train an SVM and a DNN with redundancy reduction methods to investigate, whether further decreasing the labeling cost is possible.Methods
The data set used for training and classification consists of 2911 2D slices from 3D MR images of 100 patients and healthy volunteers, which were categorized into 5 quality classes on a 5-point Likert scale. Labeling was performed blindfolded by 5 experienced radiologists according to the perceived image quality. We extracted 2871 image features, which were reduced via principal component analysis to 36 (SVM) and 96 (DNN) for training. 30% of the labeled samples were reserved for evaluation of the classifier. The random splitting in training and test set was performed 10 times to achieve more robust results.
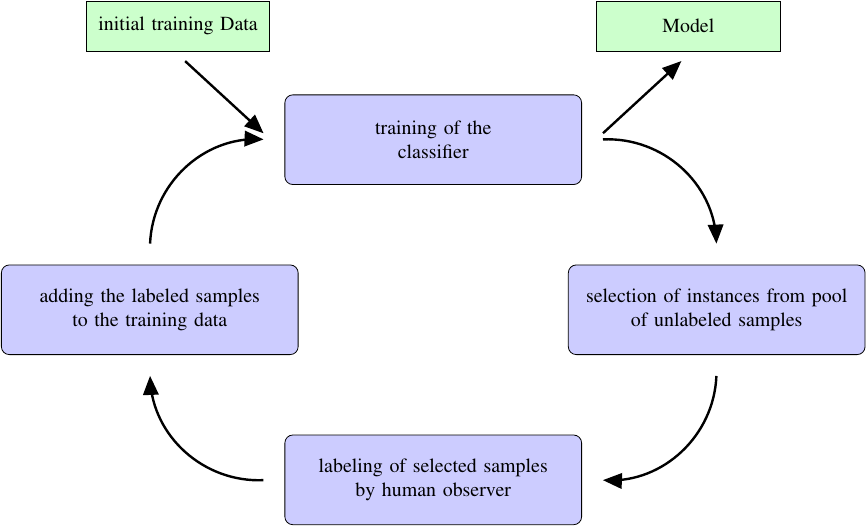
We trained a multi-class soft-margin SVM with radial basis function kernel5. Kernel parameter gamma and soft-margin parameter C have been determined by 10-fold cross validation. The DNN was trained with Theano’s Keras library6, using a multi-layer perceptron with 3 hidden layers, exponential linear unit activation function and softmax output layer. Optimization is performed via a gradient descent method. Fig. 1 depicts, how AL is included in the training process. In this study, we used 50 samples for initial training and a batch-size of 40 samples per iteration.
The effectiveness of AL is mainly determined by the chosen query strategy. We used a probability-based approach (best-vs-second-best, BVSB) for both classifiers, which measures classifier uncertainty by selecting samples, for which the difference between the probability for the most and second most probable classes is minimal7. For the SVM, we also tested a distance-based strategy (DIST) which selects samples closest to the decision boundary3. The approach includes compensation for the SVM’s soft-margin property.
To reduce intra-batch redundancy, a larger batch of samples than actually desired is selected and analyzed by a redundancy assessment algorithm which chooses the subset of selected samples for which redundancy is minimal. We
investigated several redundancy reduction methods. Two of
them showed promising results: minimization of intra-batch
correlation (CORR) and maximization of the information density (ID)8,
which measures the similarity between chosen samples and the whole
data set.
Results
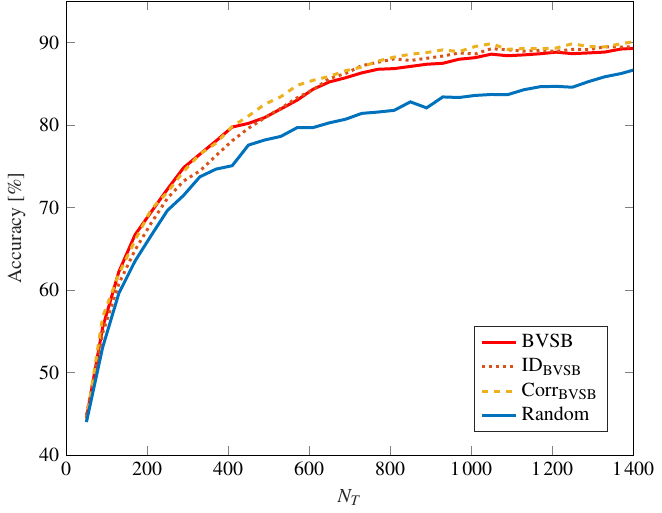
The classification accuracy achieved by training of the DNN is displayed in Fig. 2. Both ID and CORR lead to a slightly faster convergence towards the target accuracy of > 90% than using only BVSB.
