2835
An efficient facial de-identification method for structural 3D neuroimages1Department of Imaging and Interventional Radiology, The Chinese University of HongKong, SHATIN, Hong Kong
Synopsis
A major challenge to facial de-identification in 3D brain MR images is to find a trade-off between patient privacy protection and retaining the usefulness of the image data. An efficient facial de-identification method is proposed. The method can efficiently conceal identifiable facial details in the 3D brain MR images while maintaining the usefulness of the data. The experimental results indicated the proposed method can achieve the state-of-the-art performance and retain more image data in comparison with the currently available tools.
Introduction
With increasing spatial resolution of MR imaging techniques, it has become possible to reconstruct patients' facial details for recognition from 3D brain MR images. Currently available methods for patients’ identity concealment usually remove a large amount of image voxels during de-identification [1-4]; therefore, compromise the usefulness of the data. This paper presents a novel method for facial de-identification in brain MR images which efficiently obscures the recognizable facial details in the 3D MR images while preserving as much underlying anatomy as possible.Methods
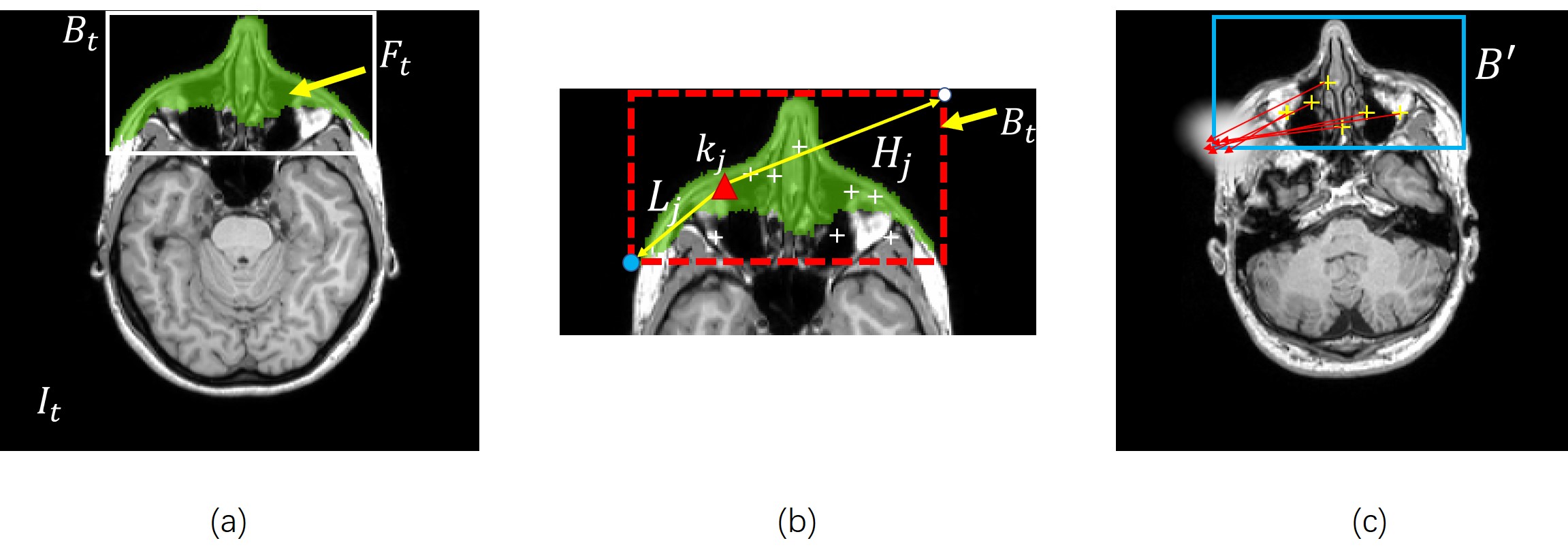
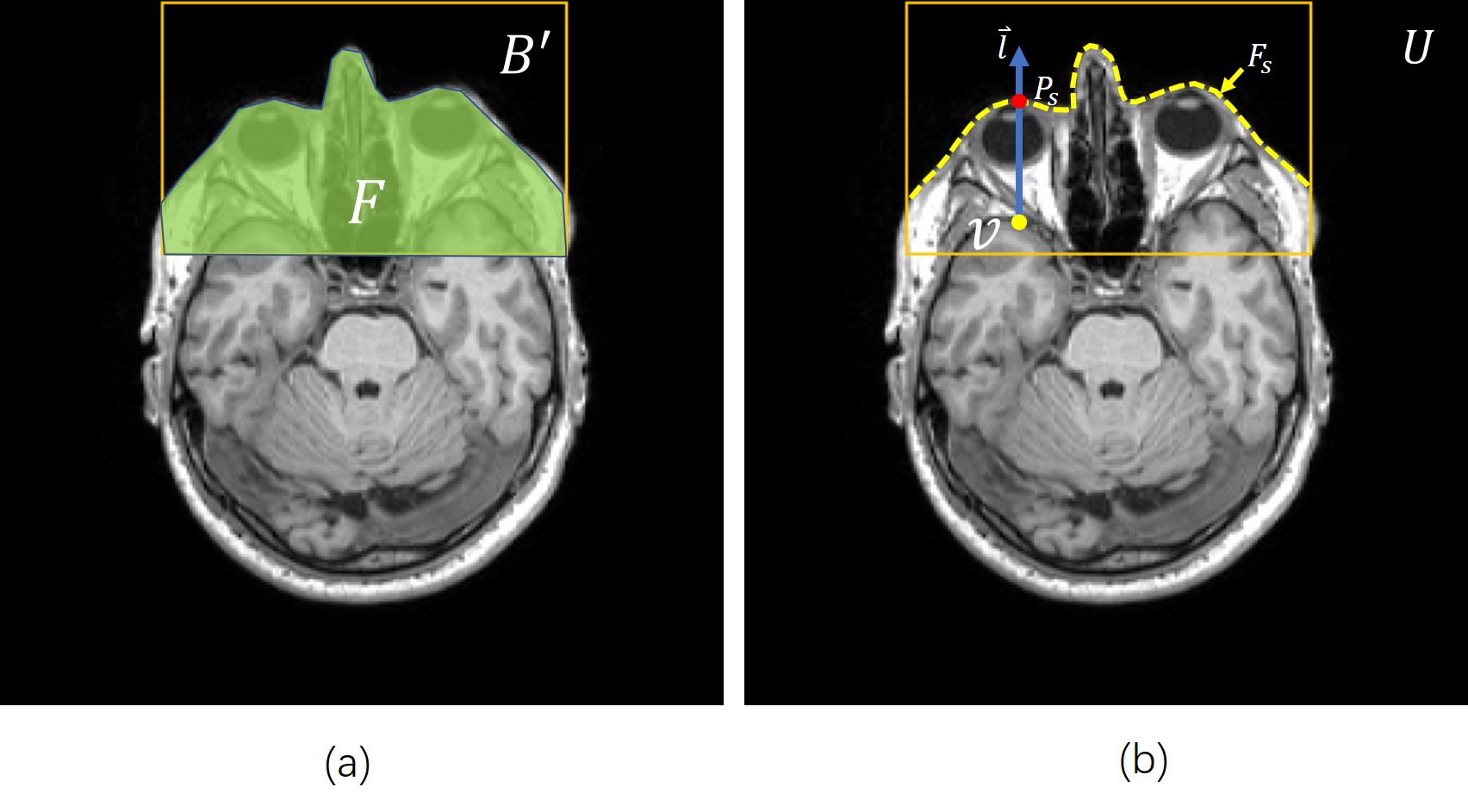
A four-stage procedure is employed to conceal subject’s identity in a novel 3D brain MR image. (1) The image is registered into the same stereotactic space $$$U$$$ with the training images using mutual information based image registration [5][6]. (2) Key-point based deformable models are used to detect subject’s face, as shown (Fig.1). (3) A line searching method is used to extract the superficial surface of the subject’s face (Fig.2). (4) Finally, a surface editing procedure is carried out to obscure subject’s facial details (Fig.3).
