2737
Skull Segmentation for MR-Only Radiotherapy Simulation using An Unsupervised-Learning Multi-Sequence Analysis Framework1Medical Physics & Research Department, Hong Kong Sanatorium & Hospital, Hong Kong Island, Hong Kong
Synopsis
MR-only simulation is increasingly more popular because of superior soft-tissue contrast and radiation dose-free for conventional and adaptive radiotherapy, as compared to CT simulation. Identifying bones is crucial towards successful MR-only simulation, particularly in cranial and head-and-neck regions where radio-sensitive soft-tissues densely present. This abstract proposed a framework exhibiting self-learning compatibility to capture case-specific information to perform skull segmentation. Without manual input and training information, the proposed framework utilized a clustering technique to collectively analyze images from multiple MR sequences. Evaluated in eight volunteer cases, it was shown that the proposed unsupervised-learning framework well-suited MR-based skull segmentation.
Introduction
MR-only simulation is increasingly more popular because of superior soft-tissue contrast and no radiation dose compared to CT simulation for conventional and adaptive radiotherapy (RT). Owing to the lack of radiation-attenuation information, identifying bones is crucial for treatment planning and dosimetric calculation, particularly in cranial and head-and-neck regions where radio-sensitive tissues densely present. The major challenge is MR’s inefficacy to distinguish bone from other tissues. While some sequences focus on ultra-short echo-time (UTE) [1] or suppressing soft-tissue contrast [2], the cortical and trabecular bone in these sequences may have largely overlapping intensity ranges with air or other soft tissues.
This abstract proposed a framework exhibiting self-learning compatibility to capture statistics from images of multiple MR sequences. In the concerned application – skull segmentation, three-point DIXON and a soft tissue contrast-suppressing gradient-echo sequence (BlackBone [2]) were chosen. This framework utilized a labeled CT template which was registered to the MR images to hint tissue class intensity distributions among images without manual input or training information.
