2772
Quantitative Synthetic T1 Mapping of the Brain from Structural Imaging using Deep Learning1Radiology, University of Wisconsin, Madison, WI, United States, 2Neuroscience, University of Wisconsin, Madison, WI, United States, 3Medicine, University of Wisconsin, Madison, WI, United States
Synopsis
We propose a method to generate synthetic T1 maps directly from conventional T1-weighted imaging. Rather than rely on fitting an explicit signal model or precomputing a dictionary from a closed form equation (e.g. Bloch equations or extended phase graph), we employ deep learning combined with training data from variable flip angle (VFA) T1 mapping experiments to generate an implicit machine learning model of T1 signal. The use of deep learning to enable quantitative imaging directly from an acquired T1-weighted image is a provocative approach with promising capability, as demonstrated herein with less than 3% error compared to a VFA approach.
Introduction
In contrast to conventional T1-weighted imaging, which presents images scaled in arbitrary units and is confounded by multiple effects, including receiver coil sensitivity profiles, transmit (B1) field inhomogeneity, and changes in proton density, quantitative T1 mapping generates images on an absolute scale (relaxation time in seconds) that are free from confounds, enabling a more straightforward biological interpretation of measured differences.
In this work, we propose a method to generate synthetic T1 maps from conventional T1-weighted imaging. Rather than rely on fitting an explicit signal model or precomputing a dictionary from a closed form equation (e.g. Bloch equations or extended phase graph), we employ deep learning combined with training data from variable flip angle (VFA) T1 mapping experiments to generate an implicit machine learning model of T1 signal.
Methods
Retrospective MR image data from 73 adult subjects were obtained from a registry of cognitively normal adults who are followed longitudinally and comprise a cohort whose members either have a family history of late onset Alzheimer’s disease or no family history of Alzheimer’s disease [1]. T1-weighted imaging (BRAVO) was acquired in the axial plane using the following parameters: TI = 450 ms; TR = 8.1 ms; TE = 3.2 ms; flip angle = 12°; acquisition matrix = 256×256×156 mm, FOV = 260 mm; and slice thickness = 1.0 mm. 3D VFA T1 mapping images were obtained using the parameters described in [2]. All images were acquired on a 3T MRI scanner (MR750, GE Healthcare). T1 maps were calculated from VFA data as described in [2]. T1-weighted images and T1 maps were resampled to the same 1.4mm isotropic pixel space and approximately aligned to the AC-PC line using a rigid-body transformation.