To train the key-point based deformable model from $$$t$$$-th training image $$$I_{t}$$$. The facial regions $$$F_{t}$$$ in $$$I_{t}$$$ is delineated by a trained expert (Fig.1a). A group of key points are extracted from the facial region $$$F_{t}$$$ using [7][8](Fig.1b). Here we assume the bounding box that encloses the facial region in $$$I_{t}$$$ is denoted as $$$B_{t}$$$. A deformable face detection model $$$M_{i}=\left\{k;L;U\right\}=\left\{k_{1},k_{2}...;L_{1},L_{2},...;U_{1},U_{2},...\right\}$$$ can be trained from $$$I_{t}$$$. Here, $$$k_{j}$$$ is the spatial position of $$$j$$$-th key-point in $$$I_{t}$$$, $$$L_{j}$$$ is the relative displacement between $$$j$$$-th key-point and the lowest point of $$$B_{t}$$$. $$$H_{j}$$$ is the relative displacement between $$$j$$$-th key-point and the upper most point of $$$B_{t}$$$(Fig.1b). To use $$$M_{i}$$$ to detect subject’s face in a novel image, we first match the key points in the novel image, and using the relative displacement between each key-point and the facial bounding box as a prior knowledge to determine the possible bounding box position in that image (Fig.1c). Multiple deformable models and the multi-criterion decision making method [9][10] are used to fuse the detection results for facial bounding box in the novel image (Fig.2a).
A line searching method is used to identify the superficial surface of subject's face (Fig.2b). The image volume within $$$B^{'}$$$ was segmented into facial region $$$F$$$ and non-facial region $$$NF$$$. A line searching was performed at each voxel position in $$$F$$$, along the direction $$$\overrightarrow{l}$$$ which points from posterior to anterior in the normalized space $$$U$$$. The position of the superficial point $$$P_{s}$$$ on subject's face $$$F_{s}$$$ can be determined by the position of the last intersecting point between the searching line and the regional boundary of $$$F$$$ (Fig.2b).
