2789
Accelerated EPI DWI using a Deep-learning-based Reconstruction.1Center for Biomedical Imaging Research, Department of Biomedical Engineering, School of Medicine, Tsinghua University, Beijing, China, 2Vascular Imaging Laboratory, Department of Radiology, University of Washington, Washington, WA, United States
Synopsis
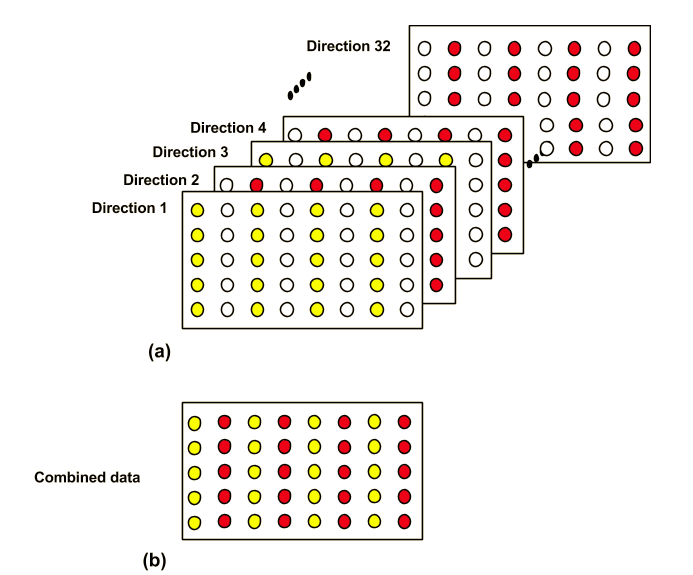
In this work, we preliminarily demonstrate the deep-learning-based reconstruction can be used for under-sampled diffusion imaging. By integrating the sharable information from multiple diffusion directions, the under-sampled data can be nicely recovered.
Purpose
Scan speed is a critical issue in MRI. Partially parallel acquisition (PPA) can be used to accelerate the acquisition of k-space and thus save imaging time. Currently, there are many PPA reconstruction methods based on information redundancy in phase coil arrays, such as SENSE and GRAPPA(1-4). However, the main problem of these methods is the degradation of SNR, especially at a high acceleration factor. Recently, attempts based on deep learning models have been made on under-sampled T1 or T2 weighted structure image(5). However, there is only limited reports about applying deep learning models for diffusion weighted (DW) imaging acceleration. Accelerating DW imaging may be more challenging than structure imaging, as DW images usually shows low SNR and geometric distortion. In this study, a deep-learning-based framework is proposed the reconstruction of under-sampled diffusion data. Additionally, when applying many diffusion encoding directions (such as diffusion tensor imaging), there will sharable information among different diffusion encoding directions(6). There sharable information is also integrated into the proposed framework to enhanced the final results.Methods
Acquisition In vivo brain data were acquired on a Philips 3.0T Achieva TX MRI scanner (Philips Healthcare, Best, The Netherlands) using a 32-channel head coil. Three volunteers were included in this study. A 4-shot interleaved EPI (iEPI) sequence with a 2D navigator was used(7). Diffusion encoding was applied along 32 directions with b=800 s/mm2. The diffusion encoding directions were uniformly distributed on a hemisphere [HG1] in q-space. The main imaging parameters were: FOV=207×207×96 mm3, voxel size=1.2×1.2 mm2, slice thickness=4 mm, no partial Fourier, TE=86 ms, TR=4.2 s. GRAPPA with a compact kernel (GRAPPA-CK)(8) was used to correct inter-shot phase variations and reconstruct the image of each shot and channel. After that, the images were combined to generate the final DW images, which were used as references.
Simulation and preprocessing The reconstructed image of each shot and channel were complex averaged along the shot dimension to remove the phase errors among different shots. The newly generated image of each channel were Fourier transformed to k-space and manually 2-fold under-sampled. Note that this actually simulate the accelerated acquisition of single shot EPI (ssEPI). 4-shot iEPI was used in the acquisition mainly for SNR and geometric distortion consideration. To compare with the traditional acceleration in multi-shot EPI, 2 out of 4 shots was extracted from the originally acquired data. Then the same GRAPPA-CK reconstruction procedure was conducted(8).
Deep learning framework In this deep learning model, we need to solve the aliasing artifacts as well as recover the missing data from different diffusion directions. We proposed a model based on Generative Adversarial Networks (GAN)(6). GAN includes two parts, which are generator network G and discriminator network D. In generator network, we used U-net as the model. The framework is shown in Fig.2. Vgg 16 was used for calculating content loss. It can make image more realistic. We used two sets of diffusion-weighted images as training data while the other set of diffusion-weighted images as testing data.
Loss function Before k-space sharing layers, the outputs of U-net should be similar with the reference images. Thus, we minimized the loss between outputs after U-net and reference images, which is L_middle. After a few of epochs, we minimized the total loss which can be written as:
$$L_{total}=α\cdot{L_{middle}}+β\cdot{L_{image}}+L_{D}+γ\cdot{L_{feature}}$$
Lmiddle is the loss between reference images and outputs of U-net. Limage is the loss between reference images and outputs of k-space sharing layers. Lfeature is the content loss.
