2738
Reconstruction of MR images by combining k-spaces of multi-contrast MR data through deep learning1Department of Bio and Brain Engineering, KAIST, Daejeon, Republic of Korea, 2Department of Radiology, Seoul National University Hospital, Seoul, Republic of Korea
Synopsis
We propose a new deep neural network (Y-net) that can utilize images acquired with a different MR contrast for reconstruction of down-sampled images. K-space center of down-sampled T2-weighted images and k-space edge of full-sampled T1-weighted images were combined through one Y-net, and desired high-resolution T2-weighted images were generated by another Y-net. The proposed network not only improved spatial resolution but also suppressed ringing artifacts caused by the down‑sampling at the k-space center. The developed technique potentially enables to accelerate the multi-contrast MR imaging in routine clinical studies.
Introduction
There have been many attempts to reconstruct down-sampled MR images for reducing MRI scan time such as compressed sensing and parallel imaging 1, 2. Recently, deep learning has been introduced as a powerful tool for image reconstruction. Among many deep learning network, U-net convolutional network combined with residual learning scheme is regarded as a state‑of‑the‑art technique for image processing because of fast convergence 3, 4. However, it is still difficult to reduce MR scan time dramatically using the convolutional network, because the reconstructed image becomes blurred or visually different from the fully sampled image, which is more severe at higher acceleration factors. Normally, more than two different contrast images are acquired in routine MRI examinations for the accurate diagnosis. It would be beneficial for reconstruction of down-sampled MR images to utilize high-resolution images acquired in another contrast. For instance, down sampled T2-weighted image can be reconstructed better using the information of high-resolution T1-weighted image. In this study, we introduce a new deep residual network, Y-net, designed to take information of another contrast image as input for reconstruction of a down-sampled MR image. The performance of the proposed network was verified using T1- and T2-weighted images. In addition, we compared the reconstruction quality of Y-net with that of conventional U-net through quantitative analysis.Methods
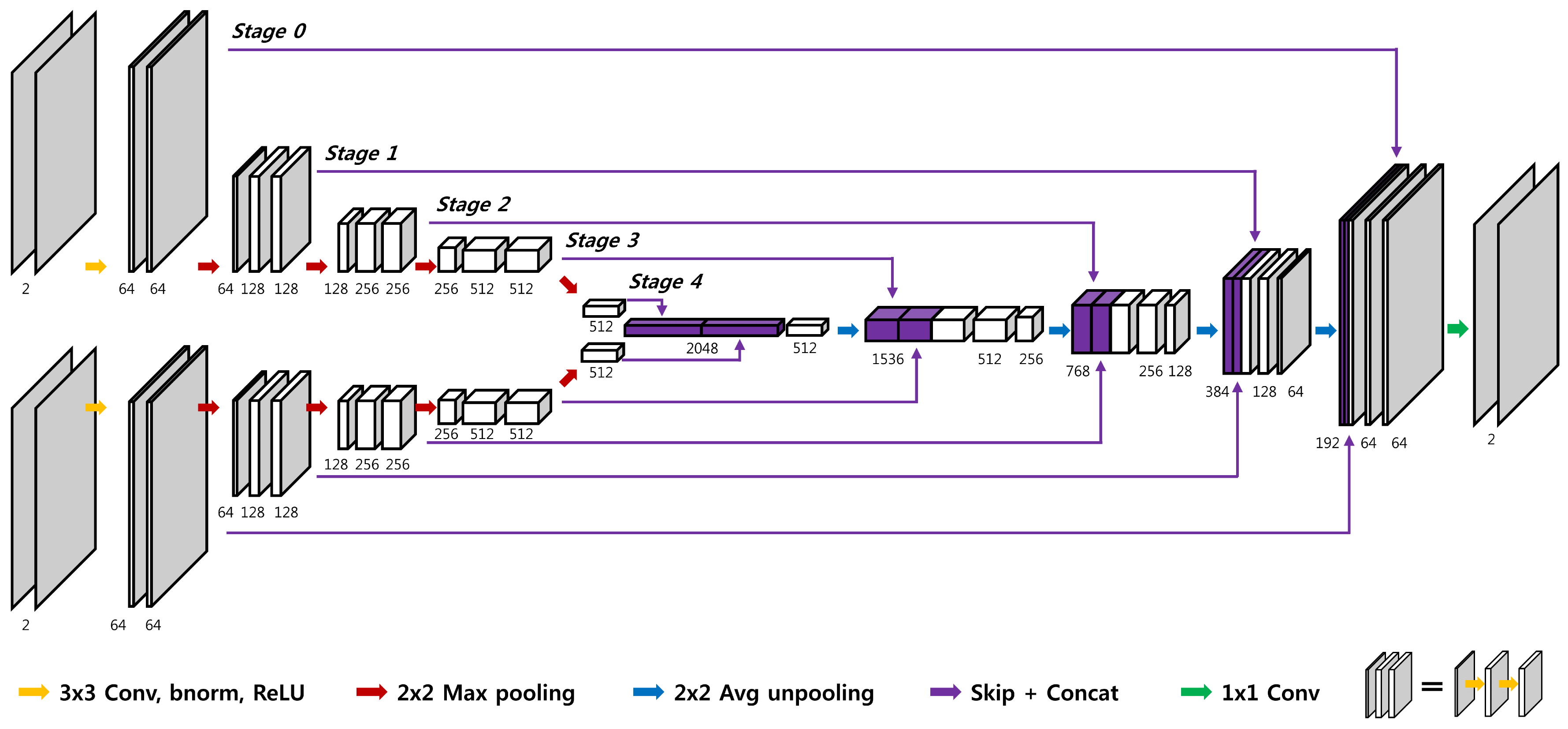
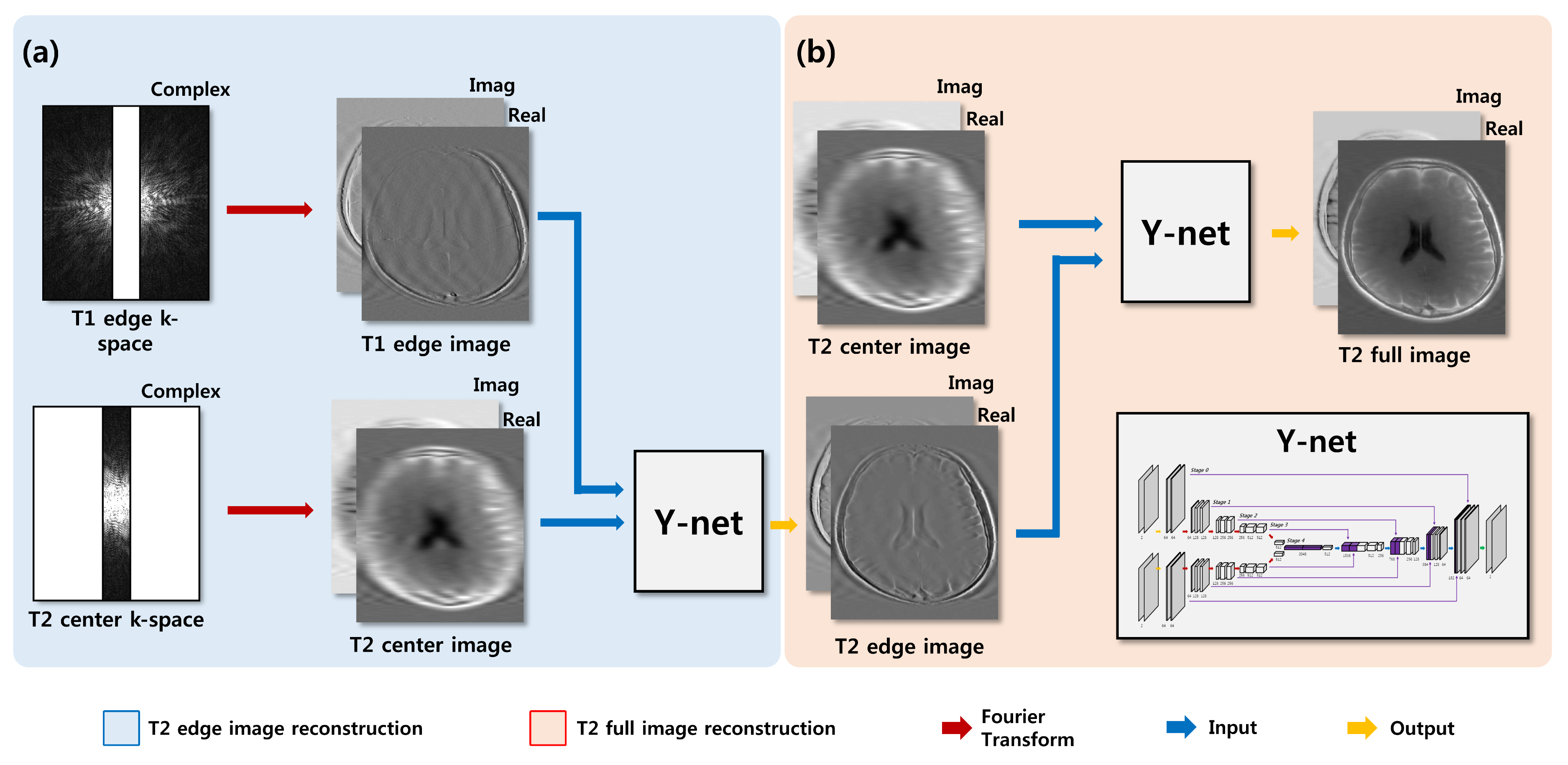
All data were acquired using 3T Siemens Trio scanner with a 12-channel head coil on total 15 normal subjects (10 males and 5 females). Spin echo T1-weighted images were acquired with TR/TE = 500ms/9.8ms and scan time = 2min 2s, while fast spin echo T2-weighted images were acquired with TR/TE = 3700ms/103ms and scan time=1min 