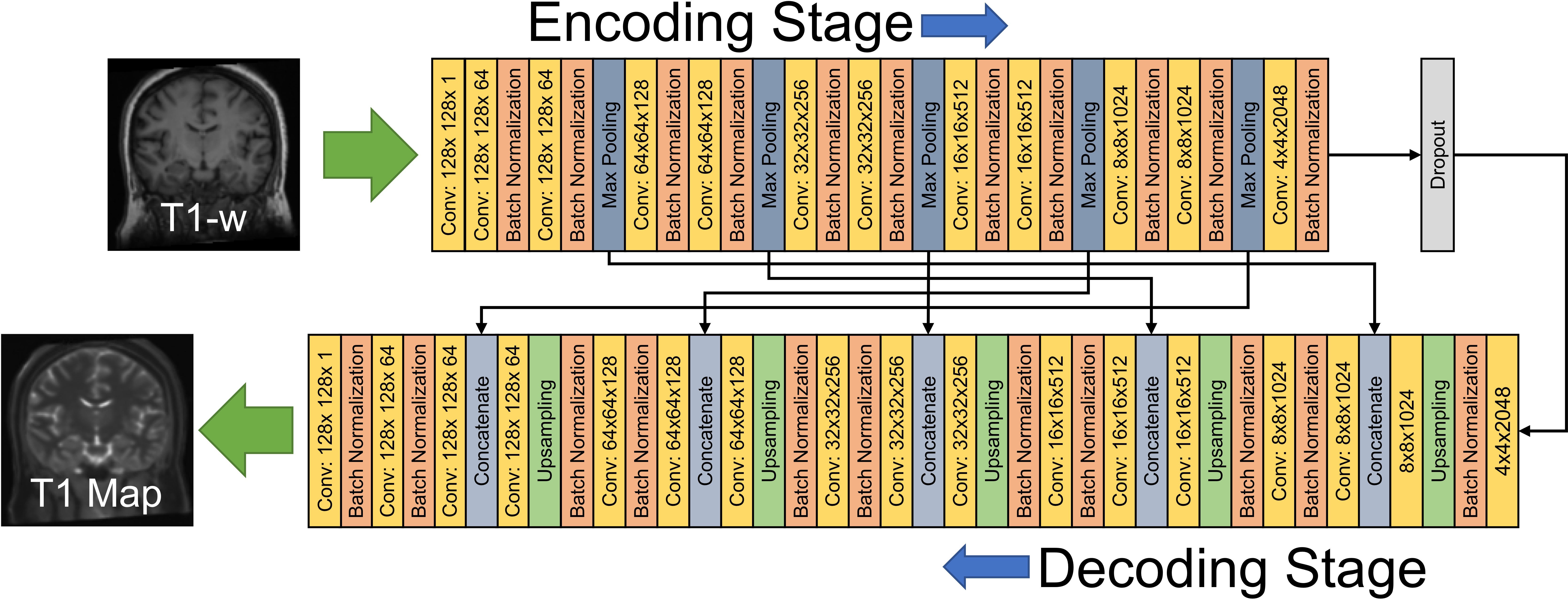
Deep learning employed a convolutional encoder-decoder (CED) model based on Unet [3] built in Keras [5] to map input T1-weighted images to VFA T1 maps. A schematic of the model is shown in Figure 1. 65 subjects were randomly selected to be included in the training dataset and 8 subjects (who were not included in training) were selected for evaluation of the trained model. Training was performed on a GPU workstation (GTX1080, NVIDIA, Santa Clara, CA) using 100 epochs and a batch size of 16. Training required approximately 10 hours, evaluation required less than 10 seconds per volume.
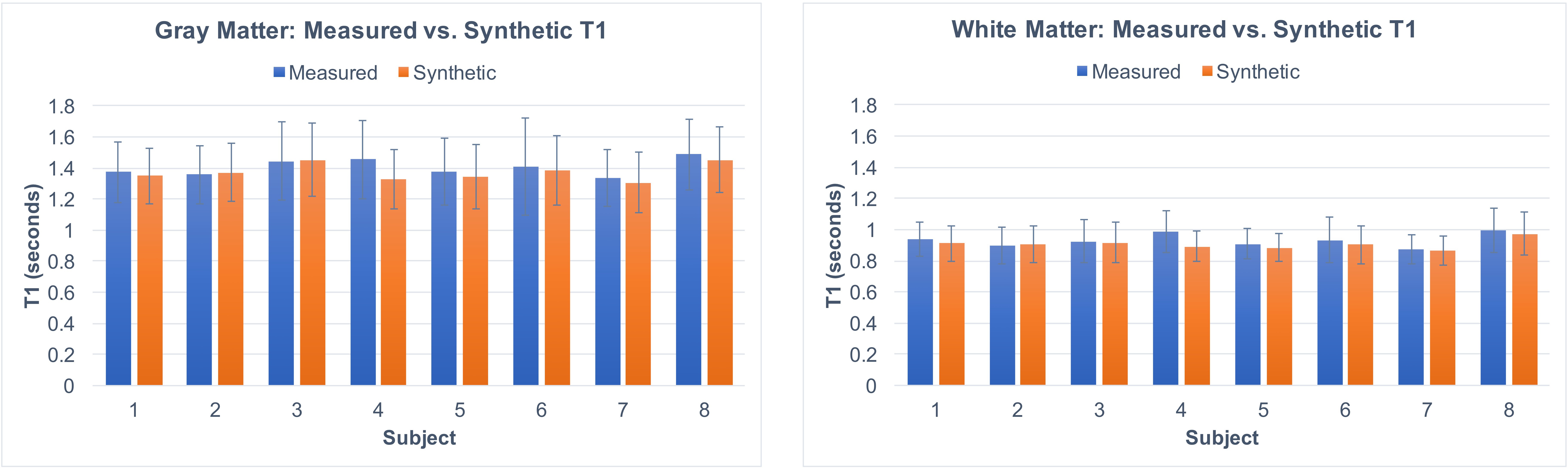
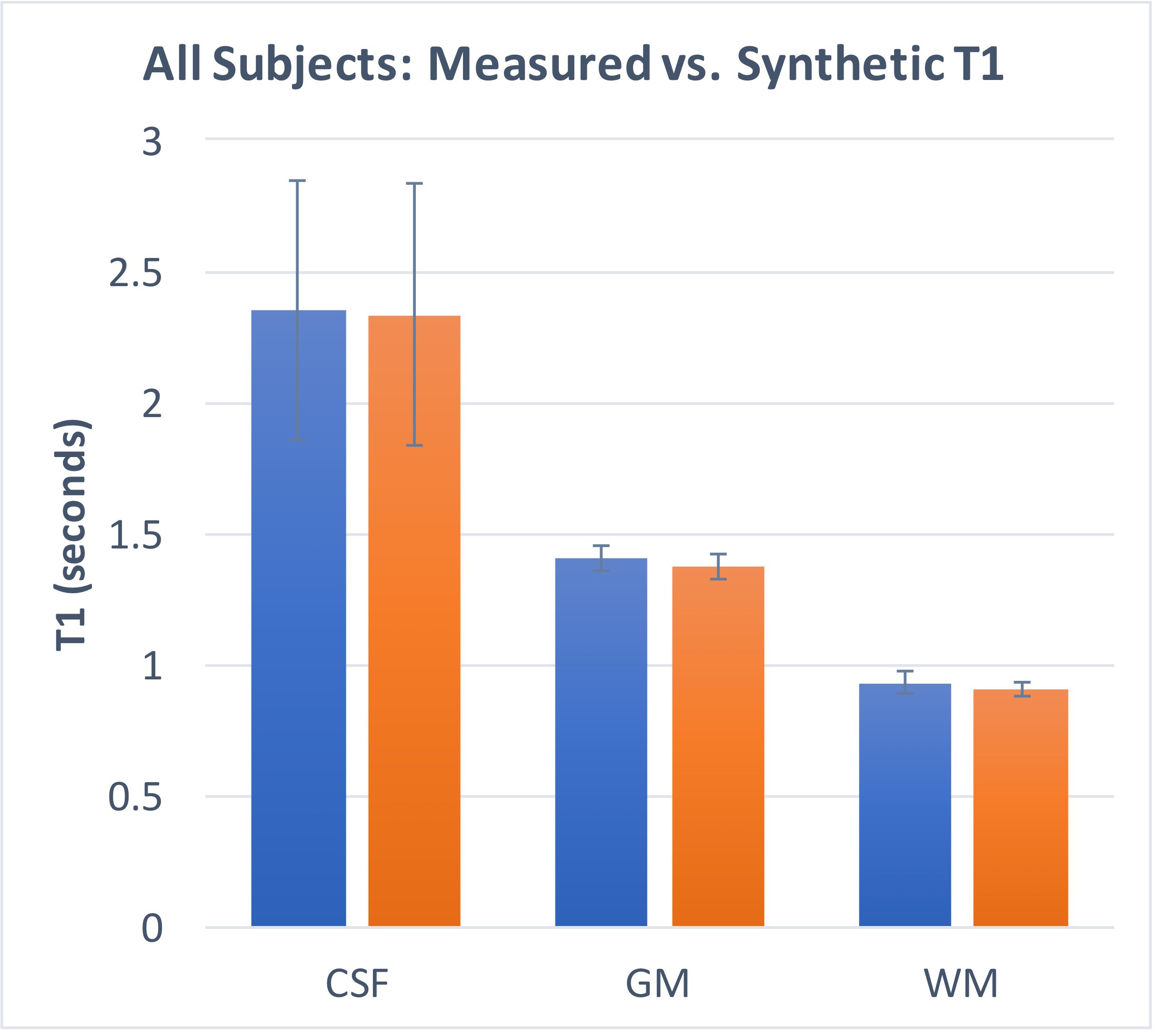
To compare quantitative output of the synthesized with the measured T1 maps, T1-weighted input images were brain extracted and segmented (into cerebral spinal fluid [CSF], gray matter [GM], and white matter [WM]) probabilistic maps using FSL FAST [4], thresholded, and eroded by 1 voxel. The resulting tissue masks were then used to compute whole-brain averages of T1 values.