Results and Discussion
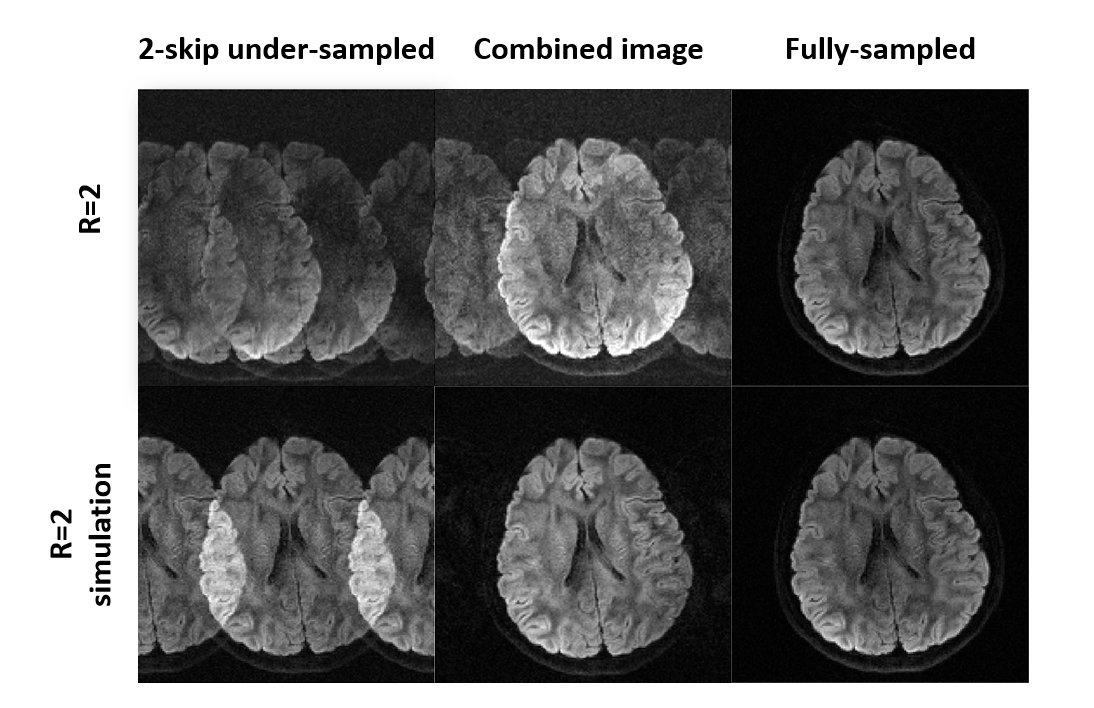
Fig 3. shows the fully-sampled images, deep-learning reconstructed images, and GRAPPA-reconstructed images. The aliasing artifacts are obvious before we combined different directions. Fig 4. shows that reconstructed images from our proposed method and GRAPPA-based method. The noise in our proposed method is not as serious as that in GRAPPA-based method. What’s more, in some directions, GRAPPA-based can’t reconstruct images well. However, those data are simulation data. In MRI, we need further validation for real data. Thus, we used the same model but training the model with undersampled real data. The result is shown in Fig 4. Since the phase errors are not only caused by aliasing, but also the motion. Therefore, some directions can't be reconstructed well. And the images are blurring. However, it still shows that deep-learning-based model can accelerated EPI DWI acquisition.Conclusion
In this study, we preliminarily demonstrate the deep-learning-based reconstruction for accelerated diffusion imaging. By integrating the sharable information from multiple diffusion directions, the under-sampled data can be recovered. When extending the proposed method to multi-shot acquired data, inter-shot phase variations should be considered(9,10). Additionally, the proposed method may also be applicable for reconstructing simultaneous multi-slice (SMS) accelerated multi-shot diffusion imaging(11).Acknowledgements
No acknowledgement found.References
1. Weiger M, Pruessmann KP, Boesiger P. 2D SENSE for faster 3D MRI. MAGMA 2002;14:10-19. 2. Blaimer M, Breuer FA, Mueller M, Seiberlich N, Ebel D, Heidemann RM, Griswold MA, Jakob PM. 2D-GRAPPA-operator for faster 3D parallel MRI. Magn Reson Med 2006;56:1359-1364.
3. Lustig M, Pauly JM. SPIRiT: Iterative self‐consistent parallel imaging reconstruction from arbitrary k‐space. Magn Reson Med 2010;64:457-471.
4. Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, Vasanawala SS, Lustig M. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn Reson Med 2013:n/a-n/a.
5. Simiao Yu et al. Deep De-Aliasing for Fast Compressive Sensing MRI. arXiv, 2017, 1703.001120.
6. Shi X, Ma X, Wu W, Huang F, Yuan C, Guo H. Parallel imaging and compressed sensing combined framework for accelerating high-resolution diffusion tensor imaging using inter-image correlation. Magn Reson Med 2015;73:1775-1785.
7. Dai E, Ma X, Zhang Z, Yuan C, Guo H. The Effects of Navigator Distortion Level on Interleaved EPI DWI Reconstruction: A Comparison Between Image and K-Space Based Method. In Proceedings of the 24th Annual Meeting of ISMRM, Singapore, 2016. Abstract 0208.
8. Ma X, Zhang Z, Dai E, Guo H. Improved multi-shot diffusion imaging using GRAPPA with a compact kernel. Neuroimage 2016;138:88-99.
9. Anderson AW, Gore JC. Analysis and correction of motion artifacts in diffusion weighted imaging. Magn Reson Med 1994;32:379-387.
10. Miller KL, Pauly JM. Nonlinear phase correction for navigated diffusion imaging. Magn Reson Med 2003;50:343-353.
11. Barth M, Breuer F, Koopmans PJ, Norris DG, Poser BA. Simultaneous multislice (SMS)
Figures