2795
Improved Synthetic MRI from Multi-echo MRI Using Deep Learning1Electrical Engineering, Stanford University, Stanford, CA, United States, 2GE Healthcare, Menlo Park, CA, United States, 3Radiology, Stanford University, Stanford, CA, United States
Synopsis
Synthetic MRI enables reconstruction of multiple MRI contrasts from a single (multi-echo) scan which significantly improves scanning efficiency. However, the existing state-of-the-art voxel-wise model-fitting method is not optimal. The model-fitting method often results in inaccurate parameter estimation and undesired artifacts, especially for T2-FLAIR synthesis as shown in clinical studies. Here a deep learning method is proposed to improve the contrast synthesis from multi-delay multi-echo MR imaging. With T2-FLAIR synthesis as an example, the proposed method outperforms existing model-fitting based method to overcome artifacts and improve synthesis accuracy. The proposed method is an essential component for delivering reliable and accurate synthetic MRI, further accelerating scanning and improving quantitative parameter mapping.
Introduction
Synthetic MRI [1] enables reconstruction of MR images with multiple tissue contrasts from a single scan, significantly reducing scan time and potentially providing new biomarkers by generating and fusing more contrasts. In one such method, a pre-defined signal model is used to compute multiple tissue relaxation parameters by fitting to a multi-delay multi-echo acquisition signal on a voxel-by-voxel basis. Therefore, any arbitrary contrast can then be derived based on the parameter maps [1].
Studies have shown the applicability of synthetic MRI for clinical brain scans [2-3]. However, the synthetic method remains more sensitive to effects such as partial volume and flow artifacts, resulting in several limitations compared with the conventional acquisition as gold standard:
* 1) The synthesized contrasts may appear different than expected contrast from the conventional acquisition which requires training for radiologists.
* 2) Sequence-specific artifacts are visible such as incomplete CSF suppression and pseudo-edge enhancement on T2-fluid attenuated inversion recovery (FLAIR) images.