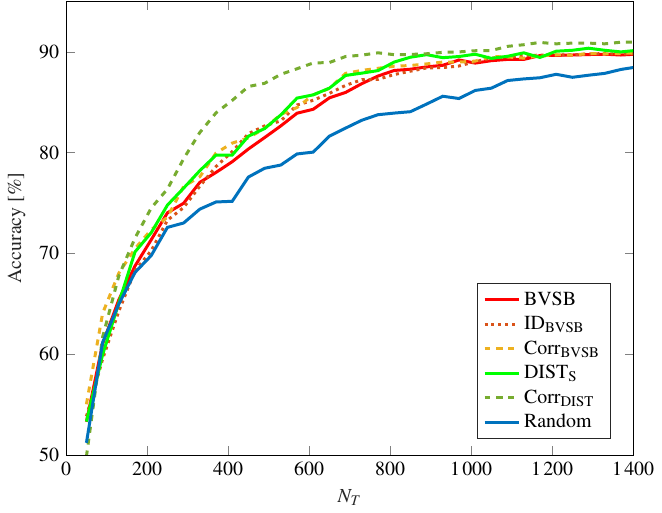
Fig. 3 shows the results for the trained SVM. While the effects of redundancy reduction are minimal when combining these techniques with BVSB, the combination of DIST with CORR leads to significant improvements. Only NT = 770 training samples are needed to achieve 90% accuracy, i.e. 38.8% of the original data set.
Discussion
In this study we investigated the effect of AL intra-batch redundancy on the number of labeled training samples needed to achieve a high test accuracy. While the effect of redundancy reduction on training the DNN is only small, our results for the SVM show that reducing the redundancy of a batch of selected samples by means of correlation analysis, combined with DIST, leads to a reduction of needed training samples by 62.2%. Compared to roughly 50% for AL without redundancy reduction, this is a significant reduction of labeling effort.Conclusion
Active learning is an efficient way to decrease the number of labeled training samples needed to achieve a good accuracy in automated reference-free MR image quality assessment. Reducing the intra-batch redundancy by means of correlation analysis further improves the effect of AL on the training of a SVM/DNN significantly.Acknowledgements
No acknowledgement found.References
1. T. Küstner, P. Bahar, C. Würslin, S. Gatidis, P. Martirosian, NF. Schwenzer, H. Schmidt and B. Yang "A new approach for automatic image quality assessment", Proceedings of the Annual Meeting ISMRM 2015, June 2015, Toronto, Canada.
2. S. Gatidis, A. Liebgott, M. Schwartz, P. Martirosian, F. Schick, K. Nikolaou, B. Yang and T.
Küstner
"Automated reference-free assessment of MR image quality using an active learning approach:
comparison of Support Vector Machine versus Deep Neural Network classification",
Proceedings of the Annual Meeting ISMRM 2017, April 2017, Honolulu, Hawaii, USA.
3. A. Liebgott, T. Küstner, S. Gatidis, F. Schick an B. Yang
"Active Learning for Magnetic Resonance Image Quality Assessment",
Proceedings of the 41th IEEE International Conference on Acoustics, Speech and Signal
Processing ICASSP 2016, March 2016, Shanghai, China.
4. T. Küstner, M. Schwartz, A. Kaupp, P. Martirosian, S. Gatidis, NF. Schwenzer, F. Schick, H.
Schmidt and B. Yang,
"An Active Learning platform for automatic MR image quality assessment",
Proceedings of the Annual Meeting ISMRM 2016, May 2016, Singapore.
5.
C.
Chang and C. Lin, “LIBSVM: A library for support vector machines,”
T. Intell. System. Tech., vol. 2, pp. 1–27, 2011.
6. F. Chollet, "Keras: Deep Learning for Python", Github, https://github.com/fchollet/keras, Accessed: October 2017
7. A. Joshi, F. Porikli und N. Papanikolopoulos, “Multi-class active learning for imageclassification.” in CVPR. IEEE Computer Society, 2009, S. 2372–2379.
8. M. C. B. Settles, “An analyses of active learning strategies for sequence labeling tesks,” in Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2008, S. 1070–1079.
Figures