56s. Common scan parameters for both were FOV = 220X165mm2, matrix = 320X240, and number of slices = 15. To reduce the computation time, k-space data from all the receiver channels were compressed to one channel data using a coil compression algorithm 5. In order to minimize information loss, complex images were used instead of conventional magnitude images. For network training, k-space center of T2-weighted images and k-space edge of T1-weighted images were retrospectively down sampled with an acceleration factor of 4, 8, and 16. In the proposed Y-net, U-net combined with residual learning scheme was modified to accept k-space edge information of T1-weighted image as another input (Fig. 1). The proposed residual Y-network consisted of convolutional layer, batch normalization, rectified linear unit and contracting/extracting path connection. The learning rate was set from 10-3 to 10-5. To enhance reconstruction quality, Y-net was trained to reconstruct T2 edge images first from combined inputs of T2 center images and T1 edge images (Fig. 2a). Another Y-net was trained afterward to reconstruct T2 full images from the output of the first Y-net and the T2 center images (Fig. 2b). To compare the result from the second Y-net, down‑sampled T2‑weighted images were also reconstructed using U-net, which used only T2 center images as an input. 1170 images from 13 subjects (out of 15 subjects) were used for training the network, and 90 images from one remaining subject were used for the validation and another 90 images from the other remaining subject were used for the test. The structural similarity (SSIM) and normalized means square error (NMSE) were measured between the reconstructed image and the fully‑sampled image to evaluate the reconstruction quality of each network quantitatively.Results and Discussion
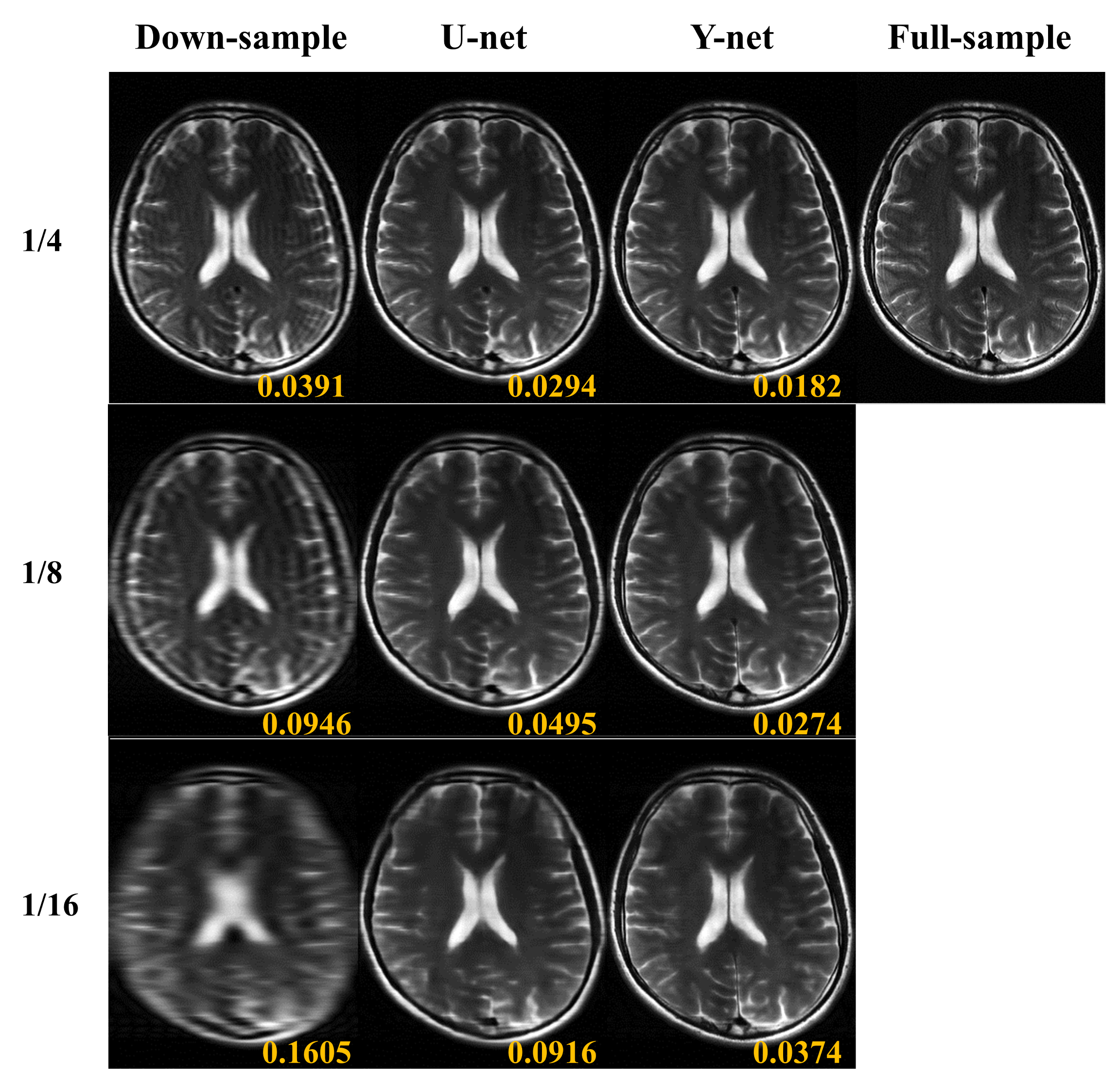
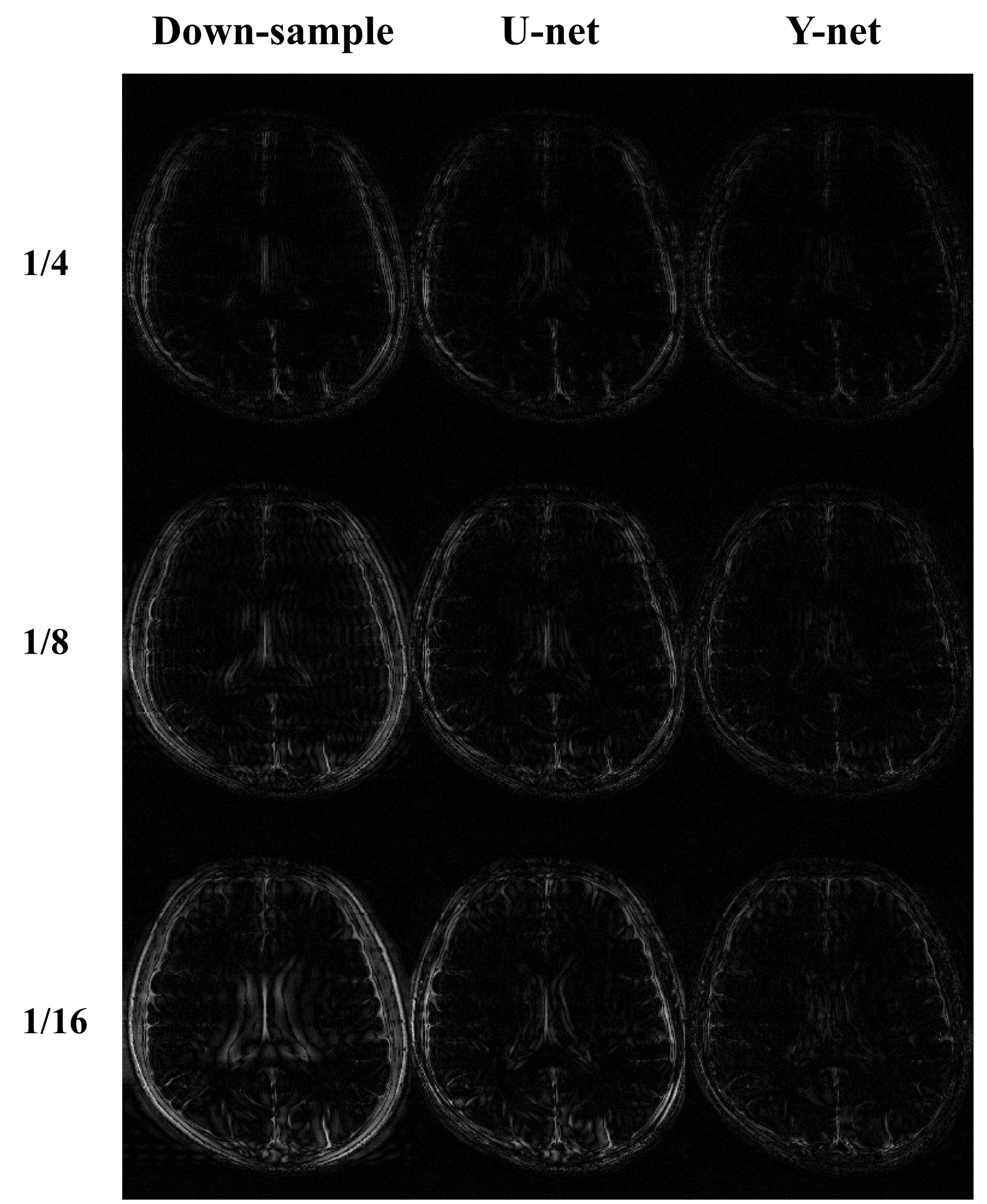
As shown in Figs. 3 and Fig. 4, the detailed tissue information in the reconstructed image from Y-net was depicted better than that from U-net. Furthermore, Gibbs artifacts caused by down sampling were suppressed better for Y-net. NMSE of reconstructed images from U-net and Y-net were 0.054±0.027 and 0.029±0.001 respectively. In addition, SSIM of the reconstructed images from U-net and Y-net were 0.747±0.081 and 0.804±0.045 respectively. These quantitative analyses indicate that reconstructed images from Y-net were closer to the fully‑sampled images than those from U-net, which was consistent with the visual observation. Combining a k-space center portion of one MR contrast and a k-space edge portion of another MR contrast would generate ringing artifacts, because of discontinuity between the two k-space portions. Moreover, motion can be induced between the two scans