Here we propose a deep learning based method for MRI contrast (e.g. T2-FLAIR) synthesis with better synthesis accuracy, improved image quality and reduced artifacts.
Method
- Experiments and Datasets
As a part of prospective multi-reader multi-case non-inferiority trials, 9 datasets were acquired [2] consisting of conventional 2D fast-spin-echo (FSE) based images (T1, T2, T1-FLAIR and T2-FLAIR etc.) and corresponding synthetic MRI contrasts. The synthetic MRI contrasts were generated from a 2D FSE based multi-saturation-delay multi-echo (MDME) acquisition with 4 saturation delays and 2 echoes [4], using the Magnetic Resonance Image Compilation method [2] for parameter fitting and contrast synthesis.
The goal of this work was to improve the synthesis of conventional MRI contrasts, with T2-FLAIR as an example, from the MDME source images. Conventionally acquired T2-FLAIR was used as the gold standard reference.
- Deep Learning Model
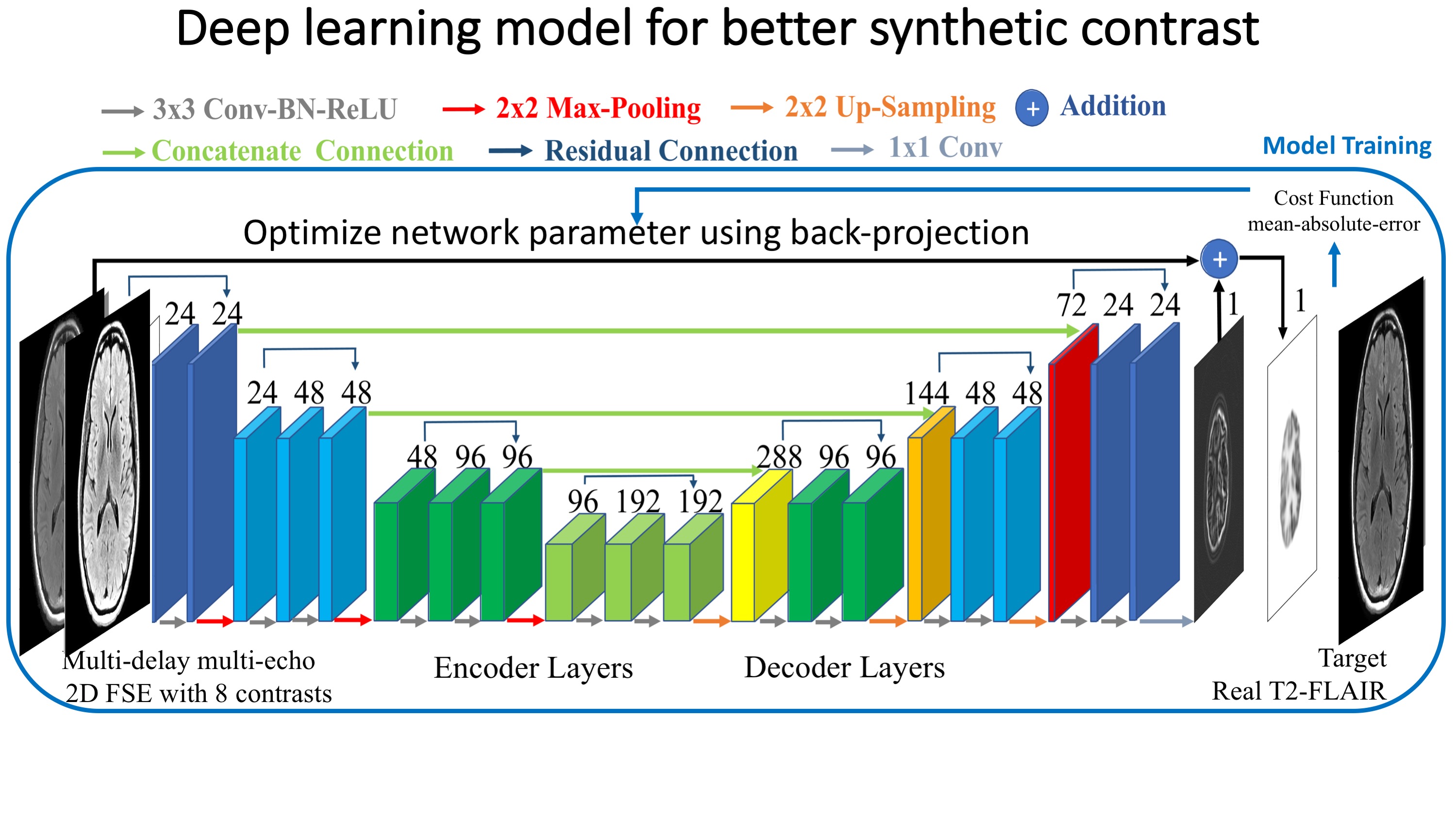
Here we trained a deep learning model to approximate real T2-FLAIR images from the MDME images. As shown in figure 1, we trained a multi-scale convolutional neural network (CNN) with an encoder-decoder structure [5,6], in which there are 3 encoder/decoder modules consisting of 3 convolutional layers in both encoding stage and decoding stage, and there is a downsampling/upsampling layer at the end of each module connected to the next module. Concatenated connections and residual connections are used to improve the reconstruction accuracy and restore resolution information.
- Evaluation
A cross-validation analysis was used to evaluate the performance of the proposed method on new datasets. Multiple models were trained and the overall performance was evaluated. Each model was trained on around 1900 different samples, which includes paired inputs and output at 26~30 planes from 8 subjects with 8 types of data augmentation using rigid transformation to avoid overfitting. Then the model was applied to the other untrained dataset, whose result represents the performance of the trained deep learning model to a new dataset.