Method
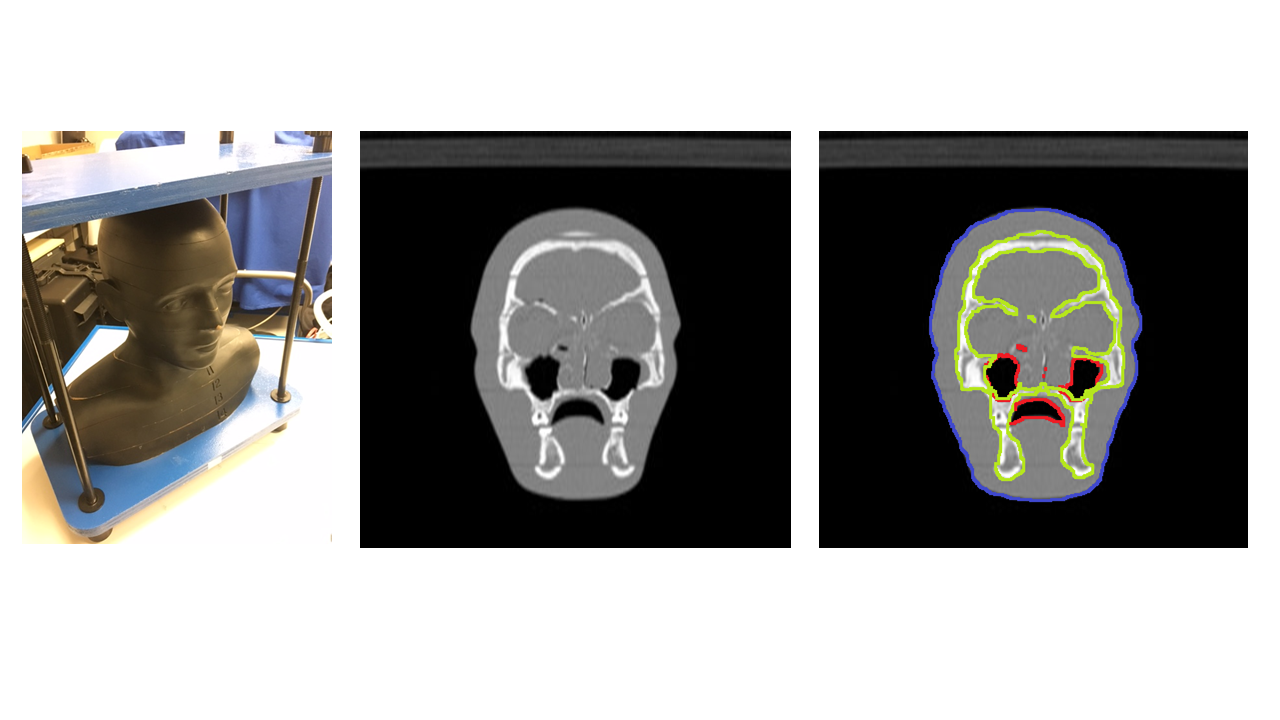
Head and neck regions of eight healthy volunteers were scanned on a dedicated 1.5T wide-bore MR simulator (Magnetom-Aera, Siemens Healthcare, Germany) using two sequences – DIXON and BlackBone (Figure 1). One CT-template was acquired using CT-Simulator (Definition-Edge, Siemens Healthcare, Germany) from RANDO Phantom (Figure 2), and was manually annotated to background, bone, air-cavity and soft-tissue.
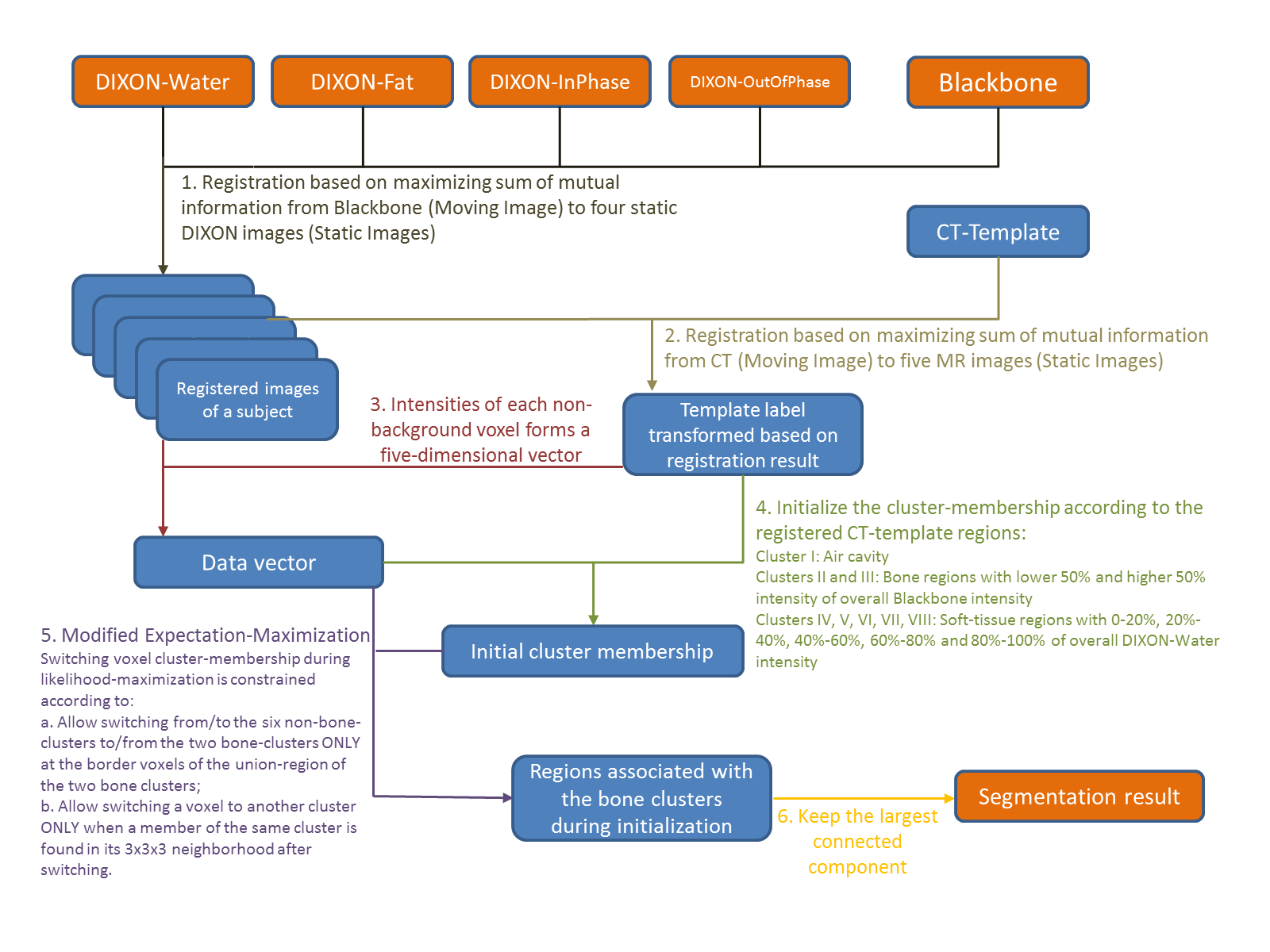
A matlab program (Figure 3) was developed to co-register the CT-template, BlackBone and four DIXON images of each volunteer, and analyzed the registered images. The registration [3] was based on maximizing the total mutual information of CT-BlackBone, CT to each of the four DIXON images and BlackBone to each of the four DIXON. The intensity values from Blackbone and DIXON images at each position formed a 5-dimensional data point. These points