of different contrasts. We used two Y-nets to resolve these issues: one for combining two k-space portions and the other for generating the desired output. Deep learning could overcome the k-space discontinuity problem easily, as demonstrated in this study.Conclusion
The proposed deep neural network, Y-net, greatly improve the image quality degraded by down sampling. This technique can greatly reduce total scan time for multi-contrast MR imaging in routine clinical studies.Acknowledgements
No acknowledgement found.References
1. Lustig M, Donoho D, Pauly JM. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magnetic Resonance in Medicine 2007;58(6):1182-1195.
2. Griswold MA, Jakob PM, Heidemann RM, Nittka M, Jellus V, Wang J, Kiefer B, Haase A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magnetic Resonance in Medicine 2002;47(6):1202-1210.
3. Lee, Dongwook, Jaejun Yoo, and Jong Chul Ye. "Deep residual learning for compressed sensing MRI." Biomedical Imaging (ISBI 2017), 2017 IEEE 14th International Symposium on. IEEE, 2017. APA
4. Han, Yo Seob, Jaejun Yoo, and Jong Chul Ye. "Deep Learning with Domain Adaptation for Accelerated Projection Reconstruction MR." arXiv preprint arXiv:1703.01135 (2017).
5. Zhang T, Pauly JM, Vasanawala SS, Lustig M. Coil compression for accelerated imaging with Cartesian sampling. Magnetic Resonance in Medicine 2013;69(2):571-582.
Figures