To obscure the facial details on $$$F_{s}$$$, a surface editing procedure is carried out. $$$F_{s}$$$ was down-sampled by skipping every 3 voxels. The sub-sampled facial surface was denoted as $$$D_{s}$$$. In the cubic regions around each vertex on $$$D_{s}$$$ (Fig.3d), image voxel values were set to zero to obscure subject’s facial details.
Results
The method was tested on a
dataset of 30 T1-w brain MR images selected from IXI database [11].
Firstly, visual inspection was performed
by a trained expert and indicated the underlying brain anatomy retained
unchanged and all the recognizable facial features were adequately obscured after
de-identification. Secondly, the percentage of image voxel loss during facial
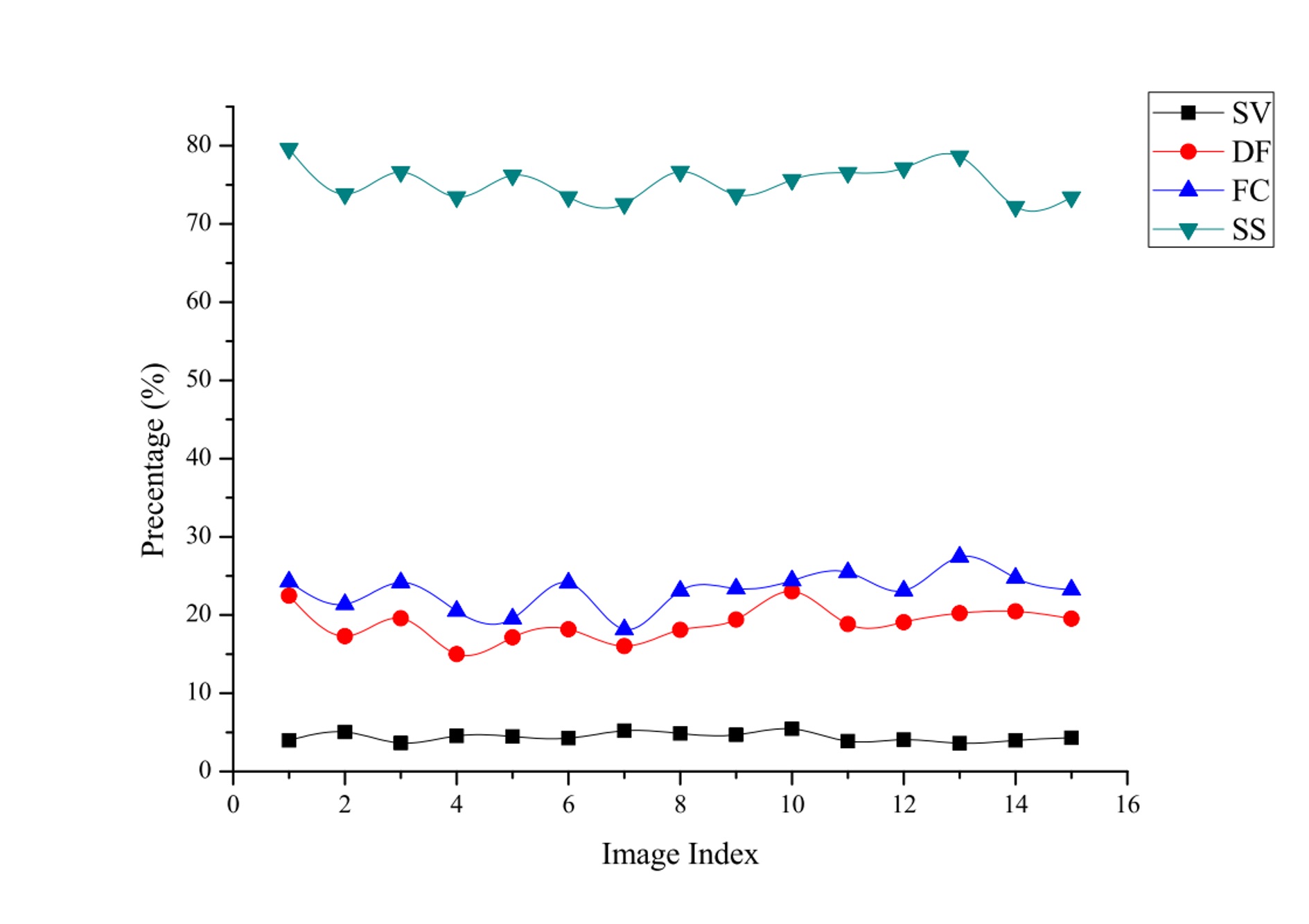
de-identification was calculated. Experimental results (Fig.4) indicate that
the percentage of image voxel loss for our method was 4.39% in average. Comparison
has been made between our method and three other methods [1-3]. The average image voxel loss for
defacing method was 18.95%. The face culling method was 23.13%, and the skull
stripping method was 73.5%. A Mann-Whitney test was used to verify the
hypothesis that our method can retain significantly more image voxels than all
the other methods ($$$p$$$<0.001).Thirdly, we quantitatively
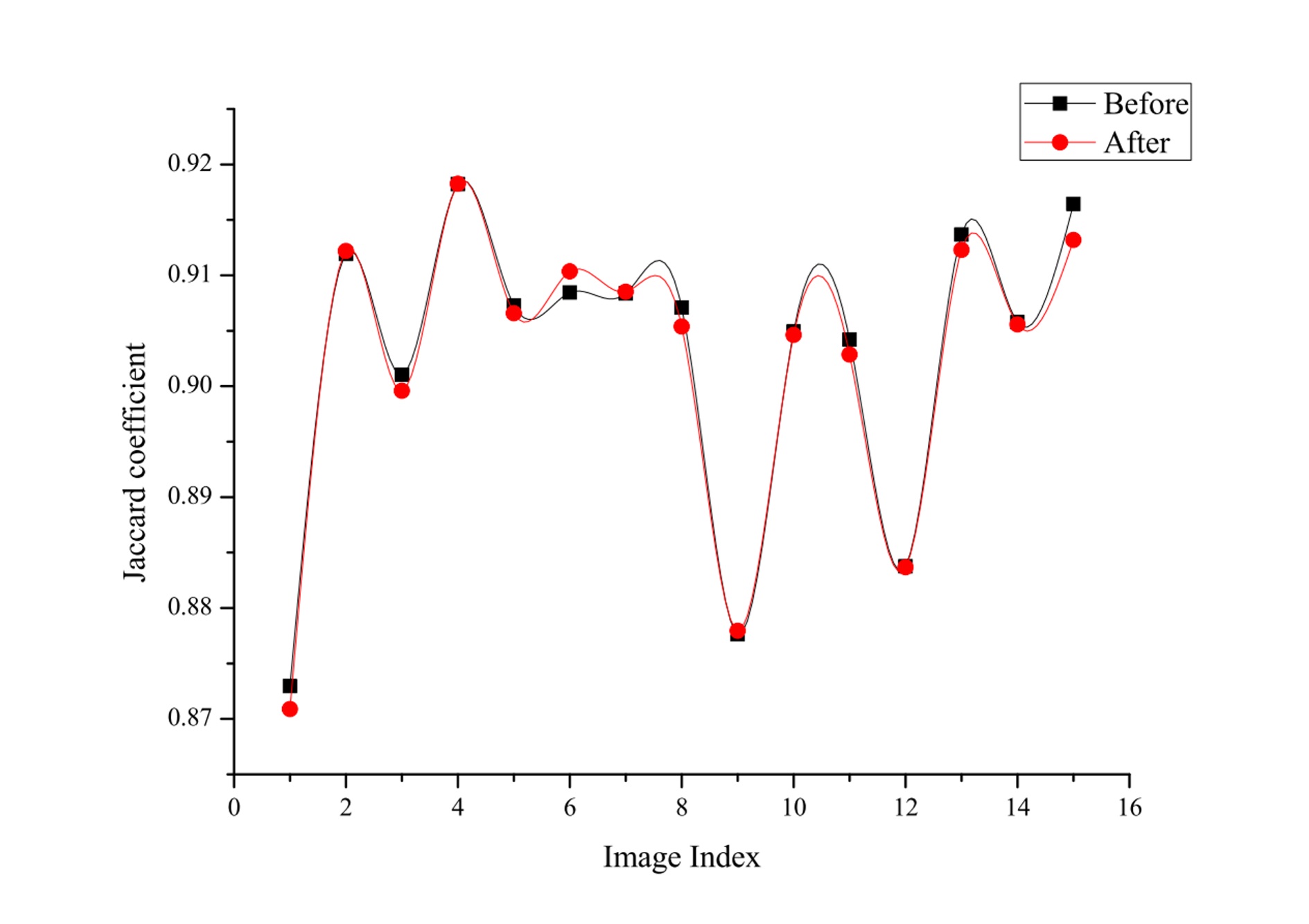
assess whether the proposed method influenced the performance of frequently
used brain MR post-processing toolkits. Comparison was made to evaluate how the
proposed method may influence the automated performance of the Brain Extraction
Toolkit (BET) [1]. A Wilcoxon
Signed Ranks test was performed to verify the hypothesis that our method dose
not appreciably impact the outcome of BET ($$$p$$$=0.061).Conclusion