were fed to 8-Mixture-of-Gaussian distribution using Expectation-Maximization (EM) algorithm, which was modified to prohibit isolated regions from appearing during likelihood-maximization (see Step-5, Figure 3). It was initialized according to the labels provided by the registered CT-template to hint the EM algorithm to separate bone from other regions at the beginning of likelihood-maximization. The clustering result returned a voxel-wise region class classification, of which our primary interest was the bone tissue.
Result and Discussion
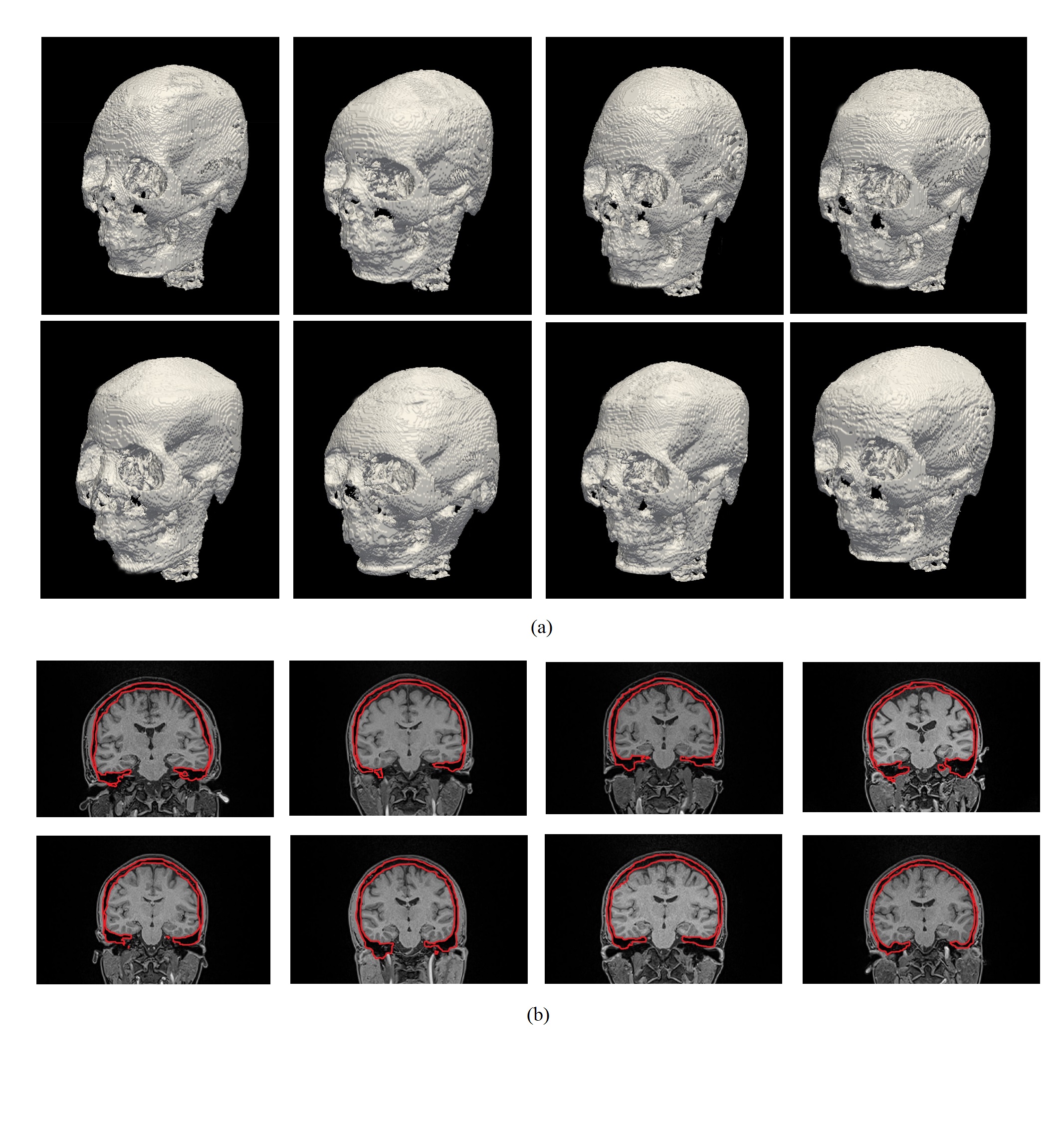
The segmentation results were depicted in Figure 4a. It is shown that the proposed framework was able to delineate the skull solely based on MR images without case-specific manual input and training dataset. A coronal slice of each case in Figure 4a was shown in Figure 4b. It is observed that the cortical and trabecular bones were both successfully included in the delineated bone regions, while air-cavity was separated from the bone, showing promising segmentation results.