Results
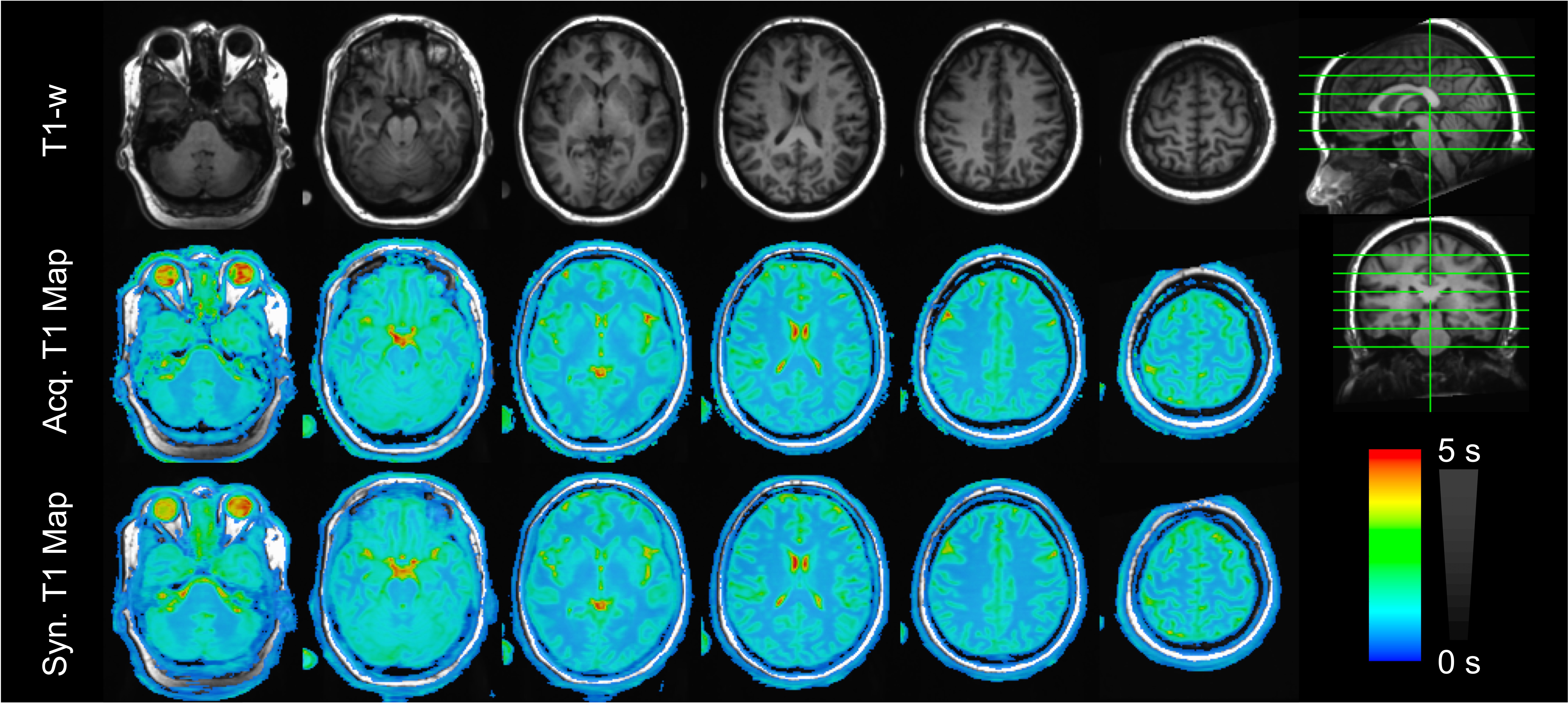
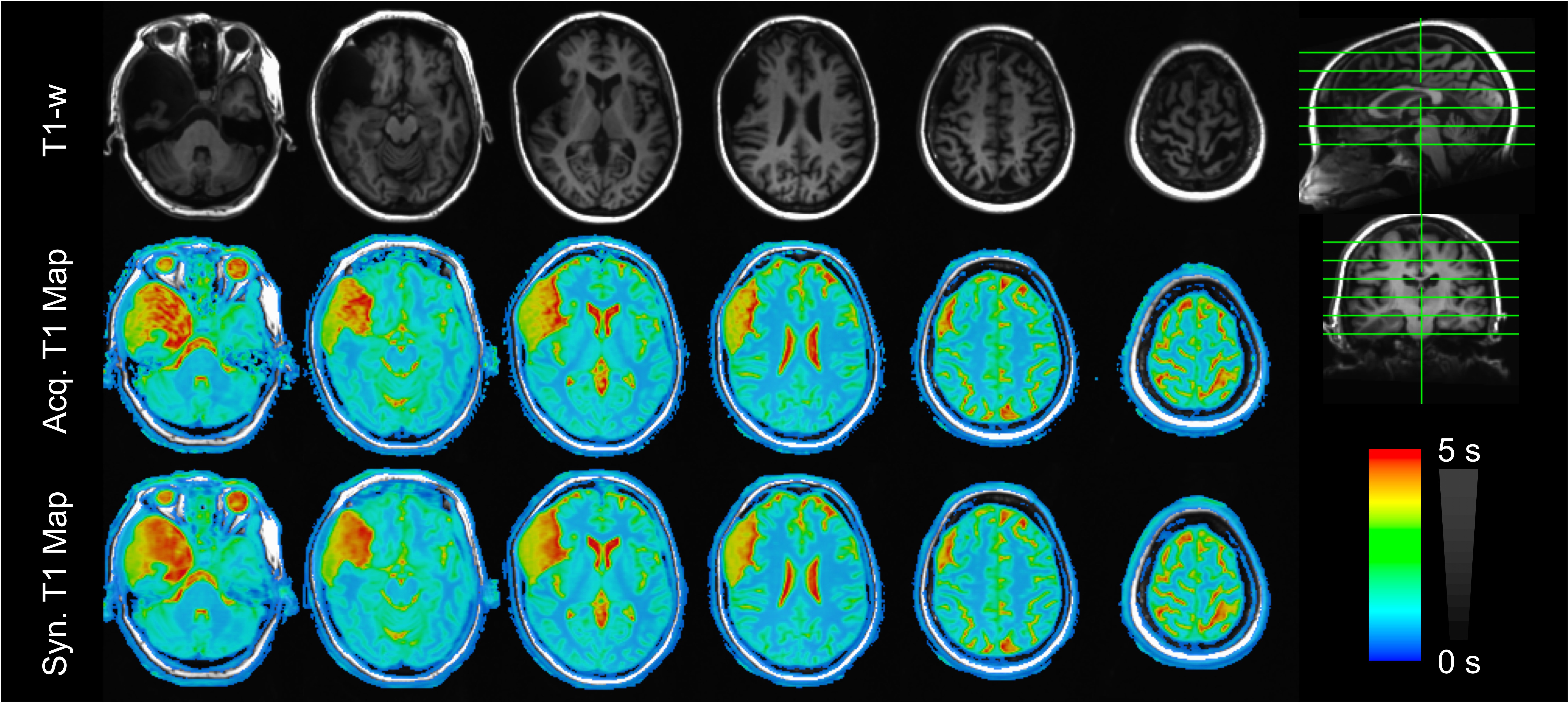
As shown in Figures 2 and 3, T1 values synthesized from the deep learning approach were very close to the acquired values for all tissue compartments. Error was -0.74%, -2.23%, and -2.78% for CSF, GM, and WM, respectively. P-values for a Wilcoxon signed rank test comparing the synthetic to the acquired approach were 0.55, 0.04, 0.02 for CSF, GM, and WM, respectively. Figure 4 demonstrates T1 synthesis in a subject (#1) with a normal appearing brain and Figure 5 depicts results in a subject (#8) with an abnormal brain. The synthetic approach also performs well for both subjects.Discussion/Conclusion
Traditional T1 mapping methods such as inversion recovery rely on acquiring images where only one parameter of interest is varied to enable the use of a simple signal model at the cost of very long scan times. Accelerated methods such as variable flip angle (VFA) enable rapid acquisitions with volumetric 3D coverage, but require sophisticated signal models, and are more sensitive to additional effects such as B1, magnetization transfer, and improper spoiling [1]. The potential use of deep learning to enable quantitative imaging directly from an acquired T1-weighted image is a provocative approach with promising capability, as demonstrated herein.
The demonstrated deep learning approach is able to accurately estimate T1 in the brain with less than 3% error compared to a VFA approach. The ability to convert acquired T1-weighted images with arbitrary, non-quantitative pixel values into quantitative results, is expected to have significant potential in enabling quantitative comparisons between research studies (including retrospective analysis of previous data), scanner types, and enabling quantitative comparisons from existing clinically-feasible imaging protocols. Future work will refine the method, in particular in relation to the global scaling effects between input T1-weighted images, which was not accounted for herein. Furthermore, additional study is necessary to determine the sensitivity of this approach in detecting subtle abnormalities in T1 values in a disease population.
Acknowledgements
No acknowledgement found.References
[1] Sager et al. J Geriatr Psychiatry Neurol. 2005 Dec;18(4):245-9. PMID: 16306248
[2] Hurley et al. Magn Reson Med. 2012 Jul; 68(1): 54–64. PMID:22139819.
[3] Ronneberger et al. 2015. arXiv:1505.04597.
[4] https://www.fmrib.ox.ac.uk/fsl
[5] https://keras.io/
Figures