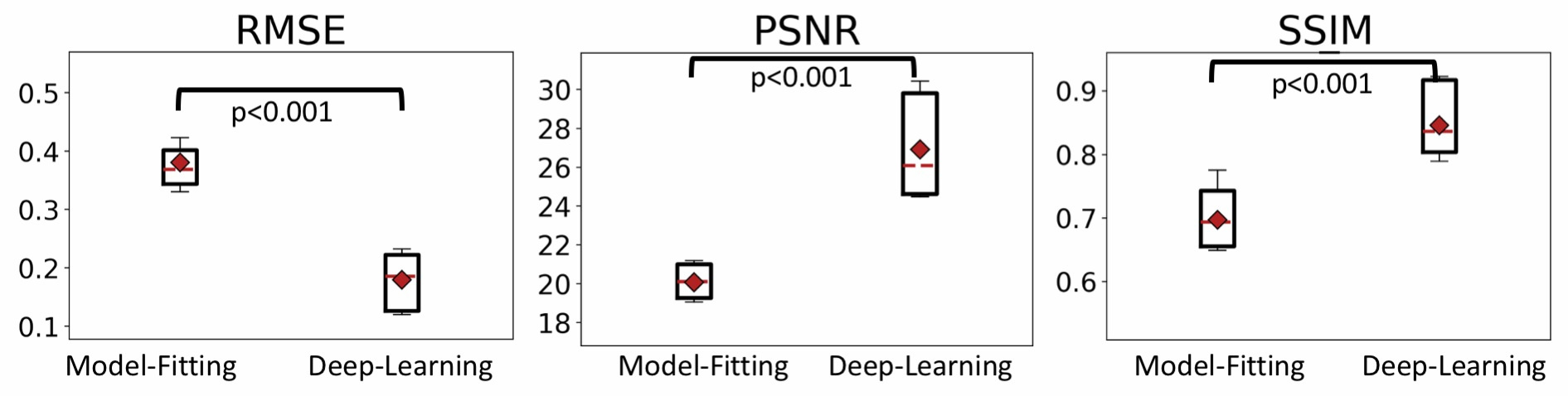
Metrics including Root-Mean-Squared-Error (RMSE), Peak-Signal-to-Noise-Ratio (PSNR) and Structural-Similarity-Index (SSIM) were used to evaluate the performance of the contrast synthesis methods: the proposed deep learning based contrast synthesis method and existing model-fitting based contrast synthesis method.
Results
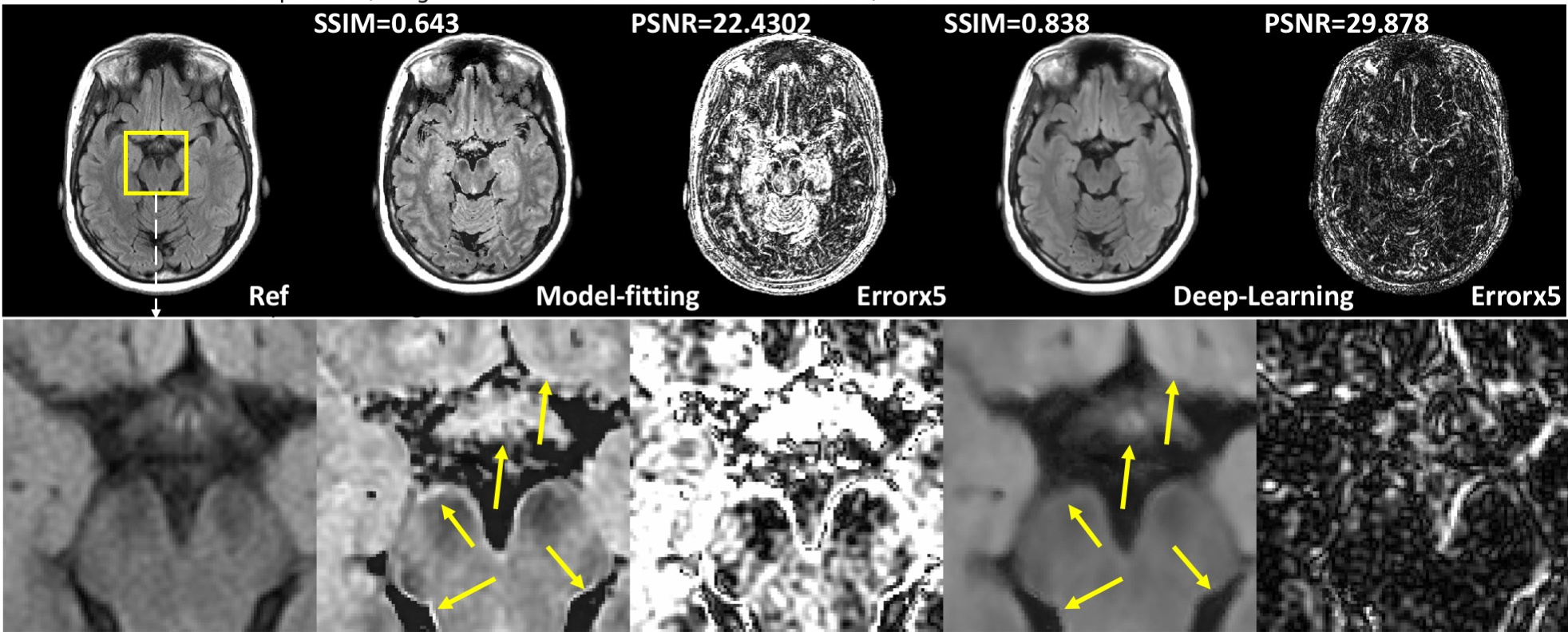
Compared with the model-fitting contrast synthesis, the proposed data-driven deep learning solution demonstrates superior performance with improved accuracy (quantitatively compared with acquired T2-FLAIR images) and reduced artifacts (from qualitative visual assessments). Detailed metrics comparison is shown in Table 1 and sample results are shown in figure 2 . Previously reported artifacts, such as incomplete suppression and pseudo-edge enhancement, are significantly reduced by using the data-driven deep learning method for contrast synthesis, as shown in visual comparison in figure 2 and quantitative comparison using figure 3.Discussion
T2-FLAIR, as shown in clinical studies, is one of the most challenging contrasts to accurately synthesize. The existing model-fitting methods often result in recognizable artifacts which prevent its clinical application. As shown in results, the deep learning method demonstrates both improved accuracy and reduced artifacts for synthesizing T2 FLAIR, which is a necessary step to ensure reliable clinical applications of synthetic MRI.
In addition, similar methods can be applied to improve the synthesis of other contrasts that cannot be directly estimated from signal models, such as T2*, susceptibility information and more accurate parameter mapping, by incorporating non-local information and better designed acquisitions.
Conclusion