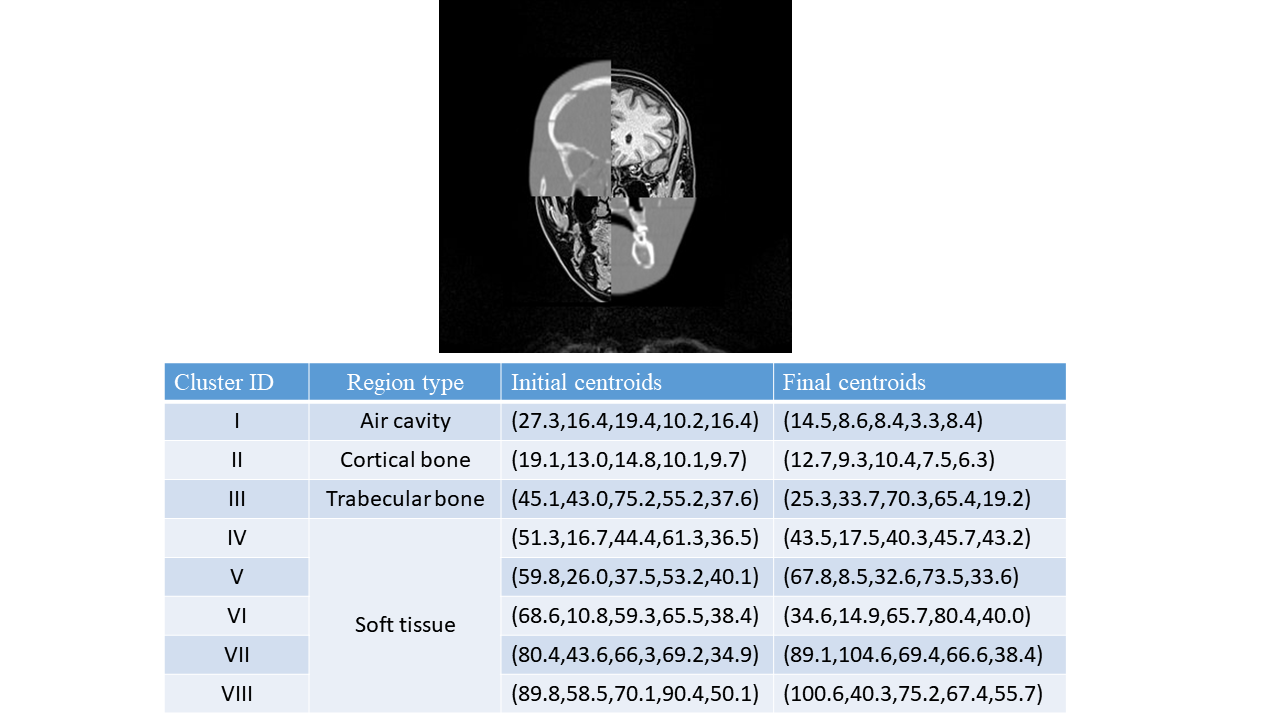
Figure 5a demonstrated a registered CT-template example. It is emphasized that CT-template registration results merely provided the parameter initialization and relative region positions for the EM algorithm. While a moderate initialization was helpful, the possibly inaccurate information in initialization was corrected upon the convergence of the EM algorithm.
Figure 5b showed centroids (mean) of all Gaussian mixtures of the case in Figure 5a. For all segmentation results, bone tissue always corresponded to two centroids associated with trabecular and cortical bone, and there was another low-valued centroid associated with air-cavity. Other centroids might represent mixtures of various soft tissues such as grey matter, white matter, vessel and fat.
Conclusion
A self-learning framework was developed and demonstrated to be able to segment skulls in eight cases. Based on unsupervised learning, this framework required no prior training input. From a mathematical perspective, this self-learning mechanism relied on the region-distinguishability in the data space formed by the images and the relative spatial region information hinted by the initialization step. From an imaging perspective, these images highlighted different tissue types and thus synergized well by the proposed framework. Therefore, the proposed method can be improved by including more multi-contrast or post-processed images, if they offer complementary information. UTE [1] images are good candidates, especially on identifying air-bone boundaries, if they can be reliably registered to other images.
Volunteers’ CT scans will be obtained to quantitatively evaluate the segmentation results. Furthermore, generating synthetic-CT images to compare against the conventional-CT images would be a rewarding direction. While designed for RT applications, the proposed method could compute proton beam attenuation for proton-therapy. Propagating prior information through self-learning (unsupervised) techniques to collectively analyze multiple MR images will be applicable and beneficial to MR-only simulation for cranial, head-and-neck treatments, and also potentially useful for image enhancement and other MR applications.
Acknowledgements
No acknowledgement found.References
[1] S.-H. Hsu, Y. Cao, T.S. Lawrence, C. Tsien, M. Feng, D.M. Grodzki, J.M. Balter, “Quantitative characterizations of ultrashot echo (UTE) images for supporting air-bone separation in the head”, Phys. Med. Bio. 2015.