To our best knowledge, none of the conventional approaches has be ability to accurate identify the superficial surface of subject’s face, therefore, removal of non-facial voxels is inevitable. The experimental results indicated the proposed data-driven method can be trained applied to de-identify MR images without significant manual intervention. The proposed method should be of interest to the researchers who intends to share the MR data to public domain.Acknowledgements
This study is supported by the grant from the Research Grants Council of the Hong Kong SAR (Project No. SEG CUHK02).References
[1]Smith, S.M., Fast robust automated brain extraction. Human brain mapping, 2002. 17(3): p. 143-155.
[2] Bischoff‐Grethe, A., et al., A technique for the deidentification of structural brain MR images. Human brain mapping, 2007. 28(9): p. 892-903.
[3] Gan, K. and D. Luo, Facial De-Identification in Multimodality MR Images. Transactions of Japanese Society for Medical and Biological Engineering, 2013. 51(Supplement): p. R-238-R-238.
[4] Schimke, N. and J. Hale. Quickshear defacing for neuroimages. in Proceedings of the 2nd USENIX conference on Health security and privacy. 2011. USENIX Association.
[5]Viola, P. and W.M. Wells III, Alignment by maximization of mutual information. International journal of computer vision, 1997. 24(2): p. 137-154.
[6]Collignon, A., et al. Automated multi-modality image registration based on information theory. in Information processing in medical imaging. 1995.
[7]Rohr, K., On 3D differential operators for detecting point landmarks. Image and Vision Computing, 1997. 15(3): p. 219-233.
[8] Gan, K. Automated localization of anatomical landmark points in 3D medical images. in 2015 IEEE International Conference on Digital Signal Processing (DSP). 2015. IEEE.
[9]Hwang, C.L.; Yoon, K. (1981). Multiple Attribute Decision Making: Methods and Applications. New York: Springer-Verlag.
[10]Sodhi, B. and P. T V, A simplified description of Fuzzy TOPSIS. arXiv preprint arXiv:1205.5098, 2012.
[11] IXI database. http://brain-development.org/ixi-dataset/
Figures