A deep learning method is proposed to improve the contrast synthesis from multi-delay multi-echo MR imaging. With T2-FLAIR as an example, the proposed method outperforms existing model-fitting based method and demonstrates reduced artifacts and improved synthesis accuracy. The proposed method is an essential component for reliable and accurate synthetic MRI, further accelerating imaging and improving quantitative parameter mapping.Acknowledgements
No acknowledgement found.References
- Warntjes JB et al, Rapid Magnetic Resonance Quantification on the Brain Optimization for Clinical Usage, Magn Reson Med 2008; 2:320-9
- Tanenbaum, L. N., Tsiouris, A. J., Johnson, A. N., Naidich, T. P., DeLano, M. C., Melhem, E. R., ... & Field, A. S. (2017). Synthetic MRI for Clinical Neuroimaging: Results of the Magnetic Resonance Image Compilation (MAGiC) Prospective, Multicenter, Multireader Trial. American Journal of Neuroradiology, 38(6), 1103-1110. Chicago
- Granberg T, Uppman M, Hashim F, Cananau C, Nordin LE, Shams S, Berglund J, Forslin Y, Aspelin P, Fredrikson S, Kristoffersen-Wiberg M. Clinical Feasibility of Synthetic MRI in Multiple Sclerosis: A Diagnostic and Volumetric Validation Study., AJNR Am J Neuroradiol. 2016 Jun;37(6):1023-9
- Hwang KP et al, Fat-water separation in a rapid quantitative mapping sequence, ISMRM 22nd Annual Meeting, Milan, Italy, 2014, #3201
- Chen, H., Zhang, Y., Kalra, M. K., Lin, F., Liao, P., Zhou, J., & Wang, G. (2017). Low-Dose CT with a Residual Encoder-Decoder Convolutional Neural Network (RED-CNN). arXiv preprint arXiv:1702.00288.
- Gong, E. Pauly, J. Zaharchuk, G. (2017) Boosting SNR and/or Resolution of Arterial Spin Label (ASL) imaging using Multi-contrast Approaches with Multi-lateral Guided Filter and Deep Networks, ISMRM 2017
Figures