[2] K.A. Eley, A.G. Mclntyre, S.R. Watt-Smith, S.J. Golding “Black bone MRI: a partial flip angle technique for radiation reduction in craniofacial image”, Br J Radiol. 2012.
[3] J. Ashburner “A fast diffeomorphic image registration algorithm”, NeuroImage 2007.
Figures
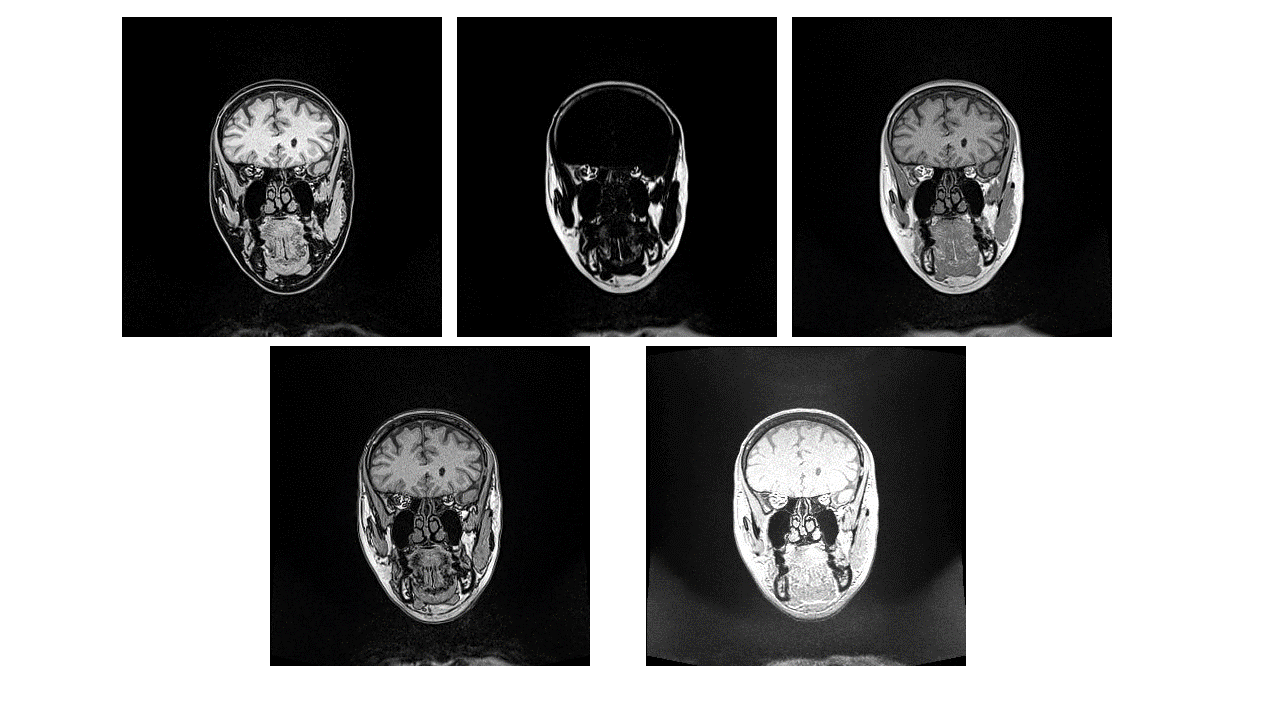
Figure 1. Top row: The DIXON-Water, -Fat and -InPhase images. Bottom row: The DIXON-OutOfPhase and Blackbone images. DIXON was acquired using TR/TE:7.37ms/2.39ms, Flip-Angle:12o, 1mmx1mmx1mm voxel, FOV:320mm. Blackbone was acquired using TR/TE:8.6ms/4.2ms, Flip-Angle:5o, 1mmx1mmx1mm voxel, FOV:320mm. Subjects were positioned at the virtual isocenter with glabella aligning to the external laser in both acquisitions.